Why LLM Evaluation Results Aren't Reproducible (And What to Do About It)

Ever run the same AI model twice and gotten different answers? You're not imagining things. The PromptLayer team have seen this frustration play out repeatedly across research labs and production systems alike. Reproducibility - the ability to achieve consistent results under the same conditions - is foundational to science and engineering. Yet in the world of large language model evaluations, it's surprisingly elusive. A recent analysis of 69 academic papers evaluating OpenAI's models found that only 5 had code that could even run, and zero fully reproduced the reported results. That's a crisis, not a quirk. As LLMs become embedded in everything from medical diagnosis to legal research, understanding why this happens matters more than ever.
The model you tested last month isn't the same model today
One of the biggest culprits behind irreproducible results is something most researchers can't control: model updates. Commercial LLM providers like OpenAI regularly refine their models, sometimes replacing old versions entirely without warning. The GPT-4 you evaluated in March 2023 behaved differently by June 2023, with researchers documenting substantial performance shifts on identical tasks after updates rolled out.
This creates an impossible situation. If you publish results based on a specific model version and that version gets deprecated, no one can verify your findings. They're testing against a moving target. Even when providers offer version identifiers, they eventually retire older models, leaving researchers stranded. Open-source models offer more stability here since you can pin exact checkpoints, but the most capable models remain proprietary and constantly evolving.
Rolling dice with every API call
Even if you could freeze the model, LLM outputs are inherently probabilistic. Think of it like rolling dice - the same prompt can yield different answers on different runs because of how these models sample from probability distributions during text generation.
You might assume setting temperature to zero solves this, and setting a random seed should lock things down further. In practice, it helps but doesn't guarantee identical outputs. Why? Parallel computing introduces subtle variations. When calculations run across multiple threads or GPUs, the order of operations can shift slightly, and those tiny differences cascade through billions of parameters.
One study found that identical settings - same seed, same temperature, same prompt - outputs still varied across runs. For evaluation purposes, this means a model might score 78% accuracy one day and 81% the next, not because anything meaningful changed, but because of inherent stochasticity in how the computation unfolds.
When hardware becomes a hidden variable
Here's where things get unexpectedly technical. The numerical precision your system uses - whether bf16, fp16, or fp32 - can meaningfully alter model outputs. Floating-point arithmetic isn't associative, meaning (a + b) + c doesn't always equal a + (b + c) when you're working with limited precision. In massive neural networks, these microscopic differences compound.
Recent research demonstrated that changing batch size, switching between GPU types, or even altering the number of GPUs used for inference can cause an LLM's answers to diverge dramatically. One team found that identical evaluation code produced different results simply because they ran it on different hardware configurations.
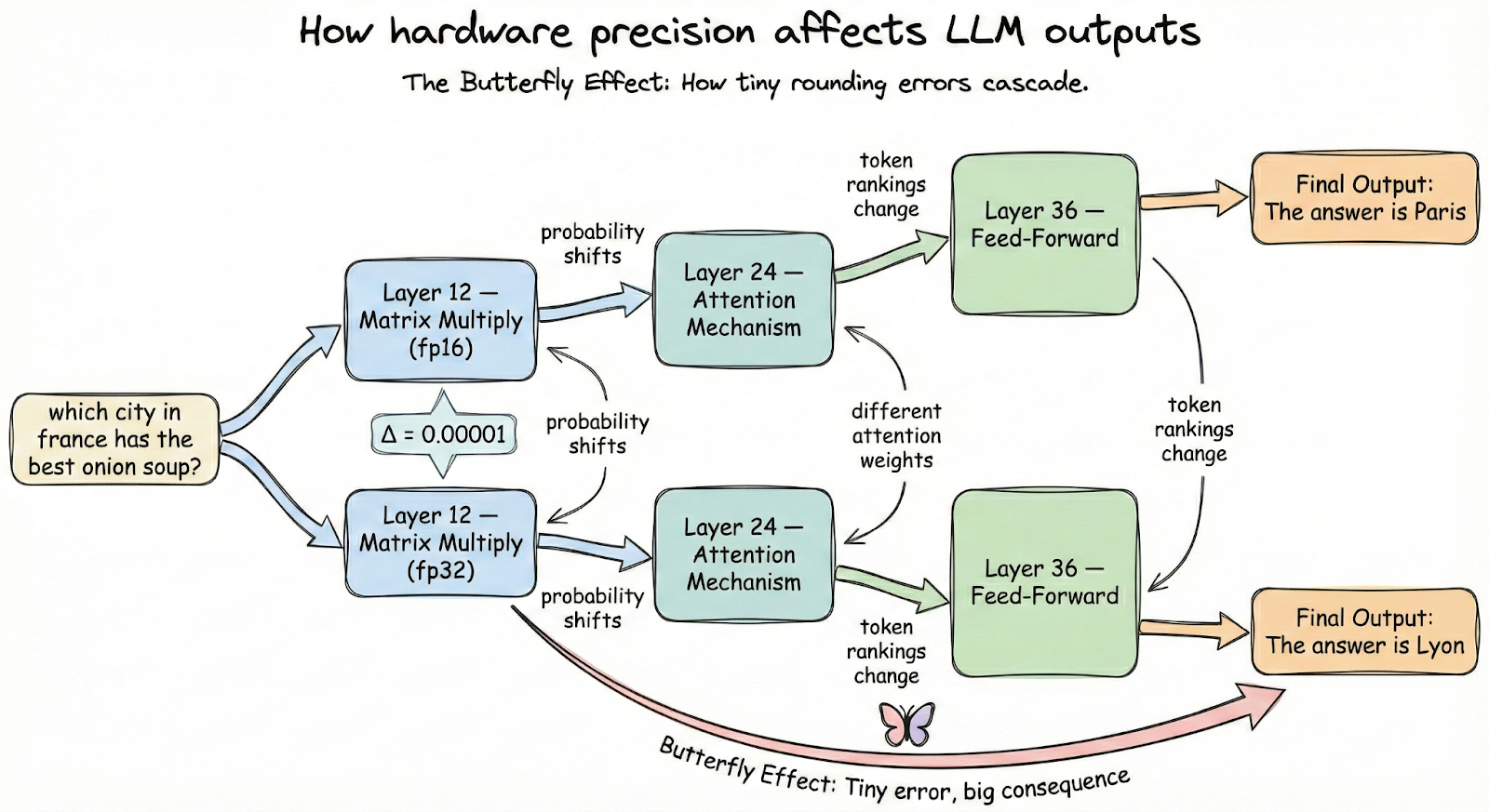
This is the butterfly effect playing out in silicon. A rounding difference in one layer propagates forward, nudging probability distributions just enough to flip a token choice, which changes everything downstream. For practitioners, this means reproducibility requires documenting not just your code, but your entire compute environment.
What we forget to write down
Beyond technical factors, there's a simpler explanation for irreproducible results: we don't document enough. Many papers omit critical details that seem trivial but matter enormously.
- Exact prompts: Minor wording changes can shift results by several percentage points
- System prompts and formatting: How you structure the input affects how models respond
- Parsing logic: Two teams might score the same output differently based on how they extract answers
- Hyperparameters: Temperature, top-p, max tokens, and other settings often go unreported
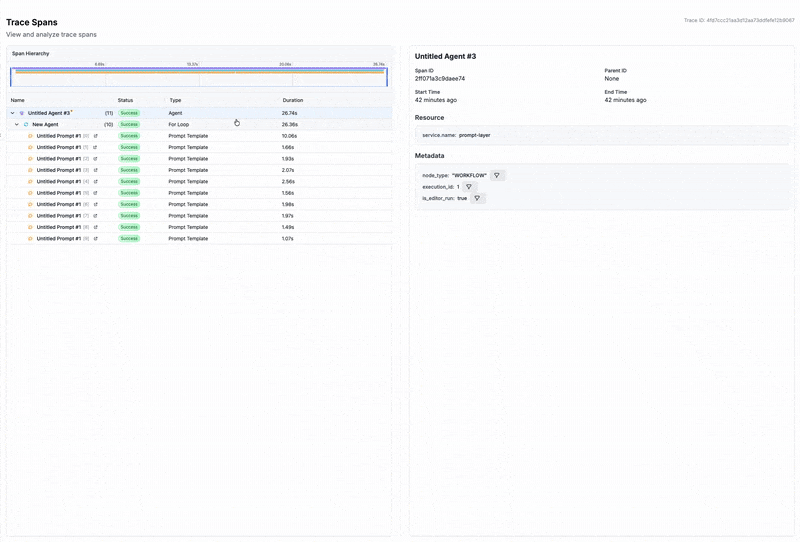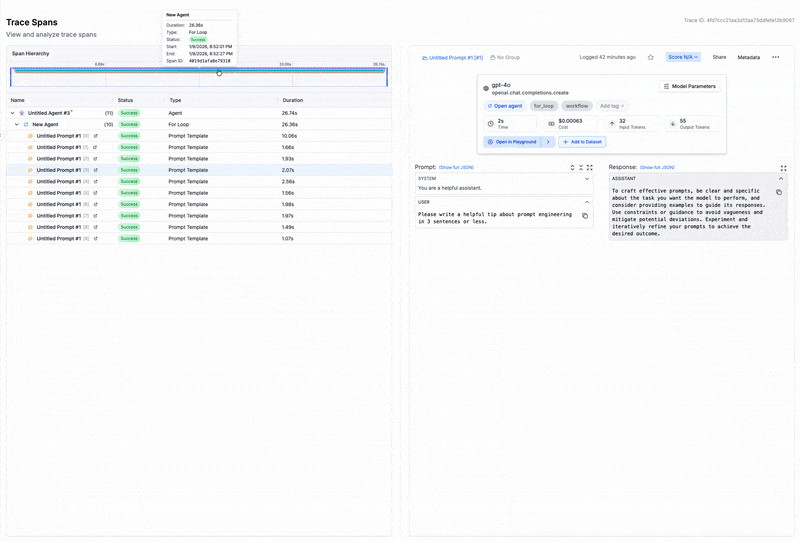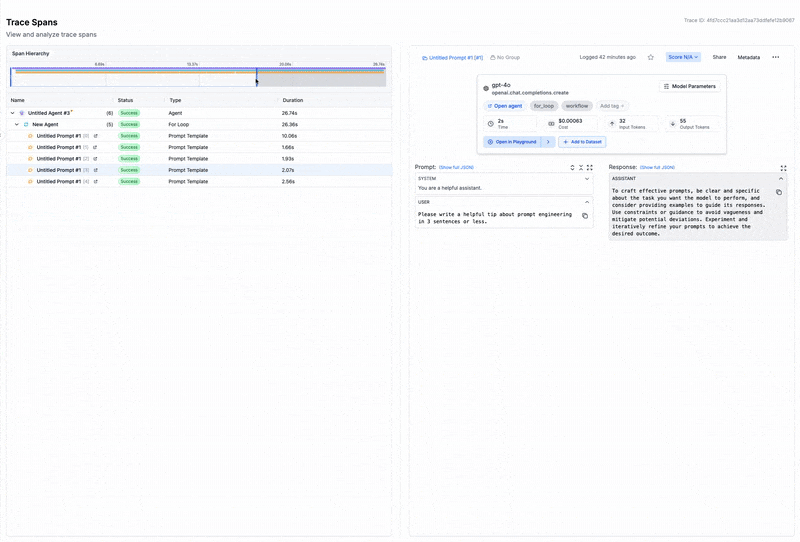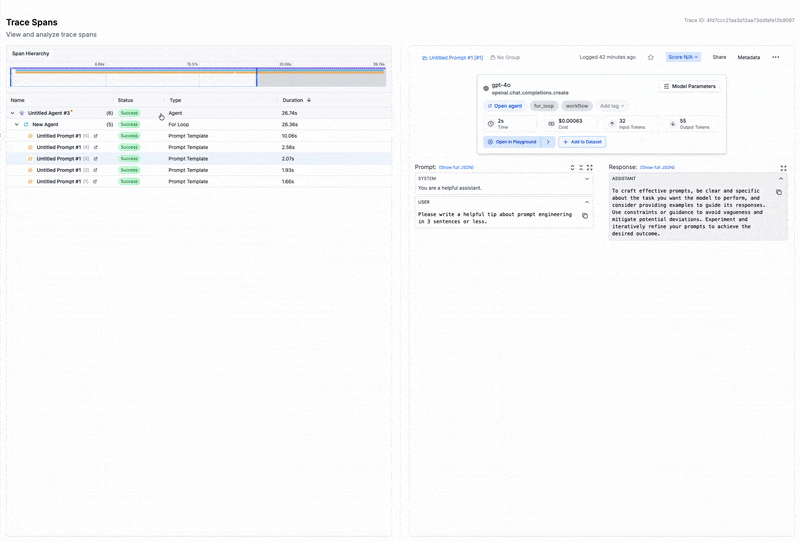
This is where an observability platform can be a game-changer. Tools like PromptLayer automatically log every prompt, model version, parameters, and response - so instead of relying on manual documentation, the full request context is captured by default. Without these details, reproduction becomes guesswork. Someone trying to verify your results might use a slightly different prompt template or evaluation script, get different numbers, and conclude your findings don't hold. The problem isn't that your results were wrong - it's that the path to reaching them was never fully marked.
Making reproducibility the default
The good news is that the community recognizes these challenges and is building solutions. Here's what actually helps:
- Pin model versions explicitly. When using APIs, specify version identifiers and document the date of your experiments. For open models, record exact checkpoint hashes.
- Use standardized evaluation frameworks. Tools like EleutherAI's lm-eval harness provide consistent benchmarks and scoring, reducing variability from custom implementations.
- Document everything obsessively. Share your prompts verbatim, your parsing code, your random seeds, and your hardware specs. In the future you will thank the present you.
- Run evaluations multiple times. Report variance, not just single scores. If results fluctuate significantly across runs, that's important information.
- Prefer deterministic settings where possible. Greedy decoding eliminates sampling randomness, even if it slightly affects output quality.
Community initiatives are pushing for standardized reporting requirements at major conferences, and open-source evaluation libraries continue maturing. These efforts won't solve everything, but they establish shared infrastructure that makes replication feasible rather than heroic.
Trust is built on replayable experiments
If your eval can't be replayed, it isn't evidence, it's a screenshot. That doesn't mean anyone acted in bad faith, it means LLMs turned reproducibility into a systems problem: moving model versions, probabilistic generation, floating-point quirks, and missing protocol details all pile up fast.
So treat reproducibility like a product requirement. Pick a model you can pin, lock your settings, record the environment, publish the exact prompts and parsing, and run more than once. The payoff is simple: results that other people can verify, and results you can still trust a month from now.


