Multi-agent collaboration via evolving orchestration

Most multi-agent AI systems today follow rigid scripts. One agent handles step one, another handles step two, and the sequence never changes regardless of what the task actually requires. A new NeurIPS 2025 paper challenges this entirely, introducing a "puppeteer-style" paradigm dynamic orchestration paradigm. Instead of fixed workflows, a central orchestrator learns to select which agent should act at each moment based on the evolving state of the problem.
We've been watching this shift closely at PromptLayer - the move from static prompt chains toward adaptive, learning-based coordination feels like a natural evolution of how teams are building with LLMs. The paper's results suggest this direction yields better outcomes with lower computational cost, which matters a lot when you're managing complex workflows at scale.
What makes the puppeteer framework different
The core insight is treating multi-agent coordination as a sequential decision problem rather than a predetermined pipeline. At each step, the orchestrator observes everything that has happened so far and decides which agent should contribute next. This creates an implicit reasoning graph shaped by the problem itself, not by what a developer anticipated upfront.
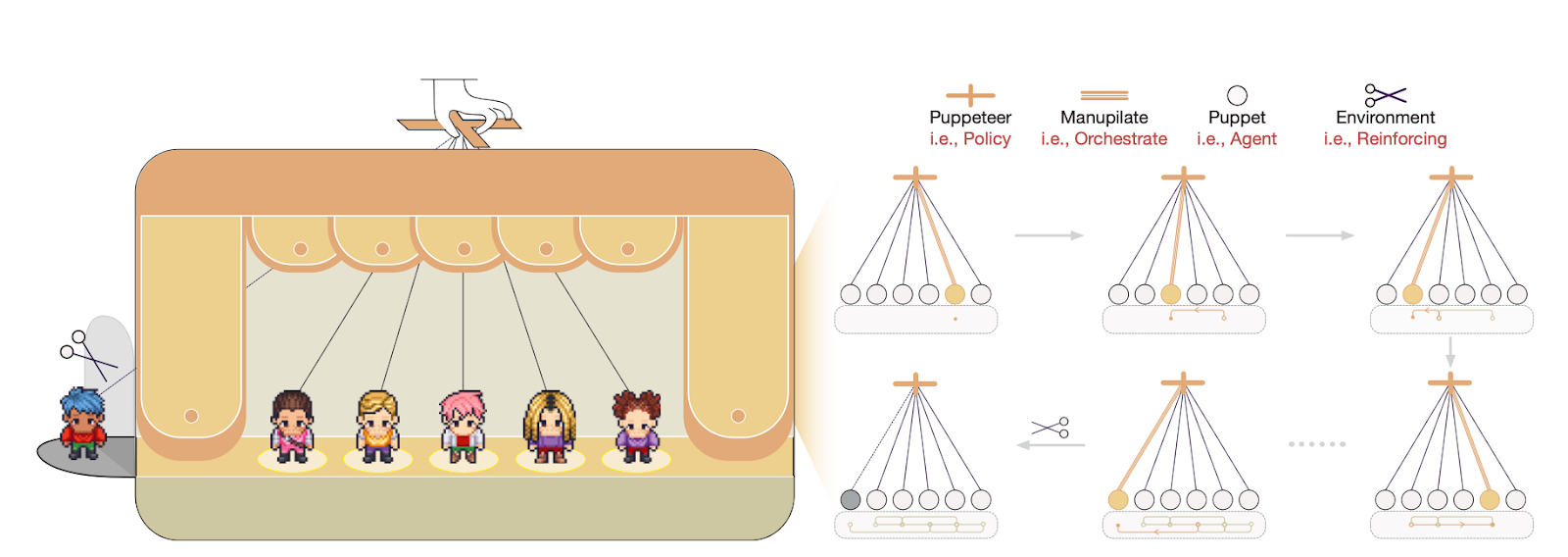
Three contributions stand out:
- Dynamic selection replaces fixed sequences: The orchestrator acts as a policy network, routing tasks to agents based on context. If a simpler agent can handle a subtask, it gets called. If complexity escalates, a more capable model takes over. The system builds coordination patterns on the fly rather than following a script.
- Reinforcement learning drives improvement: The orchestrator trains using policy gradients, receiving rewards that balance solution quality against computational cost. Over many trials, it learns to prune redundant steps and favor compact reasoning chains. This means the system gets better at collaboration with experience - not just at individual tasks, but at the meta-level of deciding how to collaborate.
- Performance gains without efficiency tradeoffs: Across math problems, knowledge-intensive questions, and creative generation tasks, the puppeteer system consistently outperformed both single-agent approaches and prior multi-agent frameworks with fixed structures. Even when all agents used the same base model, orchestrated coordination beat a single model working alone. Mixing agent capabilities - smaller models alongside larger ones - pushed accuracy higher while the learned cost penalty kept token usage in check.
The emergent behavior is particularly interesting. As training progressed, agent interactions shifted from disorganized back-and-forth into structured cycles and graph-like workflows. The system essentially discovered efficient teamwork patterns without anyone explicitly programming them.
Why this matters for prompt orchestration
Platforms focused on prompt management and agent workflows stand to benefit directly from these ideas. Today, building a multi-step LLM application typically means manually designing the sequence - deciding which prompt handles which part, hardcoding conditional logic, and iterating through trial and error when something underperforms.
Dynamic orchestration suggests a different model:
- Adaptive routing based on task state: Rather than fixed chains, workflows could learn when to escalate to a more powerful model or when a cheaper call suffices. API costs drop when the system recognizes that brute-force reasoning isn't always necessary.
- Automatic optimization from usage data: The orchestrator's reward signal incorporates both success metrics and efficiency measures. A platform already tracking latency, token consumption, and error rates has the raw material to close this feedback loop, letting the system refine its own strategy rather than waiting for manual redesign.
- Reduced burden on prompt engineers: If orchestration logic can be learned rather than specified, developers focus more on defining goals and less on anticipating every possible task path. Complex agent architectures become tractable without requiring exhaustive upfront planning.
Thi s aligns naturally with observability-first approaches enabled with tools like PromptLayer. When you can see which prompts underperform and which agent handoffs cause friction, you have the inputs an RL-based orchestrator needs to improve.
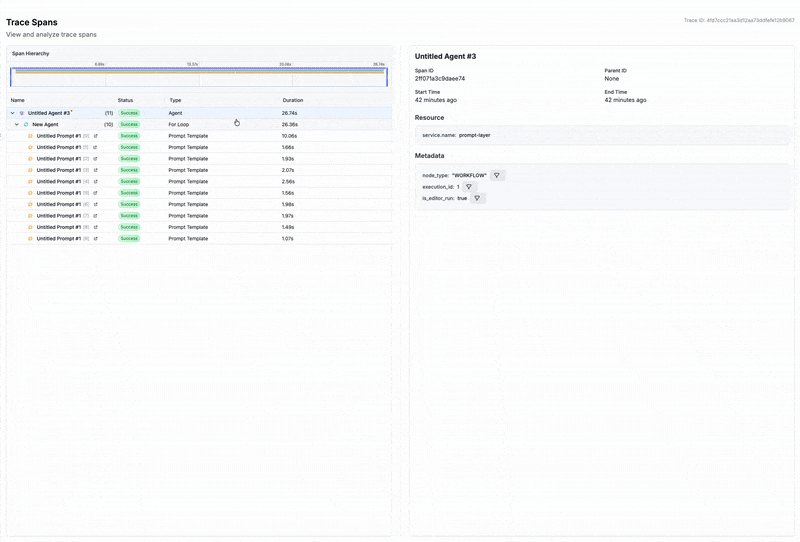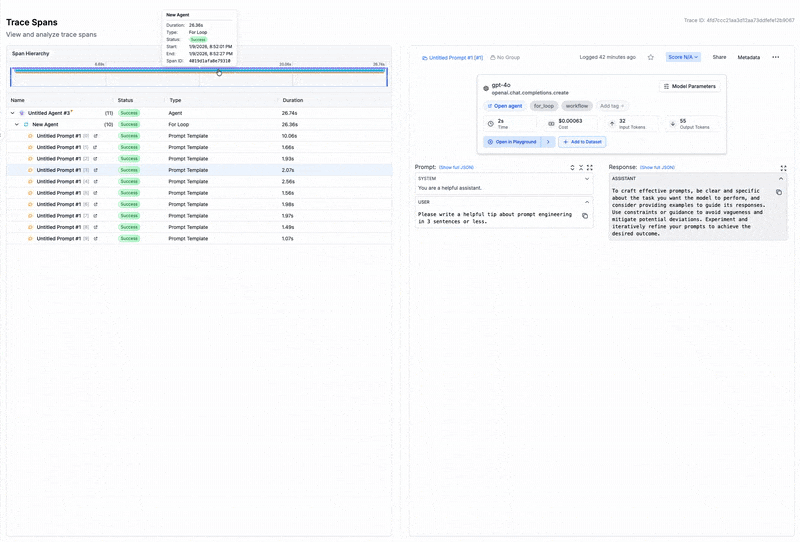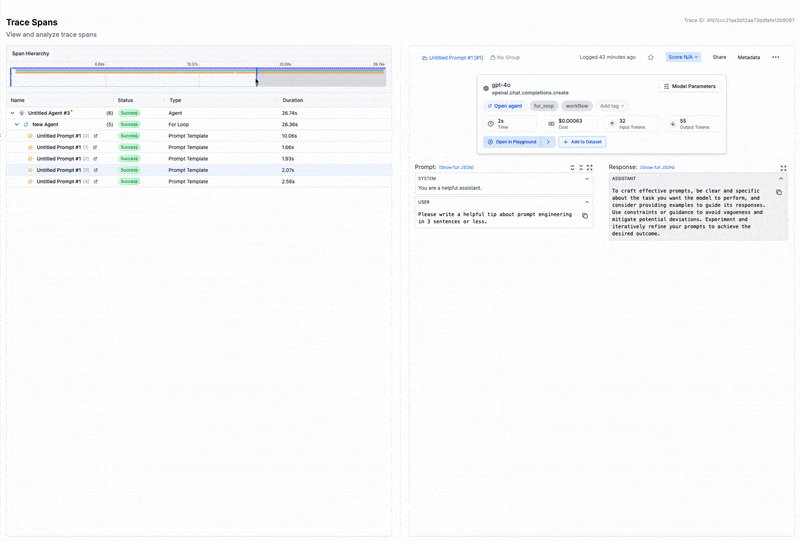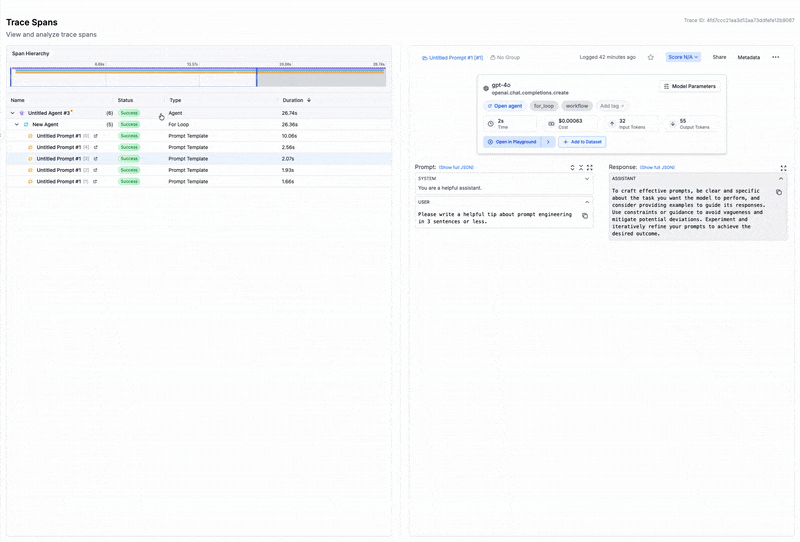
The underlying building blocks
Several concepts converge in this framework:
- Prompt engineering remains essential - the quality of individual agent prompts still determines what each step can accomplish - but the orchestrator handles how those prompts compose.
- Agent workflows provide the substrate. Chains of model calls, conditional branches, and tool integrations form the action space the orchestrator selects from.
- Reinforcement learning supplies the optimization mechanism, treating coordination as a problem of maximizing expected reward under cost constraints.
- Observability closes the loop. Without visibility into what each agent produced and how long it took, there's no signal for learning.
The paper demonstrates that when these pieces connect properly, coordination quality improves without requiring ever-larger models or ever-longer reasoning chains.
The real shift: stop scripting, start learning
The exciting part here isn't just "multi-agent, but better." It's the idea that coordination itself can be trained - a policy that learns when to call a cheap agent, when to escalate, and when to stop, all while staying anchored to real cost and quality signals.
If you're building agentic workflows today, the takeaway is simple: treat your chains as a starting point, not an end state. Instrument everything, define the reward you actually care about, and start experimenting with orchestration that adapts in production. The teams that win won't be the ones with the longest graphs, they'll be the ones whose systems learn the shortest path to the right answer.


