Why Fine-Tuning is (Probably) Not for You

For some reason, it feels like every startup now has its own custom-trained model. This has brought fine-tuning back into the vogue as a must have addition. In this article, we’ll be diving into the world of fine-tuning — specifically understanding when it makes sense and when it doesn't.
As a bit of background, fine-tuning is often done by taking one of the commonly-used base LLMs and then utilizing a custom dataset to change the model's behavior. The main other method of changing model behavior is few-shot learning, often within RAG to pull data into the few-shot examples. For simplicity, I’ll refer to this approach as just RAG.
So without further ado, let's dive into the positives and negatives of fine-tuning.
The Downsides of Fine-Tuning
Questionable performance gains over RAG
The main point against fine-tuning is that it isn't all that much better than RAG. In fact, studies have shown its often worse.
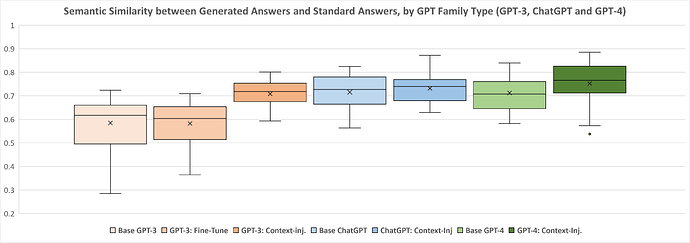
This point is further emphasized by recent gains in model adaptability and context window length. Longer context windows mean more possible examples in the few-shot. Models becoming more adaptable also means that general models now work better in domain-specific contexts.
Complex Process
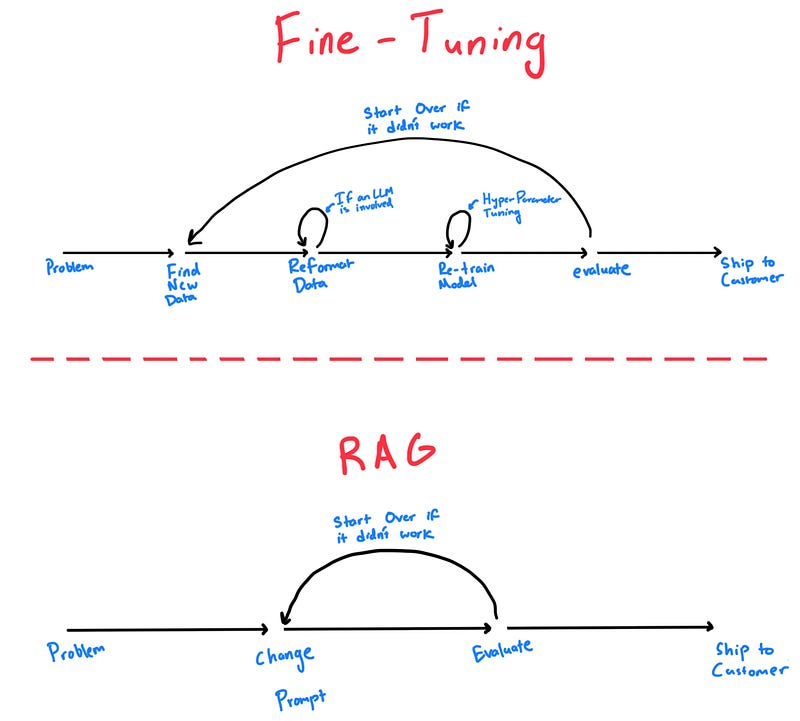
Then there's the complexity of the process. At a large scale, the fine-tuning process is not easy. Finding the data, creating the pipeline, setting up the training, and then putting the model into production — all to restart the process for a new model or change in input data–creates a Sisyphean-level task. All of this is made all the worse by the amount of trial and error in the process needed to find good results.
Slower Iteration
The real crime is how it affects the development cycle. Any changes in the fine-tuning process require changing the training dataset significantly and re-training the entire model. With the specific data format fine-tuned models require and the magnitude of change needed to the training dataset to notice an impact on end model performance, this can be complex and time-consuming. Likewise, re-training the model is time-consuming and expensive!
On the other hand, RAG is just a simple change at inference, meaning a world of difference in time, complexity, and cost.
Lost Generality
Fine-tuned models also often lose generality. While this is often the point of fine-tuning, it puts into question how this interaction will work with new models that have flexibility as one of their key features. Multi-modality for example, as seen in newer models like OpenAI’s 4o, may be diminished by fine-tuning without providing multi-modal training examples. This may make sense for specific models that are created for one use case alone, but might fail to generalize.
Added Costs
Then there’s the cost question. It’s easy to think of RAG as a variable cost, tacking on a couple of cents in tokens for each call. Under this same line of thought, fine-tuning is more of a one-time fixed cost. Train once and then the fine-tuned model is ready to go with less token costs per call. While this is true, it ignores the longer-term implications. Fine-tuning also requires constant updates, for fixing issues, adding new data, or updating the base LLM. All of these possibilities make the one-time cost of fine-tuning, a lot less one-time. Add on top the costs associated with the added developer time from the added complexity and the cost trade-off seems a lot less favorable, even when operating at a large scale.
Unknowns Regarding Data Needs
Another major question is how much data you need to fine-tune effectively. Finding enough data points to train the model on often means having more than 10k examples. While there are a lot of tricks you can use to break up long-form content into multiple training examples, getting such a large amount of data in the right format adds to the hassle making fine-tuning not worth it for most.
Potential Data Privacy Issues
Finally, this is a minor point, but one worth noting. Depending on which base LLM provider you’re working with, the fine-tuning process could require sharing sensitive customer data with third parties. This just adds another possible data privacy headache that RAG may not cause.
The Positives of Fine-Tuning
Specific Output Format
One of the best use cases for fine-tuning is for getting a specific output format. This makes the most sense when a model is used for only one purpose, or if you always need it to output in a specific way. This helps LLMs take advantage of their multi-format input and domain knowledge while making the outputs more standardized.
Editing Writing Style & Tone
Fine-tuning can also be useful for editing the tone and writing style of the model. Models are already really good at writing. Fine-tuning then helps make the micro-edits necessary for slight tone shifts. While this has fewer practical use cases, it is fun for projects like getting a model to write like you would.

Complex Reasoning
Research has also shown that fine-tuning can help models through complex reasoning. Sequential instruction training, i.e. fine-tuning models by showing a series of instructions to follow, outperformed on several multi-step tasks. While this method is currently less proven, it could help force a model to adapt to a specific line of thought. It is also important to note that this method has little research benchmarking its performance versus chain-of-thought prompting.
Minimizing Token Usage
Stop me if you’ve followed this path before. You’re prompt engineering and keep running into use cases that require added instructions. Before you know it, the prompt is humongous (and subsequently multiplying your token usage costs).
Here’s where fine-tuning can almost build-in parts of the prompt, saving you on tokens in the long run.
Up-Cycling an Older Model
We’ve found that using GPT-4 results, you can fine-tune a cheaper model like 3.5-turbo and get similar results. And this doesn’t just apply to OpenAI, Stanford’s Alpaca model replicated the performance of a LLaMA model extremely cheaply, and the research shows promise in its ability to replicate most major LLMs. Fine-tuning an older model to perform like a new one can help you save on API costs and increase performance speed. This is especially easy to do by using your old requests (something that PromptLayer is pretty great at helping with 😉).
This then brings us to the question of why not just use both?

The simple answer is that it is often overkill. We’ve seen both used when someone was using RAG and then additionally wanted one of the added benefits of the fine-tuned model, such as changing the output format. While it worked and often improved performance, the gains were menial over just using RAG alone. With all the downsides of fine-tuning, its just often not worth doing considering the benefits are so small.
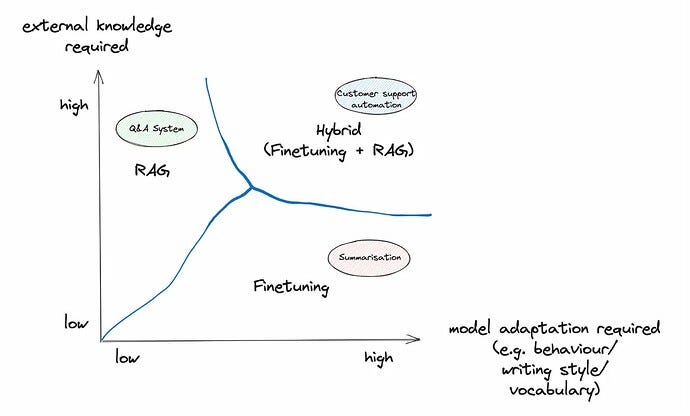
Understanding the Trade-Off
This medium article has a great picture that I think represents a fair, but bit older perspective on fine-tuning:
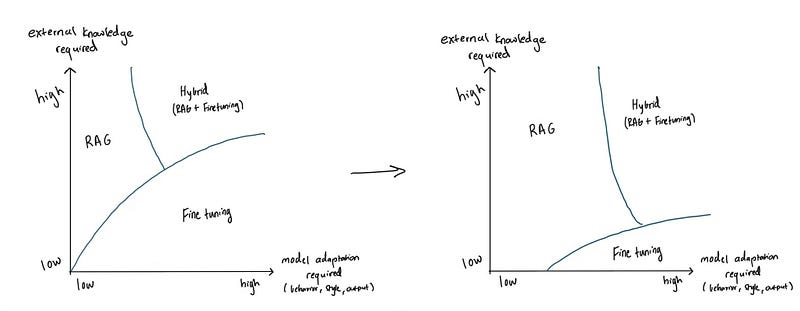
Now, with innovations in context window, model adaptability, and base model performance, I think the picture has the intersection shifting down and to the right such as below:
Which begs the question: Why does fine-tuning still have so much mind-share? I think one of the biggest is just optics — saying you’re using RAG simply sounds a lot less differentiated than saying you have a custom-trained model. While this might help you raise from VCs and attract customers, it probably is also slowing down your development speed and not meaningfully impacting the customer experience 🤷🏽♂️.
So if you want to increase your development speed and keep your company at the forefront of AI innovation, I’d steer clear of fine-tuning for now. Or, at least, start with prompting + RAG since it will make life so much easier in the long run.
PromptLayer is a prompt management system that helps you iterate on prompts faster — further speeding up the development cycle! Use their prompt CMS to update a prompt, run evaluations, and deploy it to production in minutes. Check them out here. 🍰


