Why LLMs Get Distracted and How to Write Shorter Prompts

Context Rot: How modern LLMs quietly degrade with longer prompts — and what you can do about it
Context Rot: What Every Developer Needs to Know About LLM Long-Context Performance
How modern LLMs quietly degrade with longer prompts — and what you can do about it
If you've been stuffing thousands of tokens into your LLM prompts thinking "more context = better results," I have some sobering news. A new study from Chroma — "Context Rot: How Increasing Input Tokens Impacts LLM Performance" by Kelly Hong, Anton Troynikov, and Jeff Huber — reveals that every major LLM suffers from "context rot" — a progressive decay in accuracy as prompts grow longer, even on tasks as simple as "repeat this string."
This isn't just an academic curiosity. If you're building RAG systems, chatbots with conversation history, or any application that feeds lengthy context to LLMs, this affects you directly. Let's dive into what the research found and, more importantly, what you can do about it.
The Uncomfortable Truth About Long Context
Here's what the Chroma research team discovered when they tested 18 models (including GPT-4.1, Claude 4, Gemini 2.5, and Qwen 3):
- The uniform-context myth is dead. Models don't treat all tokens equally — accuracy degrades in complex, task-dependent ways
- Popular benchmarks lie to us. Needle-in-a-Haystack (NIAH) tests are essentially trivial lexical lookups. Harder benchmarks reveal much steeper performance cliffs
- Chat history is your worst enemy. Adding full conversation history (≈113k tokens) can drop accuracy by 30% compared to a focused 300-token version
Think about that last point. That helpful chatbot that remembers your entire conversation? It might be getting progressively worse at answering your questions.
The Mechanisms Behind Context Rot
The research isolated several factors that accelerate context degradation:
1. Semantic Distance Matters
The less your question resembles the relevant information in the context, the faster performance decays. It's not enough to have the answer somewhere in your prompt — it needs to be semantically close to the query.
2. Distractors Are Poison
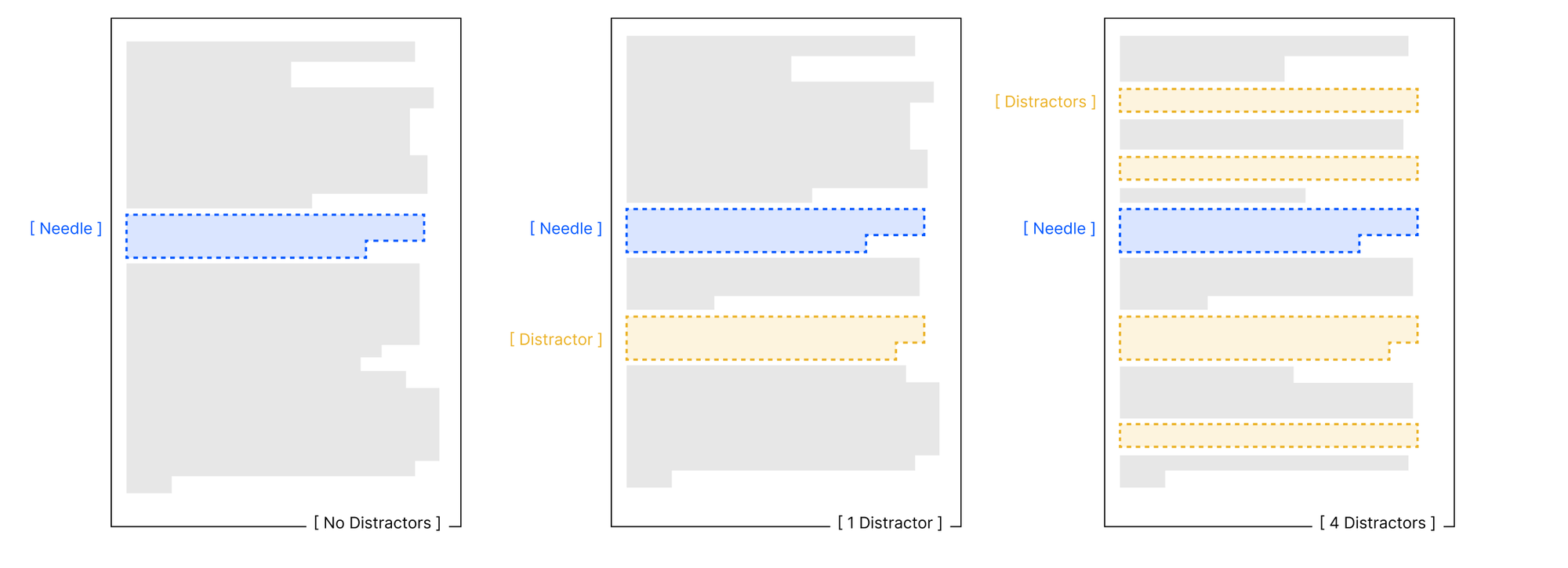
Even a single piece of similar-but-wrong information significantly hurts performance. Add four distractors? Performance tanks. Interestingly, GPT models tend to hallucinate when confused, while Claude models simply refuse to answer.
3. Structure Can Backfire
Here's a counterintuitive finding: coherent, well-structured documents actually make retrieval harder than random text chunks. Models get trapped following narrative arcs instead of finding specific information.
4. Output Length Limitations
When asked to repeat long sequences, models start refusing, truncating, or inventing tokens after about 2,500-5,000 words. They literally can't output what they just read.
Tips for Context Engineering Smaller Prompts
Curious what "Context Engineering" is? Read more here.
For RAG/Retrieval Workflows
1. Embrace Surgical Precision Stop brute-force stuffing. Retrieve less than 1,000 tokens of high-similarity content. Quality beats quantity every time.
2. Implement Multi-Stage Reranking Use cross-encoders or lightweight LLM reranking to eliminate near-miss distractors before they poison your context.
3. Break Narrative Flow Chunk documents into 3-5 sentence windows without preserving long narrative arcs. Yes, it feels wrong. Do it anyway.
For Prompt Engineering
The Similarity Booster Pattern
Relevant facts: [2-3 lexical paraphrases of the user question]
Context: [your retrieved content]
Question: [original user question]
The Ambiguity Guard
If the answer is uncertain or not clearly present in the context,
respond with: 'INSUFFICIENT_CONTEXT'
Reasoning Mode Strategy Only enable chain-of-thought or "thinking" modes after retrieval. It helps but doesn't eliminate the gap.
For Production Systems
As we argue in "Production Traffic Is the Key to Prompt Engineering", real user traffic is the only way to surface the edge cases that matter. This is especially critical for context rot — you need to see how your prompts degrade with actual user inputs, not just synthetic test cases.
Regression tests are your friend.
Model Selection Insights
The research revealed interesting personality differences. Note that this was published July 14, 2025... these things change daily!
- Anthropic models: More conservative, make fewer hallucinations but answer less frequently
- OpenAI models: Bolder but riskier, more likely to hallucinate when uncertain
The Bottom Line
Context isn't free. Every token you add to a prompt is a small bet against accuracy. The key insight from the Chroma team's research isn't that long context is useless — it's that we need to be surgical about how we use it.
Treat context as a scarce resource. Retrieve smartly, compress aggressively, validate continuously, and always measure. Your prompts will be shorter, your responses more accurate, and your users happier.
The context rot phenomenon reinforces a fundamental truth: prompt engineering isn't going away — it's evolving into something more sophisticated. The core skill isn't writing clever prompts; it's architecting the entire input-output pipeline.
What information goes into the context? How much can we include before degradation kicks in? Should we use chain-of-thought reasoning? Which model handles our specific context structure best? These design decisions — what we might call "context engineering" — determine whether your AI system thrives or rots under real-world usage.
Want to Dive Deeper?
- Read the full Context Rot research
- Production Traffic Is the Key to Prompt Engineering
- Chroma's reproducible codebase
- NoLiMa dataset & scripts
- MRCR/GraphWalks datasets
Remember: In the age of "million-token context windows," sometimes less really is more.


