Prompt routers and flow engineering: building modular, self-correcting agent systems

The shift from crafting individual prompts to designing entire reasoning flows has fundamentally changed how we build AI applications. The PromptLayer team have watched this evolution closely, observing how teams move from trial-and-error prompt tweaking toward systematic architectures that can catch their own mistakes. This transition represents more than a technical upgrade - it reflects a maturing understanding of what makes LLM applications reliable at scale.
Why linear chaining stopped being enough
In 2024, prompt chaining was the standard approach for complex tasks. Developers would break problems into sequential steps, passing outputs from one model call to the next. While this improved accuracy over single-shot prompts, the approach had a fundamental weakness: it required extensive human effort to dissect problems and engineer each step manually. Building effective chains demanded that developers anticipate every branch and edge case upfront, rather than trusting the model's own reasoning capabilities.
The answer came in the form of the agentic loop: a simple pattern where the LLM runs in a cycle - reasoning, selecting tools, executing actions, and observing results - until it reaches a goal. As Simon Willison defines it: "An LLM agent runs tools in a loop to achieve a goal." Instead of rigid pipelines where data flows in one direction, these systems can:
- Revisit previous steps when something goes wrong
- Critique their own intermediate outputs before proceeding
- Adapt execution strategies based on what they discover mid-task
This shift from deterministic pipelines to adaptive loops marks the difference between AI that occasionally works and AI you can actually depend on.
How the agentic loop simplified everything
The original prompt router was essentially a traffic cop. It examined incoming requests, classified intent, and directed queries to the appropriate prompt template. Simple and effective, but limited - and it still required engineers to anticipate every path.
Modern implementations have embraced a radically simpler pattern: the canonical agent architecture is just a while loop with tools. Instead of complex orchestration, the agent repeatedly calls the LLM, checks if it wants to use a tool, executes that tool, and feeds the result back. The model itself decides the sequence of actions.
This pattern wins because it's simple, composable, and flexible enough to handle complexity without becoming complex itself
Reflexion loops cut hallucination rates
Self-correction through reflexion loops has become one of the most practical techniques for improving reliability. The pattern is straightforward: instead of delivering the first output a model generates, you force the system to critique its own work before the user ever sees it.
A typical implementation uses two distinct model instances. The generator produces an initial response. The evaluator then analyzes that output against a rubric, checking for logical consistency, factual grounding, or compliance with specific requirements. When the evaluator finds problems, it generates natural language diagnostics and routes the state back to the generator for refinement.
Best practices for implementing reflexion loops include:
- Defining clear evaluation criteria before building the loop, not after
- Using a specialized high-accuracy model for the evaluator role, often a smaller model fine-tuned for judgment tasks
- Setting explicit iteration limits to prevent infinite loops on genuinely hard problems
- Logging evaluation feedback alongside generated outputs for debugging
This pattern dramatically reduces hallucination rates by catching errors internally. The model essentially double-checks itself before responding.
Simpler architectures are winning
The temptation in agent design is to account for every possibility with specialized tools and careful constraints. Teams at the forefront are discovering the opposite works better.
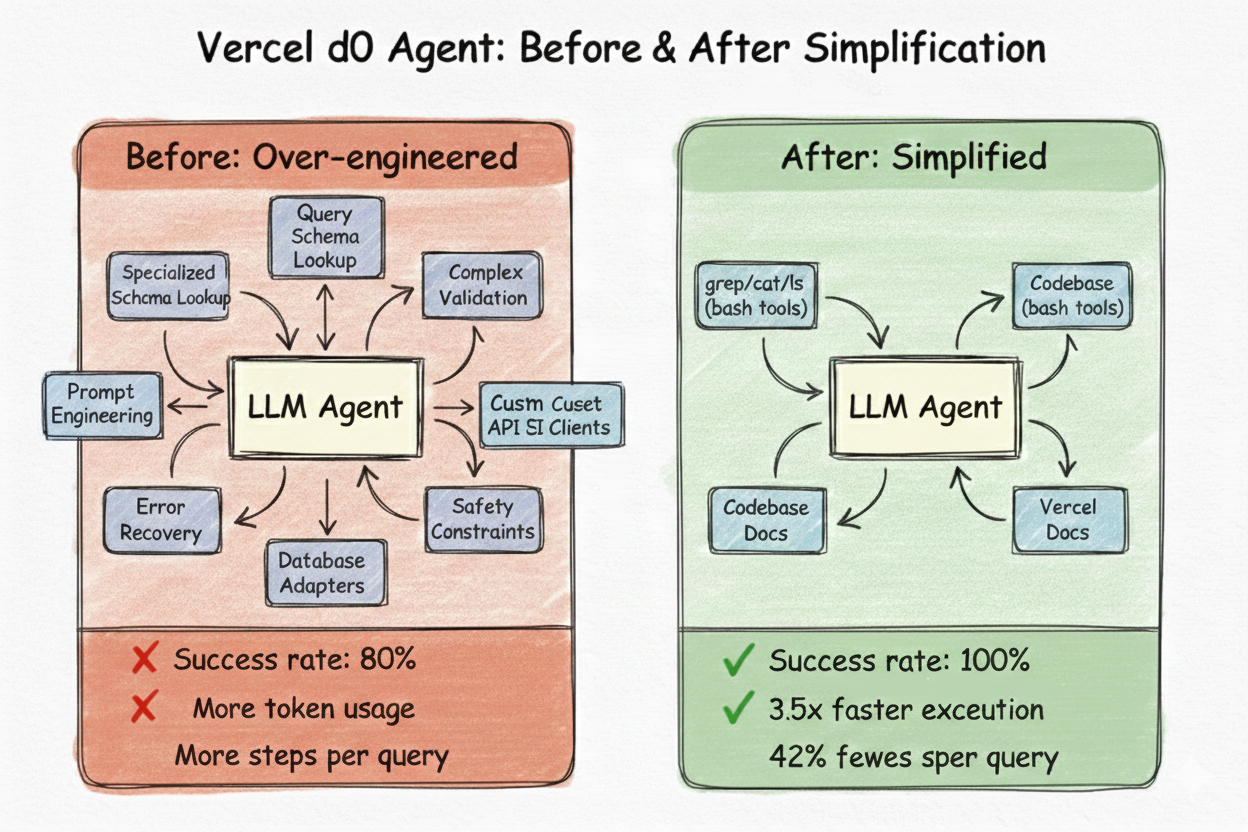
Vercel's internal data agent, d0, spent months with sophisticated tooling: specialized schema lookup, query validation, error recovery, and heavy prompt engineering to constrain the model's reasoning. It worked - kind of. But it was fragile, slow, and required constant maintenance.
Then they tried something different. They deleted 80% of the tools and gave Claude direct access to browse files using bash commands like grep, cat, and ls. The results:
- Success rate: 80% to 100%
- Execution time: 3.5x faster
- Token usage: 37% fewer tokens
- Steps per query: 42% fewer steps
"We were fighting gravity," the team wrote. "Constraining the model's reasoning. Summarizing information that it could read on its own. Building tools to protect it from complexity that it could handle."
This aligns with Anthropic's guidance: "When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed." The pattern emerging across successful implementations is clear: give the model good context, well-designed tools, and get out of its way.
Two shifts made this possible
The move toward simpler agent architectures isn't just a design philosophy - it's newly viable because of two converging advances.
More powerful models. Today's frontier models can handle complexity that would have overwhelmed their predecessors. Larger context windows mean agents can read entire codebases or documentation sets without aggressive summarization. Better reasoning capabilities mean the model can navigate ambiguity without hand-holding. What required careful engineering guardrails a year ago often works out of the box today.
Better prompt engineering techniques. The craft of working with LLMs has matured beyond trial-and-error tweaking:
- Dynamic context injection using templating systems like Jinja2 lets prompts adapt to each request, inserting only relevant information
- Sophisticated tool calling enables models to interact with APIs, databases, and file systems with structured inputs and outputs
- File system access allows agents to explore and reason about code and data directly, rather than relying on pre-processed summaries
This is Occam's razor in practice: the simpler design is better, and now the simpler design actually works. Teams no longer need elaborate scaffolding because the underlying capabilities have caught up with the ambition.
Build agents that stay simple
Clever prompts can raise the ceiling, but architecture sets the floor. The most reliable LLM systems emerging today share a common trait: they embrace the minimal agentic loop rather than fighting against it.
A good next step is straightforward: pick one high-value path in your product and build it as a simple loop. Give the model access to the tools it needs, set clear termination conditions, cap iterations, and log the trajectory. Resist the urge to add specialized tooling until you've proven it's necessary.
Once you trust your model to reason through problems on its own, prompt engineering stops being a craft of constraint and starts being a craft of enablement. The goal isn't to think for the model - it's to give the model what it needs to think for itself.


