2025 State of AI Engineering Survey: Key Insights from the AI Engineer World Fair

The 2025 State of AI Engineering Survey by Barr Yaron from Amplify Partners offers a comprehensive snapshot of how engineering teams are building, managing, and scaling LLM-powered applications in production. With responses from 500 practitioners, the survey reveals critical insights about the rapid pace of model and prompt iteration, the persistent challenges around evaluation, and perhaps most unsurprisingly—that large majority of teams use prompt management tooling. These findings underscore the growing importance of robust observability and management platforms as LLM features become increasingly central to both internal tools and customer-facing products.
The Evolving Role of AI Engineers
The survey reveals that while few practitioners formally hold the title "AI Engineer," the majority of the 500 respondents—primarily those identifying as software or AI engineers—are actively engaged in AI engineering work under various titles.
This reflects the reality that AI engineering is becoming a core competency across engineering teams rather than a specialized role—making accessible tooling even more critical.
LLMs Serve Both Internal and External Use Cases
Half of all respondents use LLMs for both internal tooling and customer-facing features, demonstrating the dual value proposition of large language models in modern organizations.
Models Are Swapped Frequently in Production
50% of respondents regularly update models monthly or more frequently, with 17% updating weekly. The landscape is changing fast. The latest-and-greatest models are changing weekly.
Prompts Are Updated Even More Frequently Than Models
The survey shows remarkable dynamism in model selection: 70% of teams update their underlying models at least monthly, with 10% making changes daily.
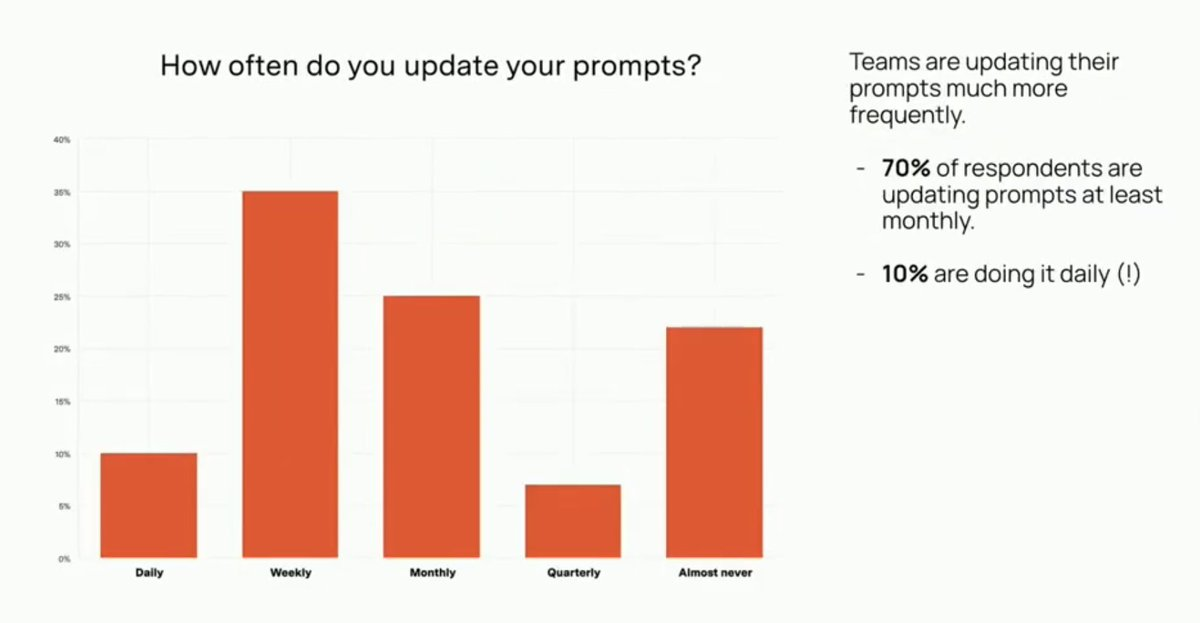
This frequent updates make it essential to have a system that can track performance across different models, prompt versions, and user segments—a core value proposition of prompt management tools like PromptLayer.
The Prompt Management Gap
A large majority, 69% of teams, are using tooling for prompt management. It's pretty clear how critical prompt versioning, testing, and organization is— but 31% of teams still rely on ad-hoc solutions or manual processes.
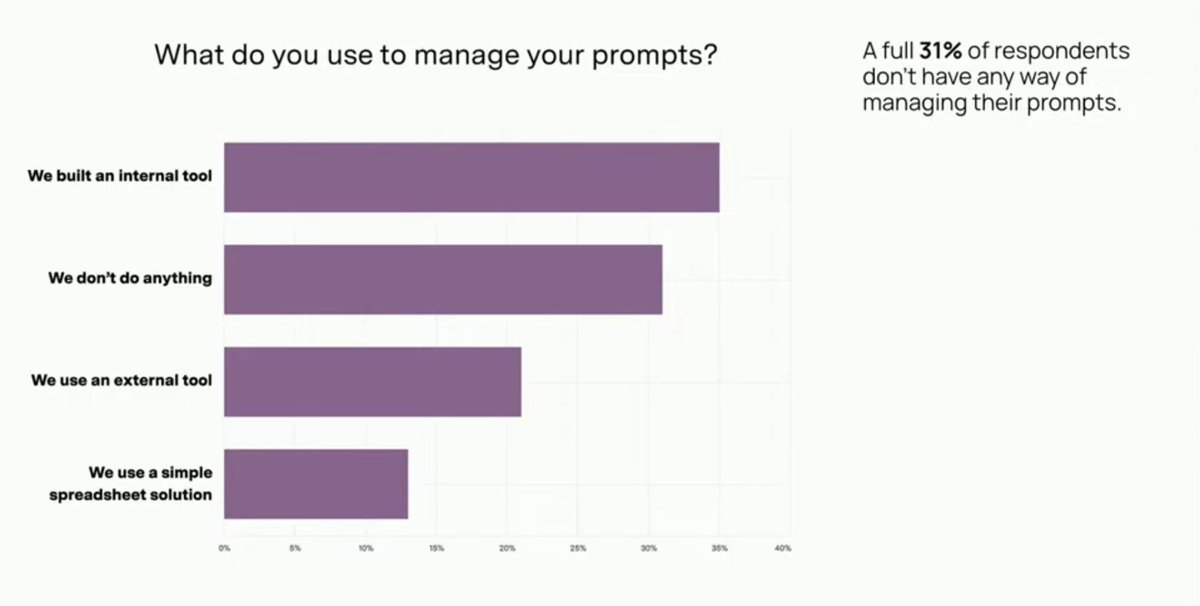
We find that LLM teams go through a journey. They begin with ad-hoc and manual processes. Next they might move to a spreadsheet or Notion doc. Prompt management tooling becomes most valuable after proving out the AI product or adding headcount to the team. To build reliable AI, you need to track and collaborate on prompts.
AI Agents Face Quality Challenges
While there's significant interest in AI agents, fewer than 20% of respondents say agents are "working well" in their organizations—a stark contrast to the success of simpler LLM features.
Agents require more rigor. Errors are easy to compound, and your team needs to invest more in agentic evals.
Most Teams Haven't Deployed Agents to Production Yet
The majority of teams are still in the experimental phase with agents, though less than 10% say they'll never use them.
Monitoring Approaches Vary Widely
Teams employ diverse monitoring strategies: 60% use standard application observability tools like DataDog, while 50% rely on offline evaluations, often combining multiple approaches.
At PromptLayer, we believe you need both. Offline evals are great for development-phase iteration. But the key to prompting truth is production data.
Human Review Remains the Gold Standard for Evaluation
Despite advances in automated evaluation, human review remains the most popular quality assessment method, supplemented by user data collection and benchmarks.
LLM-as-judge servers to augment and scale human insight, but it's hard to get right.
Evaluation Is the Top Pain Point
When asked about their single most painful aspect of AI engineering, evaluation tops the list—a clear signal of where the industry needs better tooling and practices.
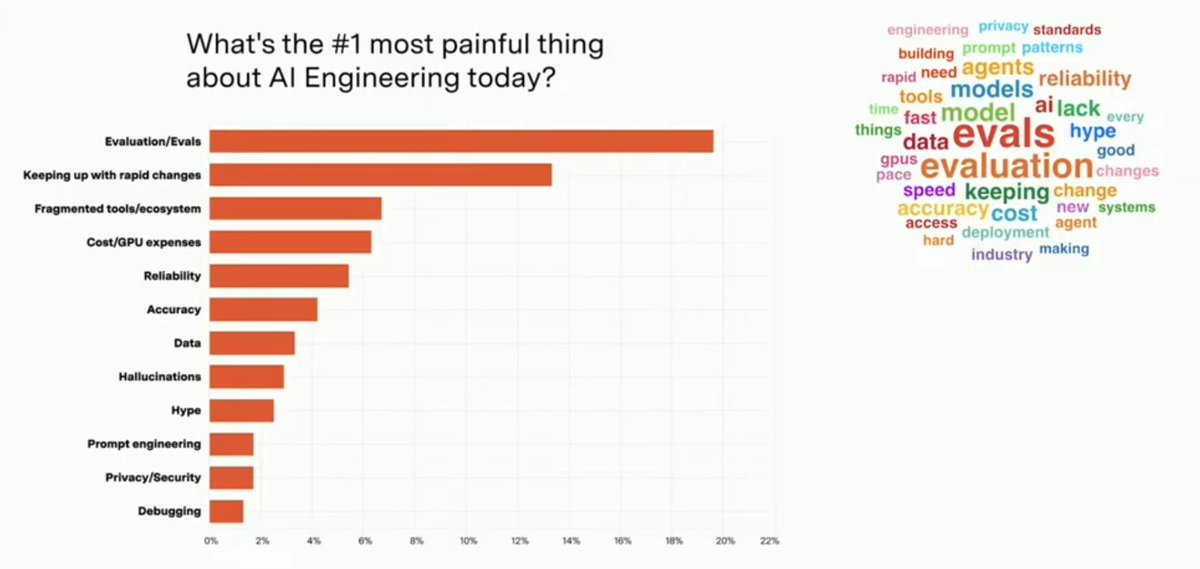
Effective evaluation requires not just running tests but managing test sets, tracking results over time, and comparing performance across different prompts and models. Read more about advanced eval strategies.
OpenAI Dominates Production Deployments
Three of the top five—and five of the top ten—models in production come from OpenAI, showing their continued market leadership in customer-facing applications.
This concentration makes it crucial for teams to avoid vendor lock-in by using abstraction layers that make it easy to switch between providers.
Code and Content Generation Lead Use Cases
The top LLM applications are code generation/intelligence and writing assistant features, reflecting the technology's strengths in these domains.
Teams Deploy Multiple LLM Use Cases
An overwhelming 94% of teams use LLMs for at least two distinct use cases, with 82% supporting three or more applications.
RAG Is the Dominant Customization Technique
While few-shot prompting serves as the baseline, 70% of teams have adopted Retrieval-Augmented Generation (RAG), with fine-tuning also showing surprising popularity.
Fine-Tuning Methods Show Diversity
Among teams using fine-tuning, 40% leverage parameter-efficient methods like LoRA/QLoRA, while others employ DPO, RLHF, and supervised approaches.
Text Dominates, But Multimodal Interest Grows
While text remains the primary modality in production, 37% of teams not currently using audio plan to adopt it, indicating a "multimodal production gap."
Vector Databases Are Standard Infrastructure
65% of teams store embeddings in dedicated vector databases, split roughly equally between self-hosted and managed solutions.
Open and Closed Models Expected to Converge
The majority of practitioners expect open-source and closed-source model capabilities to eventually converge, suggesting a more competitive future landscape.
The AI Companion Future
In a lighter note, respondents predict an average of 26% of Gen Z will have AI girlfriends/boyfriends—a glimpse into potential social applications of the technology... Scary!
The 2025 State of AI Engineering Survey (watch the full talk here) paints a picture of an industry in rapid evolution, where teams are iterating quickly, deploying diverse use cases, and grappling with fundamental challenges around evaluation and management.
The fact that nearly a third of teams lack prompt management tooling, combined with the frequency of prompt and model updates, suggests significant opportunity for platforms that can bring structure and observability to LLM operations.
PromptLayer is an end-to-end prompt engineering workbench for versioning, logging, and evals. Engineers and subject-matter-experts team up on the platform to build and scale production ready AI agents.
Made in NYC 🗽
Sign up for free at www.promptlayer.com 🍰


