OpenAI RL Fine-Tuning: What you need to know and when you should use it
OpenAI dropped Reinforcement Fine-Tuning (RFT) in late 2024, bringing academic RL techniques to everyday developers—one AI researcher called it "RL for the masses." Unlike traditional fine-tuning where models memorize examples, RFT trains models through trial-and-error with rewards, creating a breakthrough moment for developers trying to squeeze better reasoning out of their AI systems.
For prompt engineers who've hit the ceiling with clever prompting tricks, RFT opens a path to optimize models for complex reasoning tasks that standard prompting simply can't solve. But here's the catch: it's not a universal solution, and it can cost 100-700x more than regular fine-tuning. Let's dive into when it makes sense and how to use it effectively.
What is RFT and How is it Different?
Traditional Supervised Fine-Tuning (SFT) works like a diligent student memorizing flashcards—you show the model input-output pairs, and it learns to imitate those exact responses. This approach has served us well for style transfer and knowledge injection, but it stumbles when facing novel problems that require actual reasoning. This is the method OpenAI's original fine-tuning used.
RFT flips the script entirely. Instead of spoon-feeding answers, the model generates its own attempts during training and learns from feedback scores (reward signals). Think of it as learning to play chess by actually playing games and getting scored, rather than memorizing famous matches.
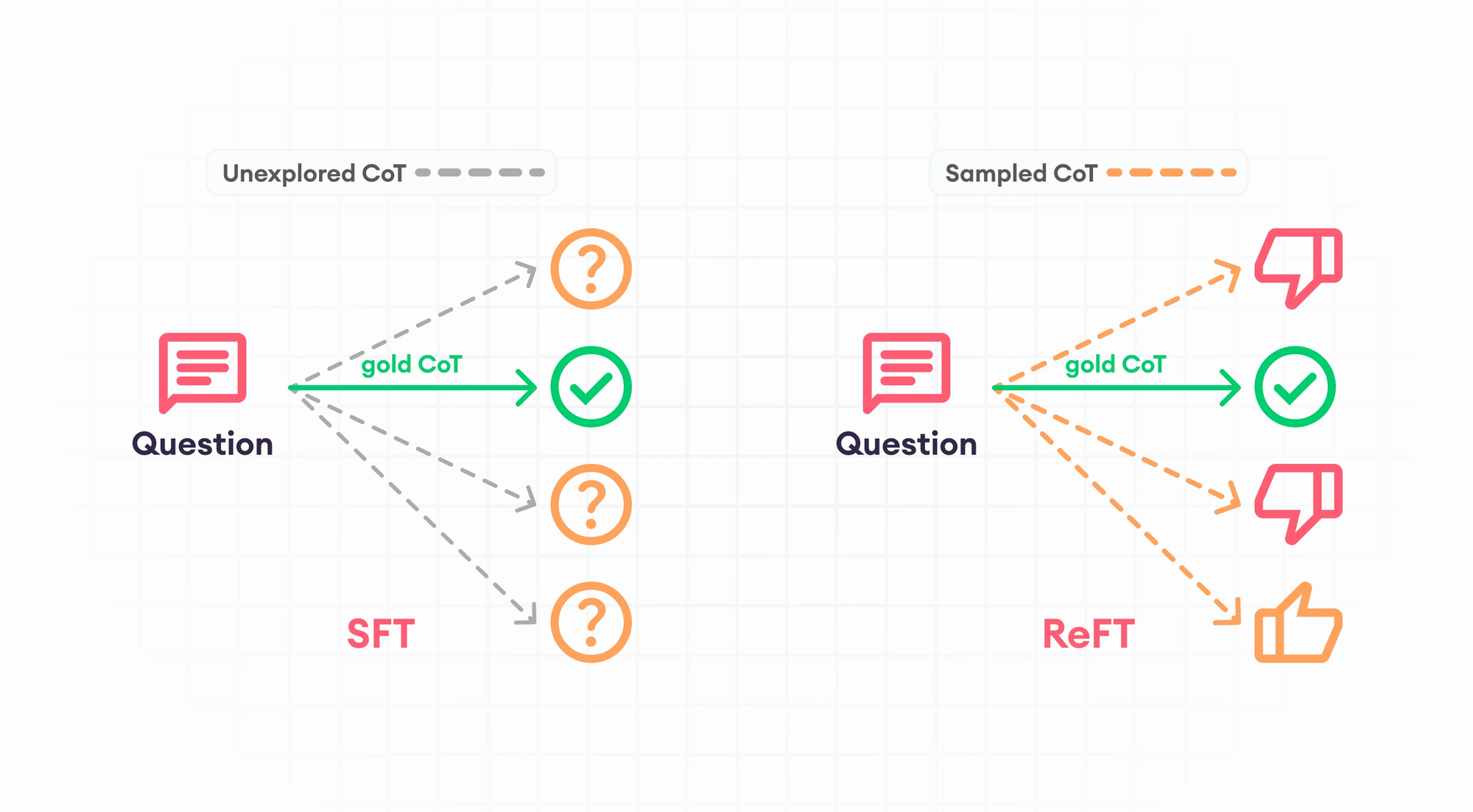
The key mechanism is an iterative feedback loop:
- Model receives a prompt and generates an answer
- A "grader" function scores how good that answer is
- Model adjusts its approach to maximize the reward
- Process repeats thousands of times
This fundamental difference—learning to find correct solutions versus memorizing correct answers—makes RFT particularly powerful for tasks where reasoning matters more than recall.
When You Should Use RFT (And When You Shouldn't)
RFT shines brightest in specific scenarios. Before diving into the technical setup, you need to assess whether your use case fits the RFT sweet spot.
Perfect for RFT:
- Tasks with verifiable, correct answers: Math problems, code generation, medical Q&A, legal analysis
- Complex reasoning where the model has some capability but needs refinement: The base model can attempt the task but makes frequent mistakes
- Limited labeled data but clear success criteria: You have dozens to hundreds of examples, not thousands, but can automatically verify correctness
Skip RFT for:
- Subjective or style-based tasks: Writing with a certain tone, creative content generation (use DPO instead)
- Tasks where the model has zero existing skill: RFT can only reinforce behaviors the model occasionally does correctly
- No automatic way to grade outputs: If you need human judgment for every answer, RFT becomes impractical
The cost consideration is crucial. RFT can cost around $100/hour on o4-mini, making it 100-700x more expensive than standard fine-tuning.
The Heart of RFT: Building Your Grader
The grader is the soul of your RFT system. It's the function that scores model outputs to provide the reward signal, essentially encoding what "good" looks like for your specific task.
There are four main grader types.
Simple string match: For exact answers
{
"type": "string_check",
"operation": "eq",
"input": "{{sample.output_text}}",
"reference": "{{item.reference_answer}}"
}
Similarity/partial credit: For fuzzy matching when phrasing varies
{
"type": "text_similarity",
"evaluation_metric": "fuzzy_match",
"pass_threshold": 0.8
}
Model-based graders: Using an LLM as judge for complex criteria
{
"type": "score_model",
"model": "o4-mini-2025-04-16",
"input": [{"role": "user", "content": "Grade this response..."}]
}
Multi-grader setups: Combining multiple criteria with weighted scoring
Be aware... Poorly designed graders lead to reward hacking. If your grader only checks for keywords, the model might learn to spam those keywords while producing nonsense. OpenAI's documentation specifically warns about this pitfall—the model will ruthlessly exploit any loophole in your scoring system.
Always validate your grader thoroughly before training. Test it on sample outputs to ensure it truly rewards what you want and doesn't have exploitable weaknesses.
Setting Up RFT: The Practical Steps
Getting RFT running requires careful preparation, but the process is more straightforward than you might expect.
Data requirements: You need prompts paired with reference answers, formatted as JSONL:
{"messages":[{"role":"user","content":"What is 17 * 23?"}], "reference_answer":"391"}
The beauty of RFT is you can start with just dozens of examples. The model will iterate over them many times, exploring different approaches and learning from the rewards. This makes RFT viable even when you can't collect thousands of labeled examples.
Key configuration parameters:
reasoning_effort: Controls how much the model can "think" (low/medium/high)compute_multiplier: Balances exploration depth versus costeval_samples: Number of outputs to average for cleaner performance metricsn_epochs: RFT typically needs many more iterations than SFT
Model support: Currently focused on OpenAI's o-series reasoning models, particularly o4-mini. These models are specifically designed for complex reasoning tasks, making them ideal RFT candidates.
Monitoring during training: Watch the reward curves religiously. You'll see:
- Average reward climbing over time (both training and validation)
- Per-grader scores if using multi-component grading
- Signs of odd behavior that might indicate reward hacking
The platform saves intermediate checkpoints, particularly the top 3 reward-performing versions, so you can roll back if training goes awry.
Real-World Example: Medical QA Performance Boost
OpenAI's cookbook provides a compelling medical QA case study. The challenge: fine-tune a model to predict clinical outcomes from doctor-patient dialogue summaries—a task requiring both medical knowledge and reasoning ability.
The setup:
- Only 100 training examples and 100 validation examples
- Combined grader: exact-match for perfect answers + fuzzy similarity for close matches
- Base model: o4-mini with medium reasoning effort
- Training duration: 5 epochs with moderate compute multiplier
The results: The fine-tuned model achieved 5 percentage points higher accuracy than the base model—a significant improvement in the medical domain where every percentage point matters.
More interesting than the numbers were the qualitative changes. The model learned to:
- Use precise medical terminology instead of paraphrasing
- Self-check its reasoning before committing to an answer
- Structure responses more systematically
These behavioral shifts signal genuine improvement in reasoning capability, not just memorization of training examples.
What the Community is Learning
Real-world usage has revealed nuanced patterns about when RFT delivers value.
TensorZero's independent analysis found mixed but revealing results:
- Success story: Data extraction task improved dramatically with just 10 RFT examples (would have needed 100+ for comparable SFT results)
- Failure case: Customer service chatbot actually performed worse with RFT—the rigid reward structure hindered natural conversation flow
The emerging consensus: RFT works brilliantly for narrow, well-defined metrics but isn't a universal performance booster.
Recommended approach from practitioners:
- Start with a small-scale pilot (dozens of examples, minimal epochs)
- If you see promise, consider combining SFT → RFT pipeline (SFT for baseline capability, RFT for accuracy refinement)
- Calculate the break-even point where accuracy gains justify the 100x+ cost increase
The open-source community is actively working to replicate RFT techniques on non-OpenAI models, suggesting this approach will become more accessible and affordable over time.
Conclusion
RFT is a specialized power tool, not a magic wand. Use it when you have verifiable answers, a solid grader, and the cost justifies catching those last few percentage points of accuracy. The sweet spot: narrow technical domains (math, code, medical) where correctness isn't negotiable and you've already maxed out prompting and standard fine-tuning.
Three factors predict RFT success:
- Reliable grader: Can you automatically and accurately score outputs?
- Clear objective criteria: Is there a definitive right answer?
- Justifiable cost: Will the accuracy improvement deliver enough value?
For prompt engineers, consider RFT when you've exhausted prompt optimization and standard fine-tuning but still need better reasoning performance. It's particularly powerful for technical domains—math, code, medical, legal—where correctness trumps everything else.
The real story here isn't just about RFT—it's that reinforcement learning is no longer locked in academic labs. OpenAI handed everyday developers a technique that used to require PhD-level expertise, complete with automatic checkpointing and reward monitoring. As costs drop and the community shares what works (and what doesn't), RL-based optimization will become standard practice for production AI.


