LLM-as-a-Judge: How Do You Know If Your AI Is Actually Good?

For a long time, the answer to this question was rooted in either paying humans to review outputs or relying on automated metrics that barely captured what humans actually care about. Now there’s a middle ground that’s getting a lot of traction: using one LLM to evaluate another (LLM-as-a-judge).
This approach, usually called LLM as a Judge, is becoming a core part of how teams test and improve AI systems. Instead of manually reviewing thousands of responses, you let a model act like a reviewer and score outputs based on whatever matters to you, whether that’s accuracy, tone, helpfulness, formatting, or safety.
At PromptLayer, we’ve seen this shift firsthand. As more teams started building production AI systems, evaluation quickly became one of the biggest bottlenecks. Manual review doesn’t scale, and traditional metrics rarely tell you whether an output is actually good.
But like any evaluation method, LLM judges come with trade-offs that are easy to miss. They’re incredibly useful, but they also inherit many of the same quirks, biases, and failure modes as the models they’re evaluating. To understand where they perform best, and where they break down, it helps to look at how these systems work in practice and why so many teams are starting to rely on them in the first place.
What “LLM-as-a-Judge” actually means
The idea itself is pretty simple. You take a generated response and feed it into another model alongside instructions for how it should be evaluated.
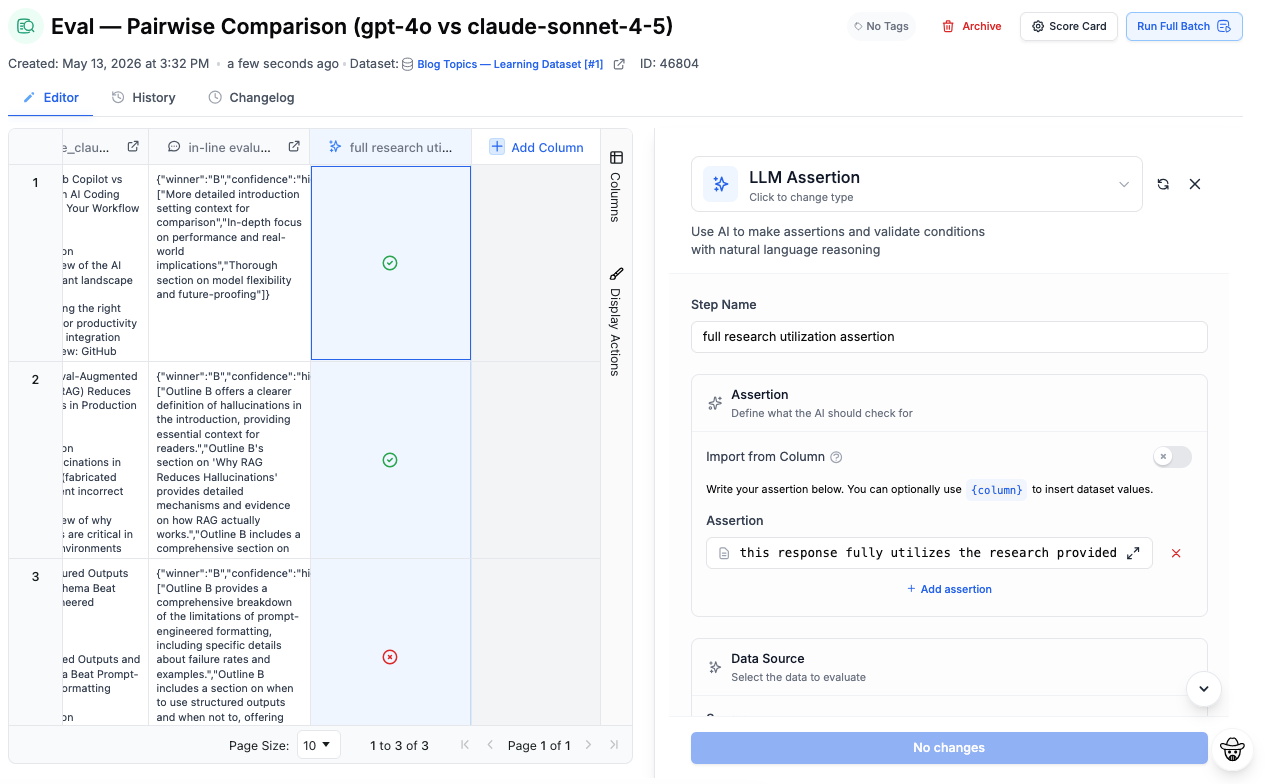
You might ask the judge model to rate a response from 1 to 5 based on factual accuracy and conciseness, or compare two outputs and decide which one better answers the user’s question, or maybe compare how the given input was utilized in formulating the output. The evaluator then returns a score, ranking, explanation, or structured feedback.
That might sound obvious now, but it’s a meaningful shift from older evaluation methods. Traditional metrics like BLEU and ROUGE mostly check whether generated text overlaps with a reference answer. That works for narrow tasks, but language is messy. A response can use totally different wording and still be correct, or closely match a reference answer while still being misleading or low quality. Those metrics are fast, but they don’t really understand meaning.
Human review is still the gold standard, but it’s expensive, slow, and difficult to scale once you’re reviewing thousands of outputs across multiple prompts and models.
That’s where LLM judges become useful. They’re not perfect, but they’re often good enough to automate large parts of the evaluation process while still preserving some level of semantic understanding.
The benefits of LLM-as-a-judge
The biggest benefit is speed. If you’re iterating on prompts, fast feedback loops matter a lot. Imagine testing two versions of a summarization prompt and trying to figure out which one produces better summaries. Instead of manually reviewing hundreds of outputs, you can run both through a judge model with a rubric focused on things like factual consistency, completeness, readability, and brevity.
Suddenly, prompt iteration goes from something that takes days to something that takes minutes. That’s a big reason this approach has become popular in tools like OpenAI Evals, LangSmith, and PromptLayer Evaluations.
The LLM-as-a-judge approach also makes regression testing much easier. When you change prompts or swap models, you can quickly check whether quality improved, stayed flat, or quietly got worse in a consistent and reliable manner.
These are a few of the strongest reasons for adopting LLM-as-a-judge into your workflow. However, there are concerns that can come up as well.
Evaluation gets harder as AI systems get more complex
One thing teams discover pretty quickly is that evaluation complexity grows alongside model capability.
A simple chatbot might only need basic correctness checks. But once you’re working with retrieval pipelines, agents, tool calling, structured outputs, or multi-step reasoning, evaluation becomes much harder. You’re no longer asking “did the model answer correctly”, but also if it used the right context, called the right tools, followed formatting requirements, or regressed after a prompt update.
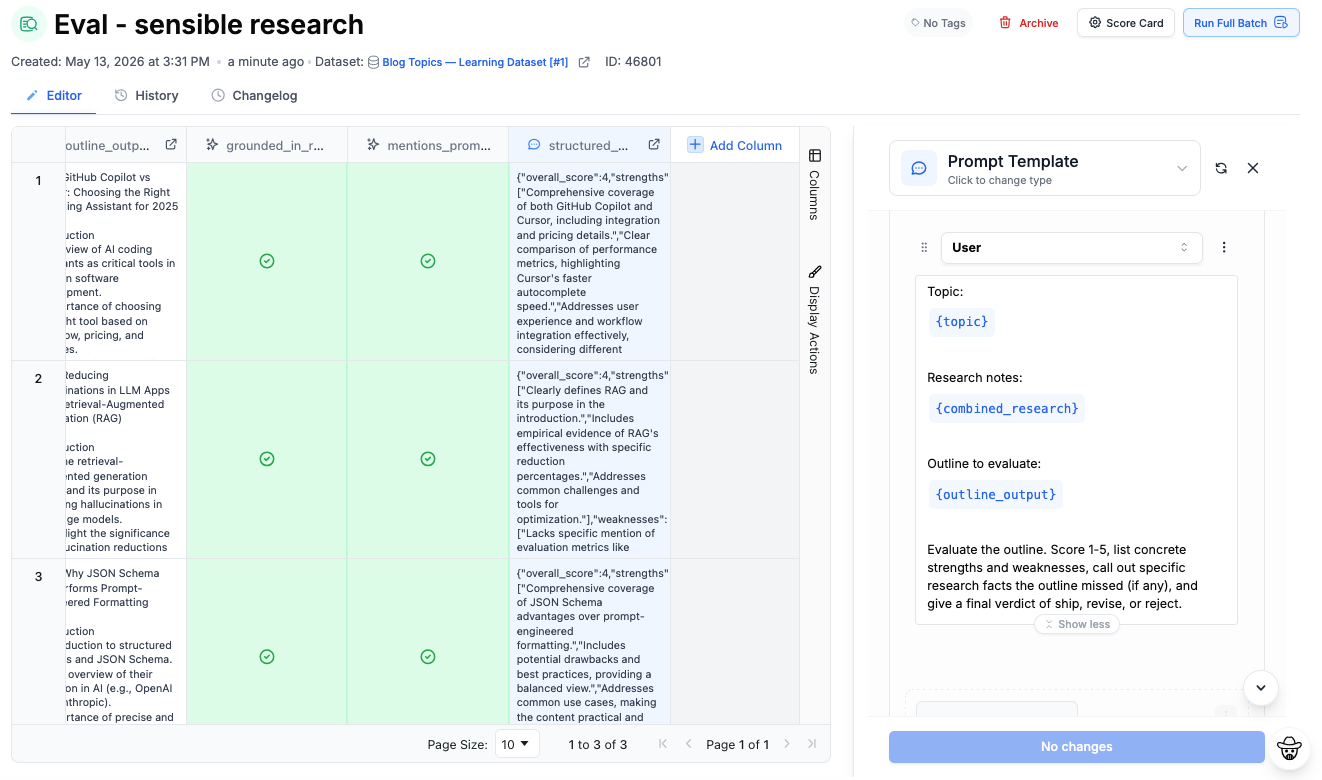
This is where structured evaluation systems become important. Once you’re working with complex AI workflows, evaluation stops being something you do occasionally and starts becoming part of the product itself. Strong evaluation systems usually combine multiple signals together, including heuristic checks, LLM judges, human review, and application-specific scoring logic. No single metric is reliable enough on its own, especially once you’re evaluating nuanced behaviors like reasoning quality, formatting, tool usage, or retrieval accuracy.
The important realization is that evaluation isn’t a one-time task. Once AI becomes part of a product, evaluation turns into ongoing infrastructure. That’s a big reason we made evaluations a first-class feature at PromptLayer. With PromptLayer Evaluations, teams can run both human and model-based evaluators against datasets at scale, compare prompt versions over time, and automatically catch regressions before they hit production.
Biases and assumptions
LLM judges have biases just like any other model. They often prefer longer answers even when they aren’t better. They can be inconsistent between runs, overly confident in weak evaluations, or surprisingly sensitive to phrasing.
Designing good evaluation prompts can be just as important as producing good prompts to begin with. For example, vague evaluation prompts usually produce vague results.
If your rubric is just “is this response good?”, the evaluations are probably going to be noisy and unreliable. Strong evaluation systems usually depend on detailed rubrics with explicit instructions about what should and shouldn’t be rewarded. In practice, building a good evaluator often turns into its own prompt engineering problem.
Where this gets really interesting
LLM-as-a-Judge can be used even outside of prompt testing. In the world of automation, it’s increasingly becoming part of the infrastructure for how AI systems improve themselves. One example of this is Reinforcement Learning from AI Feedback (RLAIF), where models generate feedback signals that help train other models. There are also more practical applications, like catching hallucinations before responses reach users, checking whether outputs follow brand guidelines, routing risky answers to humans, or monitoring quality over time.
The important thing is remembering that the judge is still just another model.
So should you trust it?
The teams getting the most value from LLM evaluation tend to treat it as one signal among several, not as an unquestionable source of truth. The sweet spot is often using automated evaluation for scale while keeping humans involved for calibration and edge cases.
As models improve, the judges improve too. The bigger question now is less “does this work?” and more “where should humans stay in the loop?”
LLM-as-a-Judge FAQs
What are LLM evals?
LLM evaluations (evals, for short) are systems for testing and measuring the quality of AI outputs. Teams use them to evaluate things like accuracy, reasoning quality, formatting, hallucinations, tone, and instruction-following. Evaluations can involve human reviewers, automated checks, LLM judges, or a combination of all three.
When should humans still stay in the loop?
Usually for high-stakes or subjective evaluations. Things like legal accuracy, medical outputs, nuanced brand voice, edge cases, and safety reviews still benefit heavily from human oversight. The best evaluation systems usually combine automated judging with human review rather than trying to fully replace people.
What’s the biggest mistake teams make with LLM evaluations?
Using vague evaluation criteria. If your evaluator prompt is basically “is this response good?”, the results tend to be noisy and inconsistent. Strong evaluation workflows depend on clear rubrics, representative datasets, and ongoing testing over time.
How do teams actually run evaluations at scale?
Most teams move toward structured evaluation pipelines once they reach production. With PromptLayer Evaluations, teams can run both human and model-based evaluators against datasets, compare prompt versions side-by-side, automate regression testing, and monitor prompt quality over time.
How do I choose the right evaluation platform?
It depends on your workflow. Some teams only need lightweight prompt testing, while others need full production evaluation pipelines with versioning, regression testing, human review, observability, and deployment workflows. Platforms like PromptLayer are designed to bring those pieces together so teams can iterate on prompts, evaluate quality, and monitor behavior from a single workflow.