Grok Code Fast 1: First Reactions
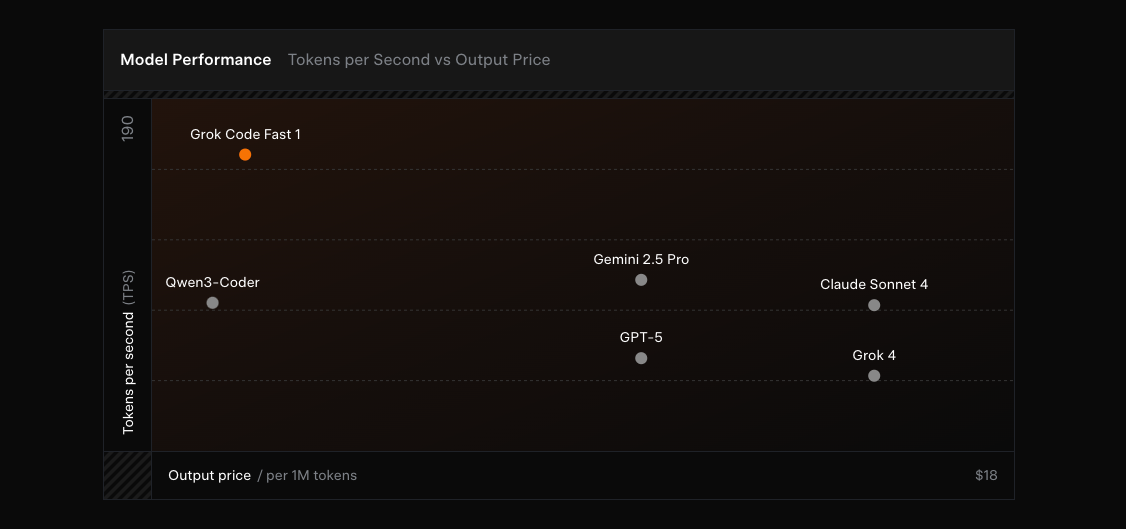
256k context and ~92 tokens/sec—xAI's coding model lands in GitHub Copilot public preview, aiming for speed at pennies per million tokens. This post covers what it is, why it's fast and cheap, best uses, where to try it, and what's next.
Why does this matter? Grok Code Fast 1 offers a "fast daily driver" that fits real developer workflows, and its low cost removes friction from AI-assisted coding. In the context of xAI's Grok lineage (Grok-1 open-sourced, 1.5 with 128k context, Grok 4 with tool use and real-time search), Code Fast 1—launched in late August 2025—represents the company's first specialized coding assistant.
What is Grok Code Fast 1?
Grok Code Fast 1 is xAI's first specialized coding assistant, built specifically for practical, agentic coding workflows. Unlike general-purpose language models, this one is designed to be nimble and responsive for day-to-day programming tasks.
The model represents a strategic shift for xAI into the developer tools arena. Following the progression of general-purpose Grok models (which power the Grok chatbot), this specialized variant leverages xAI's frontier AI research for coding-specific applications. The company built it from scratch using their expertise in large-scale model training, positioning it as a complement to—rather than a replacement for—more heavyweight coding models.
Core Specs That Make it "Fast"
The "Fast" in Grok Code Fast 1 isn't just marketing, it is actually legit. Let's break it down:
Context Window: With 256,000 tokens, the model can handle large repositories and long files coherently. This massive context allows developers to paste entire codebases or thousands of lines of logs without losing coherence. (Although this is not always a good idea.)
Throughput: At approximately 92 tokens per second, Grok Code Fast 1 delivers a snappy interactive loop. Users report that responses feel nearly instantaneous, fundamentally changing how they interact with AI coding tools.
Architecture: The 314B-parameter Mixture-of-Experts design enables specialized expert routing for both speed and capability. This MoE architecture means the model consists of multiple expert subnetworks, allowing it to remain fast while maintaining coding competence.
Agentic Tools + Reasoning: The model shows its "thinking trace" and supports function/tool calls. It can run shell commands like grep, edit files, and perform multi-step operations autonomously—not just generating code but executing coding workflows.
Pricing: At $0.20/M input tokens, $1.50/M output tokens, and $0.02/M for cached tokens, it's orders of magnitude cheaper than competitors. For context, some Claude models cost over $1,000 per million tokens. This aggressive pricing is part of xAI's strategy to gain market share.
API Limits: The generous limits of up to ~480 requests/minute and ~2M tokens/minute support high-throughput use cases, making it viable for integration into CI/CD pipelines or internal developer tools.
What It's Good At (And How to Use It)
Grok Code Fast 1 excels at several key use cases:
Rapid Prototyping: The model can scaffold simple apps and scripts in seconds. It shows particular strength in zero-to-one projects—building functional prototypes from scratch based on descriptions. Developers report using it to create basic web apps, CLI tools, and proof-of-concept implementations almost instantly.
Debugging and Code Analysis: The large context window shines here. Paste extensive logs, error messages, or multiple source files, and the model can locate bugs, identify inefficiencies, and suggest fixes. It effectively acts as a fast code reviewer, answering questions like "where is this function defined and how is it used?"
Front-end/UI Development: Grok Code Fast 1 handles visual elements well—generating quick SVGs, HTML/CSS components, and simple animations on the fly. These repetitive tasks benefit greatly from AI speed.
Language Coverage: The model demonstrates strong proficiency across the stack, particularly in TypeScript, Python, Java, C++, Rust, and Go. This versatility means developers in various domains can leverage it effectively.
Workflow Tip: Users have found success by breaking complex goals into small, fast iterations. As one developer noted: "Grok Code Fast is ridiculously fast... I actually had to change how I work." The key is feeding it focused, bite-sized tasks and rapidly iterating based on its outputs.
The model achieved ~70.8% accuracy on SWE-Bench, placing it among higher-tier coding models for problem-solving ability. While benchmarks don't capture full real-world performance, this indicates solid baseline competence.
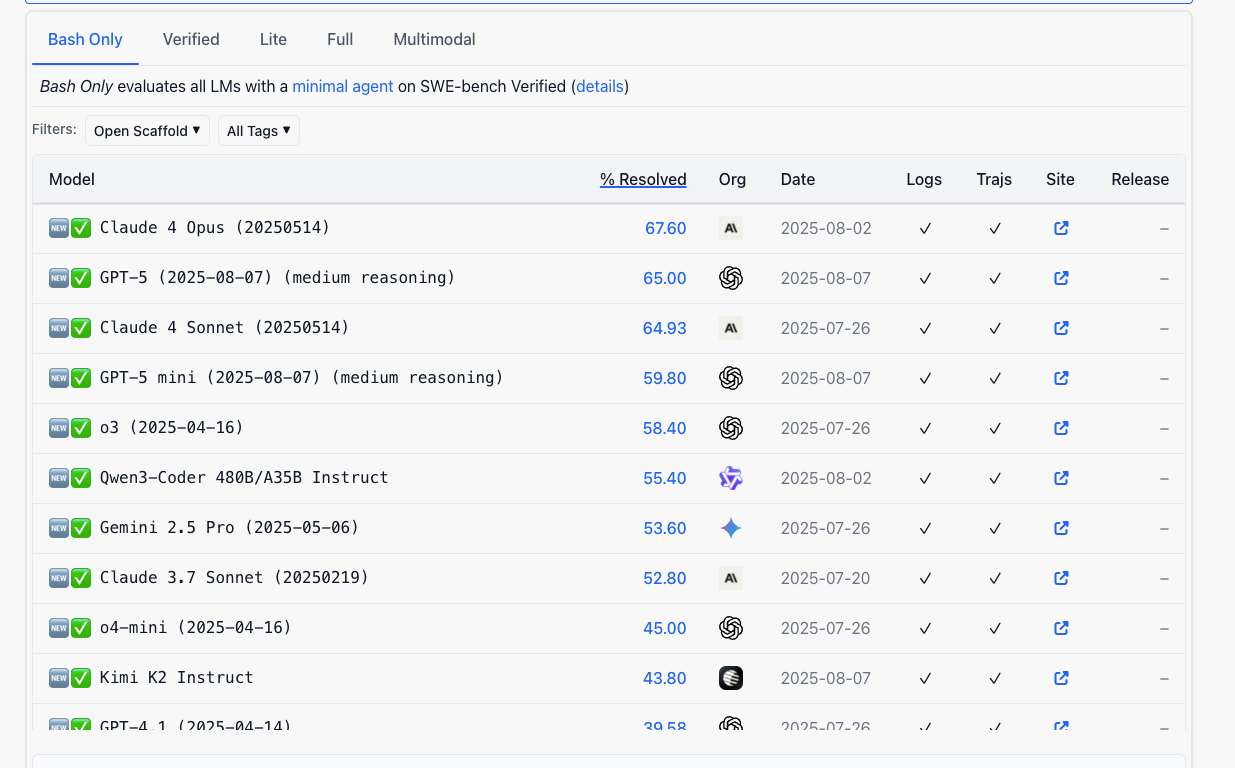
Limitations and When to Be Cautious
While Grok Code Fast 1 impresses with speed, it comes with important caveats:
Speed-First Design: The model prioritizes rapid responses, which means complex architectures or sophisticated algorithms may need multiple refinements. It's optimized for getting you a working draft quickly, not necessarily the most elegant solution on the first try.
Human Review Essential: For critical code paths, human oversight remains mandatory. The model works best for boilerplate generation, prototyping, and low-risk edits. One early user cautioned: "Even simple tasks, it can mess up... I do not trust it at all anymore [for complex changes] without oversight."
Iteration Expected: Achieving polished results often requires multiple rounds of prompting. The model might generate a functional approach that needs corrections or enhancements, especially for intricate logic or deep architectural decisions.
The bottom line: Grok Code Fast 1 serves as an excellent co-pilot for rapid iteration but shouldn't be trusted blindly for mission-critical code without careful review.
Where to Get It
Grok Code Fast 1's wide availability makes it easy to try across multiple platforms:
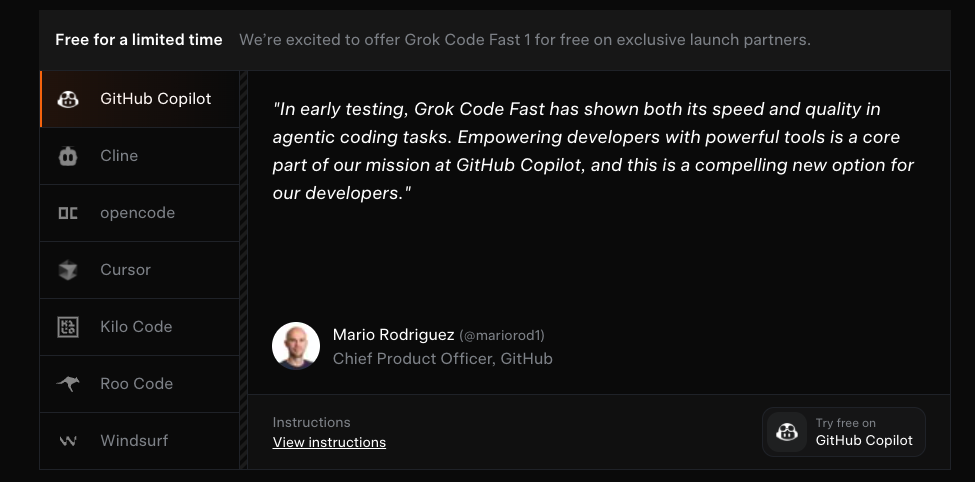
GitHub Copilot Integration: Available as a public preview for Pro, Pro+, Business, and Enterprise users in VS Code. Enable it through the model picker or have admins toggle it for organizations. GitHub offers complimentary access until September 2, 2025, after which users can continue via Copilot's model pricing or bring their own xAI API key (BYOK supported).
Partner Tools: The model launched with multiple integration partners:
- Cursor: Offers free access during the launch period
- PromptLayer:
- Cline, Kilo Code, Roo Code: Integrated for enhanced code completion
- Opencode, Windsurf: Available as backend model options
Most partners offered free trial access during the beta period to showcase capabilities and gather feedback.
Direct API Access: Available through xAI endpoints with those generous rate limits mentioned earlier. This enables custom integrations—imagine embedding it in CI/CD pipelines for automated code review or building internal developer chatbots for codebase Q&A.
The fact that GitHub endorsed the model by incorporating it into Copilot lends significant credibility. It suggests Grok Code Fast 1 was compelling enough in speed and quality to be offered alongside OpenAI's models.
What's Next
The "Fast 1" naming clearly implies this is the first in a series. xAI has revealed several exciting developments on the horizon:
Rapid Update Cadence: The team plans to deliver improvements "in days, not weeks." They've already shown this commitment—the model was initially released in stealth under the codename "Sonic," with several improved checkpoints deployed based on early feedback even before the official launch.
In Training Now: xAI announced that a new variant is already being developed with:
- Multimodal inputs: Imagine debugging based on screenshots or diagrams
- Parallel tool calls: Execute multiple operations concurrently for complex workflows
- Even longer context: Pushing beyond 256k toward repository-scale comprehension
The verdict? Stop reading about it and start building with it. With Grok Code Fast 1's free trial windows closing and multimodal updates on the horizon, now's the perfect time to test whether 92 tokens per second can transform your coding workflow. Fire up GitHub Copilot, paste your gnarliest debugging problem, and watch what happens when AI coding assistance finally keeps pace with your thoughts. The future of development isn't just faster—it's $0.20 per million tokens.
Let's find out if speed can substitute for accuracy.


