Understanding Intermittent Failures in LLMs

You shipped your LLM application, it passed all your tests, and users loved it. Then, seemingly at random, it starts returning nonsense, timing out, or refusing to answer. The PromptLayer team spends a lot of time observing production behavior in AI applications, and we encounter this question constantly. Intermittent LLM failures are among the most frustrating bugs to diagnose because they violate a core assumption many engineers carry over from traditional software - that identical inputs should produce identical outputs. Understanding the layers where these failures originate is essential for building AI systems that actually hold up in the real world.
The stochastic layer runs deeper than you think
Some might assume that setting temperature to zero guarantees deterministic output. It does not. At the hardware level, LLM inference involves massive matrix multiplications across thousands of GPU cores. The order in which these operations complete depends on factors like thermal throttling, memory bus contention, and dynamic thread scheduling. Because floating-point arithmetic is not associative, slight variations in execution order can produce different results in the least significant bits.
This might seem trivial, but LLMs are autoregressive. Each token depends on every previous token. A single bit-level difference in the first logit calculation can flip the selection from one likely token to another, and once that happens, the entire generation trajectory diverges. Your model might produce a factual response one minute and a confident hallucination the next, with no change to your prompt. This "butterfly effect" explains why some failures are genuinely impossible to reproduce.
Attention has blind spots
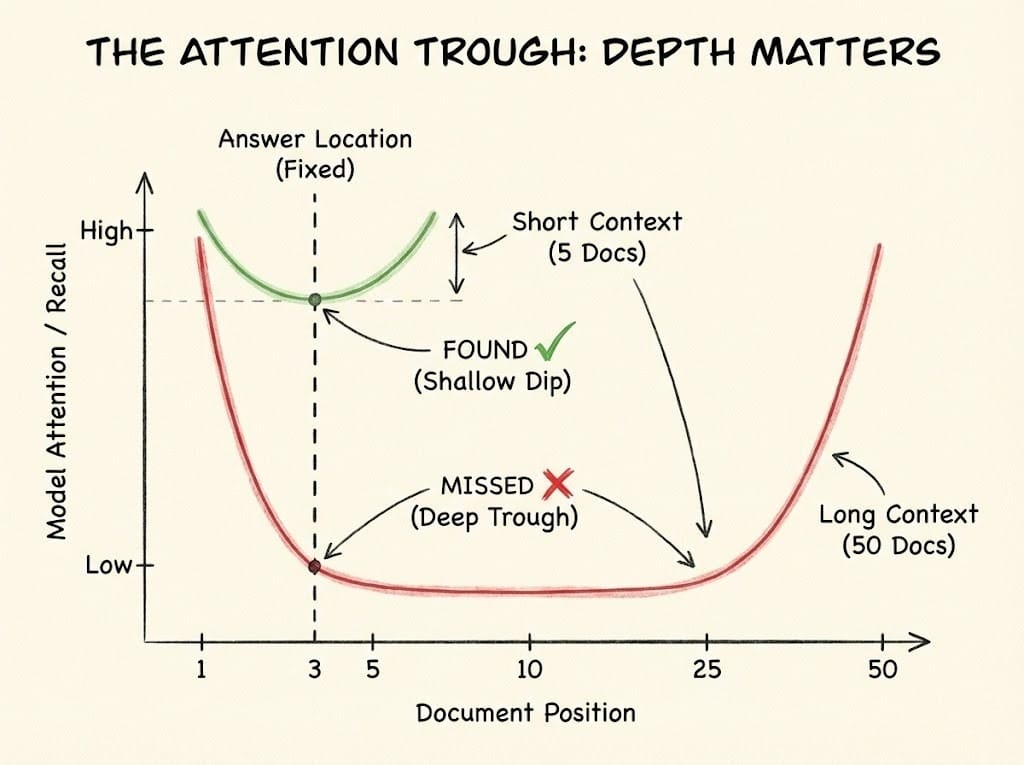
Even if execution were perfectly stable, Transformers have structural limitations in how they process context. Research has lost in the middle phenomenon where models attend strongly to the beginning and end of their context window but struggle with information buried in the middle. When plotted, performance forms a distinct U-shape.
This creates failures that scale with data volume:
- Small retrieval set: You ask a question and your RAG system retrieves five documents. The answer sits in document three. Context is short, the model finds it, success.
- Large retrieval set: A broader question retrieves fifty documents. The answer is still in document three, but now it sits in the attention trough. The model claims ignorance, and you see an intermittent failure that correlates with query complexity rather than any obvious bug.
Context window overflow compounds this problem. When conversation history, system prompts, and retrieved documents compete for limited tokens, something gets truncated. If your system prompt scrolls out of view in a long conversation, the model suddenly forgets its instructions, loses its persona, or stops outputting valid JSON.
Retrieval systems fail silently
RAG architectures introduce a probabilistic failure point before the model even sees your context. Vector databases rely on embedding models to map text into high-dimensional space, assuming semantically similar texts will cluster together. As your index grows from thousands to tens of thousands of chunks, that assumption weakens.
In crowded vector spaces, the distance between the "correct" document and a misleading distractor can shrink to nearly nothing. A tiny perturbation in query phrasing or a model update can flip the ranking, causing your system to retrieve wrong information with high confidence. The LLM then confidently answers based on that wrong context, and you see what looks like a random hallucination. Once you have a hypothesis, you can test it using evaluations.
Mitigation strategies that actually help in production include:
- Hybrid search: Combine dense vector retrieval with sparse keyword search (BM25), then rerank results to boost exact matches.
- Reranking and reordering: Use a cross-encoder to rescore retrieved chunks and place the highest-scoring ones at the beginning and end of the context.
- Metadata filtering: Pre-filter vector search using hard constraints like date or category to reduce search space complexity.
- Observability and Evals: Use platforms like PromptLayer for logging, tracing, and evaluation to quickly identify intermittent failures and root causes. Integrating these production evals directly ties observed behavior to your pre-shipment quality checks.
- Smart chunking: Use recursive splitting with overlap and fetch parent documents for small chunks.
The model itself keeps changing
Perhaps the most maddening source of intermittent failure is that you did nothing wrong. The model changed. Research tracking GPT-4 over time documented significant volatility in behavior. Accuracy on certain tasks dropped dramatically between model versions, often as a side effect of alignment updates rather than intentional changes.
Prompts are "soft code" that rely on specific activation patterns in specific model versions. A prompt optimized for one version may fail on the next because the newer model interprets instructions differently or becomes more restrictive. Traditional monitoring catches latency and error rates but misses semantic drift entirely. Your uptime stays perfect while your output quality quietly degrades.
Trade certainty for control
Intermittent LLM failures are rarely random, they are layered. A whisper of floating-point noise can push greedy decoding over a boundary. A retrieved fact can vanish into the middle of a long context. A rerank can flip at scale. A load balancer can quietly cut a slow request. A provider can ship an update and your "soft code" prompt stops compiling.
Focus less on achieving system determinism and more on building observability and resilience - instead of trying to eliminate non-determinism, concentrate on:
- Pinning the essential, non-negotiable instructions.
- Treating retrieval as an adversarial component, defending against its failures using hybrid search, reranking, and hard constraints.
- Implementing robust failure handling mechanisms, including backoff with jitter, circuit breakers, and fallbacks.
Monitoring for meaning rather than just uptime, as semantic drift is a silent failure mode that won't trigger standard alerts... If you want fewer 3 a.m. mysteries, engineer for uncertainty on purpose.


