Prompt Repetition Improves Non-Reasoning LLMs: Google's New Study

Prompt Repetition Improves Non-Reasoning LLMs: Google's New Study
Sometimes the most effective prompt engineering tricks are the simplest ones. A recent paper from Google researchers reveals that merely repeating your prompt - literally copying and pasting it twice - can dramatically improve LLM accuracy on non-reasoning tasks. No fine-tuning, no complex chains of thought, no architectural changes. Just say it twice.
This kind of finding catches our attention at PromptLayer because it reinforces something we've observed repeatedly: small, systematic changes to prompt design often matter more than elaborate techniques. The researchers tested this across seven models and seven benchmarks, finding consistent improvements with zero degradation. For teams working on prompt optimization, that's a compelling signal worth understanding.
Doubling your prompt can dramatically change results
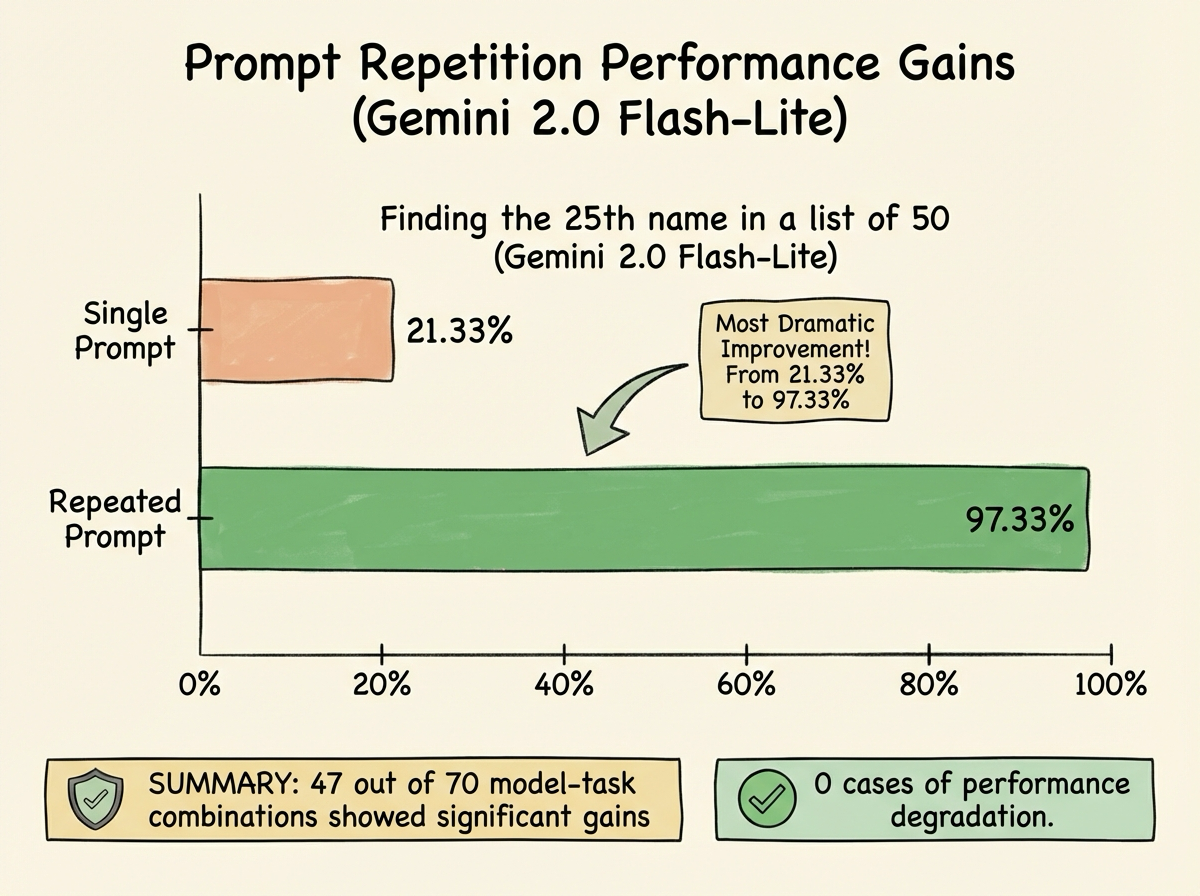
The core finding is striking in its simplicity. When researchers took a single query and appended an identical copy, accuracy jumped significantly across a wide range of tasks. The most dramatic example came from a list-indexing challenge where a model needed to find the 25th name in a list of 50. Gemini 2.0 Flash-Lite went from 21.33% accuracy to 97.33% - just by asking the same question twice.
The improvements held up broadly:
- 47 out of 70 model-task combinations showed statistically significant accuracy gains
- Zero cases of degraded performance across all tests
- Models tested included Gemini 2.0, GPT-4 variants, Claude 3, and DeepSeek V3
- Tasks ranged from general knowledge QA to math word problems and custom list puzzles
The biggest wins appeared when relevant information came before the actual question - like multiple-choice options listed ahead of what's being asked. In those cases, the second pass helped models correctly connect earlier context to the later query.
Crucially, this technique doesn't increase output length or add meaningful latency. The model reads a longer prompt but still produces a single, normal-length answer. You get accuracy improvements essentially for free.
Why reading twice helps a causal model
The explanation lies in how transformer-based LLMs process text. These models read strictly left to right, with each token only attending to earlier tokens. They can't look ahead. So when important context appears before the question, the model processes that context without knowing what will matter later.
Think of it like a student skimming a dense passage before seeing the question at the end. On first read, they don't know what to focus on. But if they read it again knowing the question, they can connect the right details.
Prompt repetition gives the model that second chance. On the repeated portion, tokens can attend to everything from the first instance - including the question the model has now seen. This lets the model integrate context it initially processed without the benefit of hindsight.
The researchers confirmed this mechanism by testing with irrelevant padding of similar length. That didn't help at all. It's the meaningful repetition that matters, not just longer input.
When to use this trick and when to skip it
The practical appeal here is obvious - prompt repetition is a drop-in enhancement requiring no model changes, no output format adjustments, and no architectural modifications. We've been thinking about this at PromptLayer in the context of how teams iterate on prompts, and the simplicity is genuinely rare.
Consider using prompt repetition when:
- Tasks involve recall or lookup where the model likely has the knowledge but stumbles in execution
- Straightforward Q&A where complex reasoning isn't required
- Prompts front-load context before the actual question
- Direct answers are expected rather than step-by-step explanations
However, repetition shows minimal benefit when reasoning is already enabled. With chain-of-thought prompting, models essentially rephrase the question internally as they work through steps. The explicit second copy adds little new information - tests showed only 5 wins versus 22 ties in reasoning scenarios.
The rule of thumb: if your task is non-reasoning in nature, try repeating the prompt. If it requires logical deduction or multi-step planning, focus on proper reasoning prompts instead.
Make "say it twice" your first experiment
If there's a theme here, it's that leverage doesn't always look like sophistication. In the right settings, copying a prompt and pasting it again can turn a shaky one-shot answer into something close to reliable - with no output bloat and no meaningful latency hit.
So the next time a model clearly knows the material but keeps missing on execution, run the simplest A/B test you can: ship the exact same prompt twice, measure it, and keep it if it holds. And if you want the deeper mechanics and benchmarks, the paper is worth a quick read... it might change how you structure your next prompt.


