Opus 4.6 - PromptLayer Team Review

Claude Opus 4.6 landed in February 2026, and the AI community has been buzzing about whether it lives up to the hype. Writing from the PromptLayer team, we've spent considerable time testing this release across coding workflows, long-document analysis, and agentic pipelines. The verdict? Opus 4.6 represents a genuine leap forward for complex, sustained work - though it comes with trade-offs worth understanding before you commit. This review breaks down what actually changed, how it performs in practice, and whether it deserves a spot in your production stack.
What changed under the hood
The headline feature is the context window expansion - from 200,000 tokens in Opus 4.5 to a full 1 million tokens in the new release. That's roughly 800,000 words in a single prompt, enough to ingest entire codebases or multi-hundred-page documents without chunking strategies.
Several other improvements stand out:
- Adaptive Thinking Mode replaces the older Extended Thinking feature. You can now dial reasoning effort from low to max, letting simpler tasks complete quickly while complex problems get deeper analysis.
- Agent Teams enable parallel sub-agent coordination. A lead agent can break projects into subtasks and delegate to teammates working concurrently - a step beyond the single-subagent approach of 4.5.
- Output capacity doubled to 128K tokens, removing the ceiling that truncated long generations in previous versions.
- Context Compaction automatically summarizes older conversation history, helping maintain coherence across extended sessions.
Coding received particular attention. Anthropic refactored the architecture specifically for programming reliability, and it shows. The model plans code changes more carefully, navigates large codebases with less confusion, and catches its own mistakes more consistently.
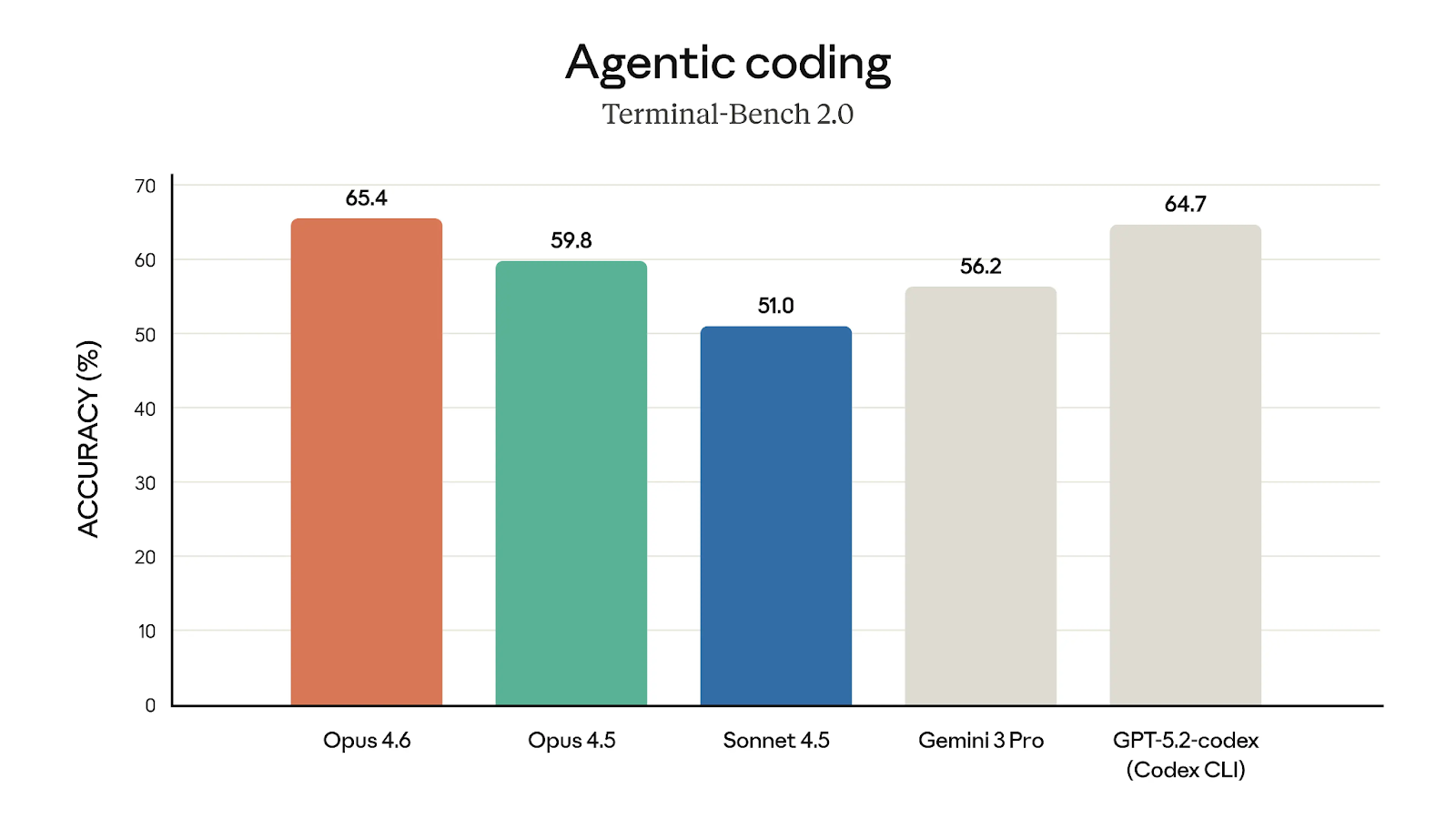
How benchmarks tell the story
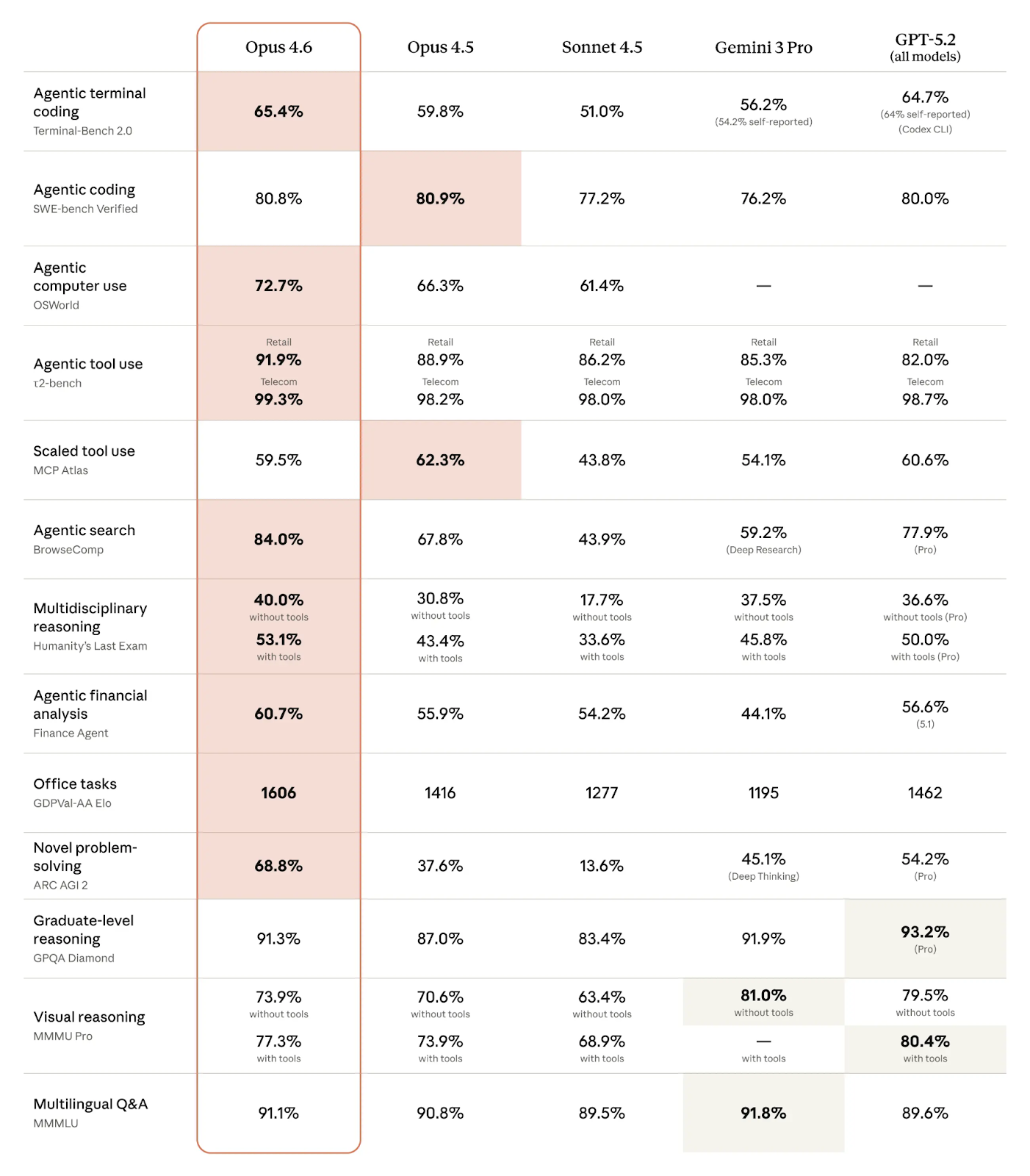
The numbers paint a compelling picture. On ARC-AGI v2 - a challenging reasoning benchmark - Opus 4.6 scored 68.8% accuracy compared to 4.5's 37.6%. That 31-point jump suggests a qualitative improvement in handling novel, multi-step problems.
Long-context retrieval shows even more dramatic gains. On Anthropic's internal MRCR v2 test using 1M tokens, Opus 4.6 achieved 76% accuracy. The predecessor managed just 18.5%. The model genuinely utilizes that massive context window rather than just accepting the tokens and losing them.
Competitive positioning matters too. On GDPval-AA - an evaluation measuring performance on economically valuable tasks in finance and law - Opus 4.6 scored 1606 Elo, outpacing GPT-5.2's 1462 by a meaningful margin. For coding-specific benchmarks like Terminal-Bench 2.0, it hit 65.4%, up from 59.8% for the previous version.
One tester reported Opus 4.6 solved 87.5% of their coding tasks on the first attempt versus 62.5% for 4.5. Another ran 20 different real-world tasks and found 4.6 won 18 head-to-head comparisons.
What early adopters are actually saying
The reception has been enthusiastic but nuanced. Launch partners like Notion, GitHub, and Replit praised the model's ability to handle ambitious requests autonomously. Notion's AI lead described it as "less like a tool and more like a capable collaborator" that breaks complex requests into concrete steps and follows through.
Developers consistently highlight improved planning and persistence. Claude 4.6 proactively identifies subtasks, asks clarifying questions when needed, and carries projects to completion without constant hand-holding. One Reddit user tested UI generation and found 4.6 could one-shot complex app interfaces that required multiple iterations with 4.5.
However, creative writing remains a sore point. Multiple users noted that prose feels terser and more matter-of-fact compared to 4.5's more vibrant output. The reinforcement learning that sharpened reasoning apparently dulled some creative flair. If you need whimsical stories or highly stylized content, 4.5 might still be your better option.
The free-tier experience has also drawn complaints. Because Opus 4.6 thinks more deeply and uses larger contexts by default, users hit message caps faster. Several commenters noted they exhaust their allowance quickly, prompting frequent upgrade nudges.
Where enterprises are putting it to work
Adoption in enterprise settings has been swift. Notion powers its AI assistant with 4.6 for content creation and organization. GitHub Copilot offers it as an option for multi-step code generation. Replit uses it for agentic planning in their cloud IDE environment.
The integrations extend beyond developer tools:
- Claude in Excel received upgrades for better data analysis and natural language spreadsheet generation.
- Claude in PowerPoint launched in preview, creating slide outlines and suggesting visualizations.
- Security auditing has emerged as a compelling use case - Anthropic's team used Opus 4.6 to identify over 500 previously unknown high-severity vulnerabilities across open-source repositories.
For developers building with the API, pricing remained unchanged at standard tiers - $5 per million input tokens and $25 per million output. Extended context beyond 200K tokens triggers premium rates at $10 and $37.50 respectively, but most workloads fall within the standard tier.
The 1M context window opens possibilities that were previously impractical. One Hacker News user fed four Harry Potter novels into a single prompt and retrieved 49 of 50 targeted facts. Whether that's training data leakage or genuine retrieval, it demonstrates the potential for massive document analysis in research, legal review, and financial auditing.
Is it worth the switch
Opus 4.6 is the “get it done” Claude. If your day-to-day involves sprawling repos, long documents, or agentic workflows that need planning and follow-through, the upgrade is hard to ignore - the 1M window and stronger reasoning change what’s feasible in a single run.
But don’t treat it like magic. It will happily spend tokens thinking, and it can feel a little too serious in prose, so keep the effort dial in your toolbox and keep 4.5 around if style is the goal.
If you’re considering a switch, make it a measured one: run your own task suite, track costs and latency, and compare first-pass success rates. Then ship the winner. Benchmarks are a signal, your production traces are the decision.


