Model Analysis: OpenAI o1 vs Claude 3.5

OpenAI's o1-preview has garnered a lot of attention for it's reasoning since it's launch in September. In contrast, Anthropic's Claude 3.5 Sonnet, released in June, has had users excited for it's speed and updated capabilities. While both models are impressive in their own right, they focus on different focus areas.
The o1-preview model marks a leap in reasoning and problem-solving capabilities. It builds on the foundation of GPT-4o with a focus on enhanced cognitive processing.
Claude 3.5 Sonnet is optimized for creativity, speed, and conversational interactions. It's marked an advancement in content generation and coding tasks.
Let's explore these models in more detail, comparing their functionalities, strengths, and the specific scenarios in which each model excels.
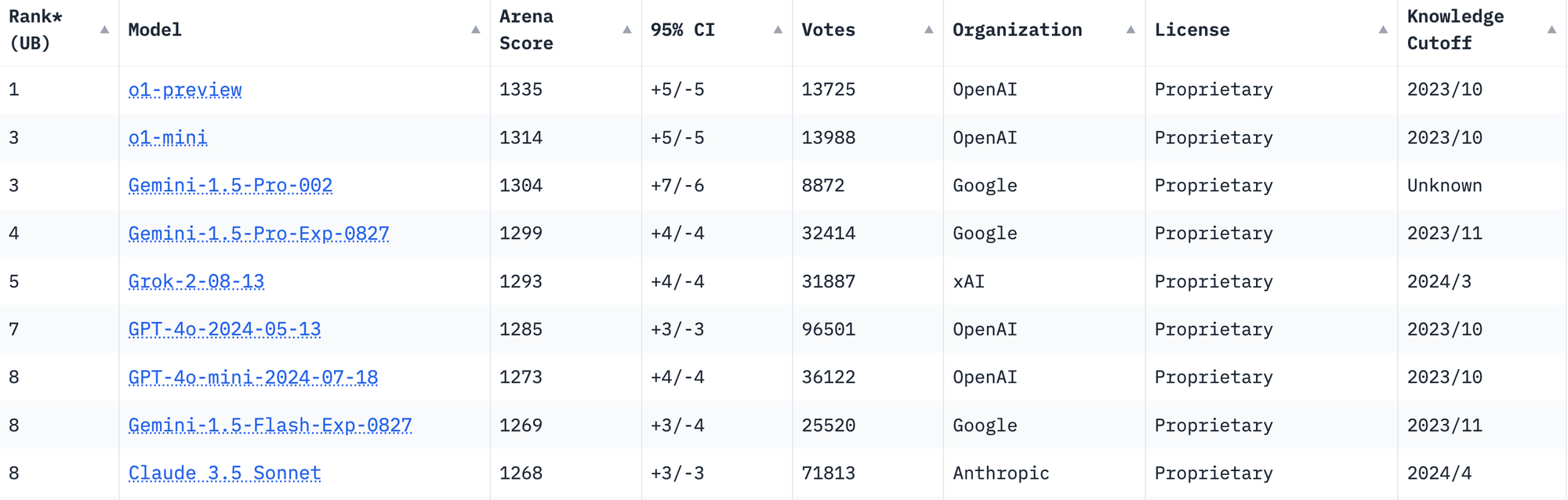
OpenAI o1 vs Claude 3.5 | LLM Arena
The LLM Arena leaderboard is a great place to turn when a new model is released.
Its leaderboard showcases the performance rankings of different language models. They compare how a model scores across different benchmarks and tasks and give scores on how models perform. This can show you how a model stacks up against other models, in terms of capabilities and accuracy.
The o1-preview ranks first and Claude 3.5 Sonnet is tied for 8th on the leaderboard as of today.
Comparing OpenAI o1 vs Claude 3.5
To understand the differences in these models, let’s look at the costs, capabilities, specifications, and specializations for each model side-by-side.
Comparative Analysis: O1-preview vs. Claude 3.5 Sonnet
| Feature/Aspect | O1-Preview (OpenAI) | Claude 3.5 Sonnet (Anthropic) |
|---|---|---|
| Release Date | September 12, 2024 | June 20, 2024 |
| Primary Use | Advanced reasoning, math, science, coding | Content generation, fast coding, creativity |
| Reasoning Capability | Uses a deep "chain of thought" for complex analysis | Simplified problem-solving, more suited to rapid prototyping |
| Coding Capabilities | Backend, multi-step debugging, thorough analysis | Front-end development, rapid bulk code generation |
| Content Creation | Detailed, explanatory outputs | Highly engaging, creative, human-like responses |
| Context Window | 128,000 tokens | 200,000 tokens |
| Output Token Limit | 32,768 tokens | 4,096 tokens |
| Latency and Speed | Longer response times due to extended thinking | Faster response times, lower latency |
| Pricing | $15 per million input tokens, $60 per million output tokens | $3 per million input tokens, $15 per million output tokens |
| Ideal For | Academic research, deep coding analysis, PhD-level math | Marketing, creative writing, rapid prototyping, everyday use |
One of the most important differences is in the cost of o1 and Claude 3.5.
Let's compare the increases in input and output tokens cost when going from Claude 3.5 to o1-preview:
| Transition | Input Tokens Cost Increase | Output Tokens Cost Increase |
|---|---|---|
| Claude 3.5 Sonnet to o1-preview | 400% increase (5× higher) | 300% increase (4× higher) |
*Please note that when using these models directly in ChatGPT or Claude, you are not charged per token. The cost analysis presented here pertains solely to API usage.
PromptLayer lets you compare models side-by-side in an interactive view, making it easy to identify the best model for specific tasks.
You can also manage and monitor prompts with your whole team. Get started here.
When to Use Claude 3.5 Sonnet and OpenAI o1-preview
Claude 3.5 Sonnet is great for efficient and creative tasks. Use it for tasks like content writing, marketing copy, and front-end coding. In these areas, speed, conversational quality, and cost-effectiveness are crucial. The larger context window allows Claude 3.5 Sonnet to handle longer conversations or documents effortlessly.
On the other hand, OpenAI o1-preview is best for complex reasoning and problem-solving. It's higher token limits cater to deep reasoning, like scientific research, advanced coding, and mathematics. The model's approach delivers detailed, well-reasoned outputs for tackling challenging, multi-step problems.
OpenAI o1-preview excels in tasks involving complex reasoning and decision-making, but comes at a higher cost compared to the more cost-effective Claude 3.5 Sonnet. If you need creativity, speed, and affordability, Claude 3.5 Sonnet offers a the best solution.
Example prompts analyzing performance of OpenAI o1 vs Claude 3.5
Let's look over some example prompts that highlight the differences:
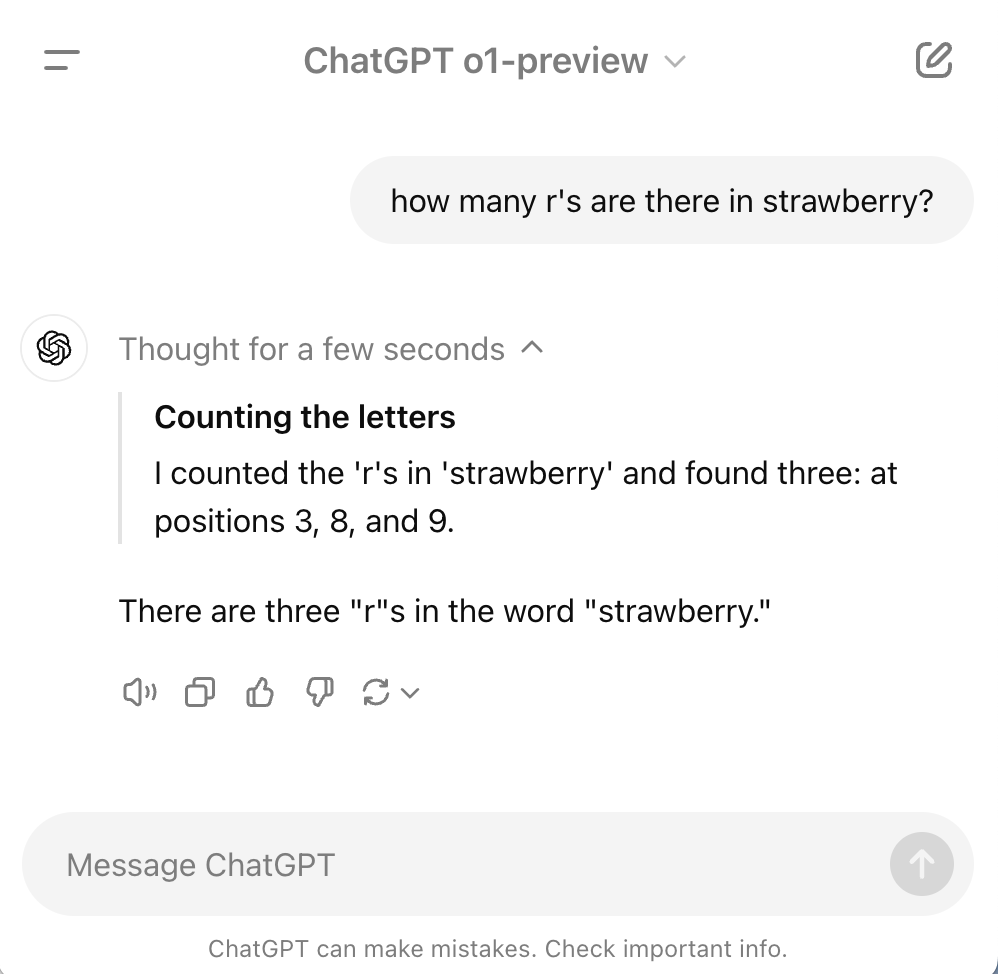
1. The 'Strawberry' test
Prompt:
How many r's are there in strawberry?
Explanation:
This is a simple evaluation used to assess the ability of LLMs to perform basic character-level task. While language models excel at generating text based on patterns they've learned, they can struggle with precise, low-level operations like counting individual letters.
How o1 responds:
How Claude 3.5 responds:
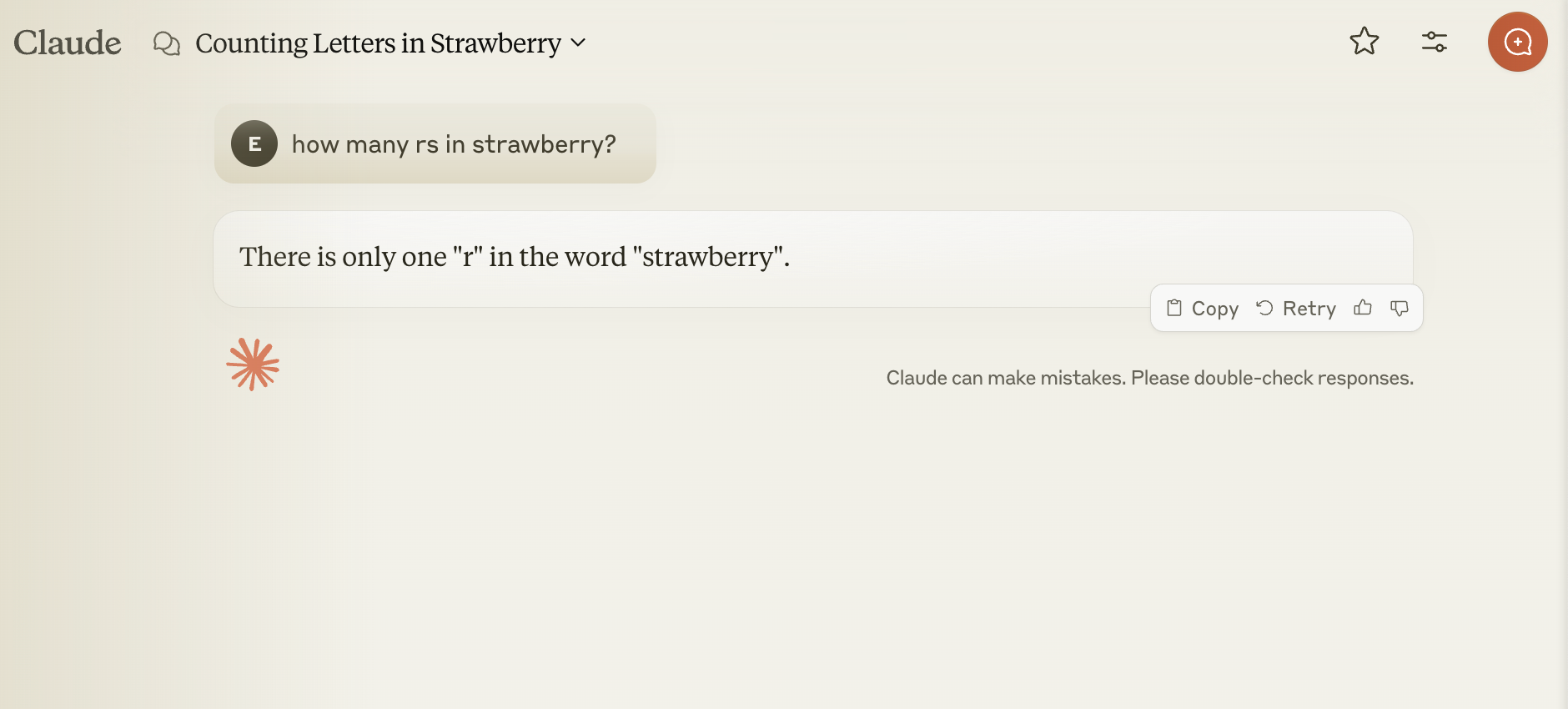
The o1 model examines each character to generate the correct result. In contrast, Claude 3.5 is optimized for efficiency and speed leading to a quick but inaccurate answer.
2. Math puzzle
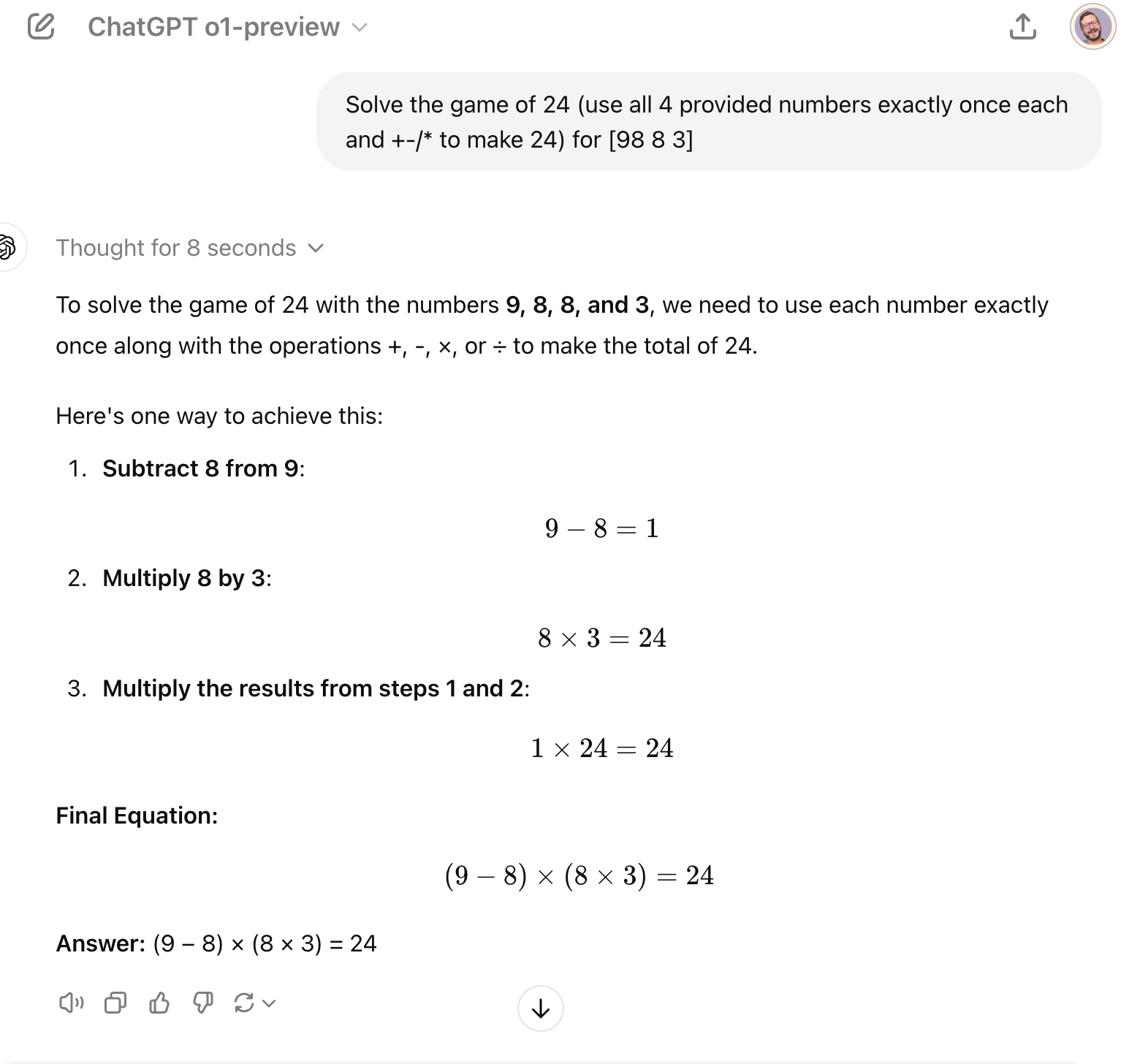
Prompt:
Solve the game of 24 (use all 4 provided numbers exactly once each and +-/* to make 24) for [9 8 8 3]
Explanation:
This a mathematical puzzle that challenges the models to use all four numbers exactly once, combining them with basic arithmetic operations (addition, subtraction, multiplication, division) to reach the total of 24.
It serves as an example to illustrate the difference in how these models handle complex reasoning and problem-solving tasks.
How o1 responds:
How Claude 3.5 responds:
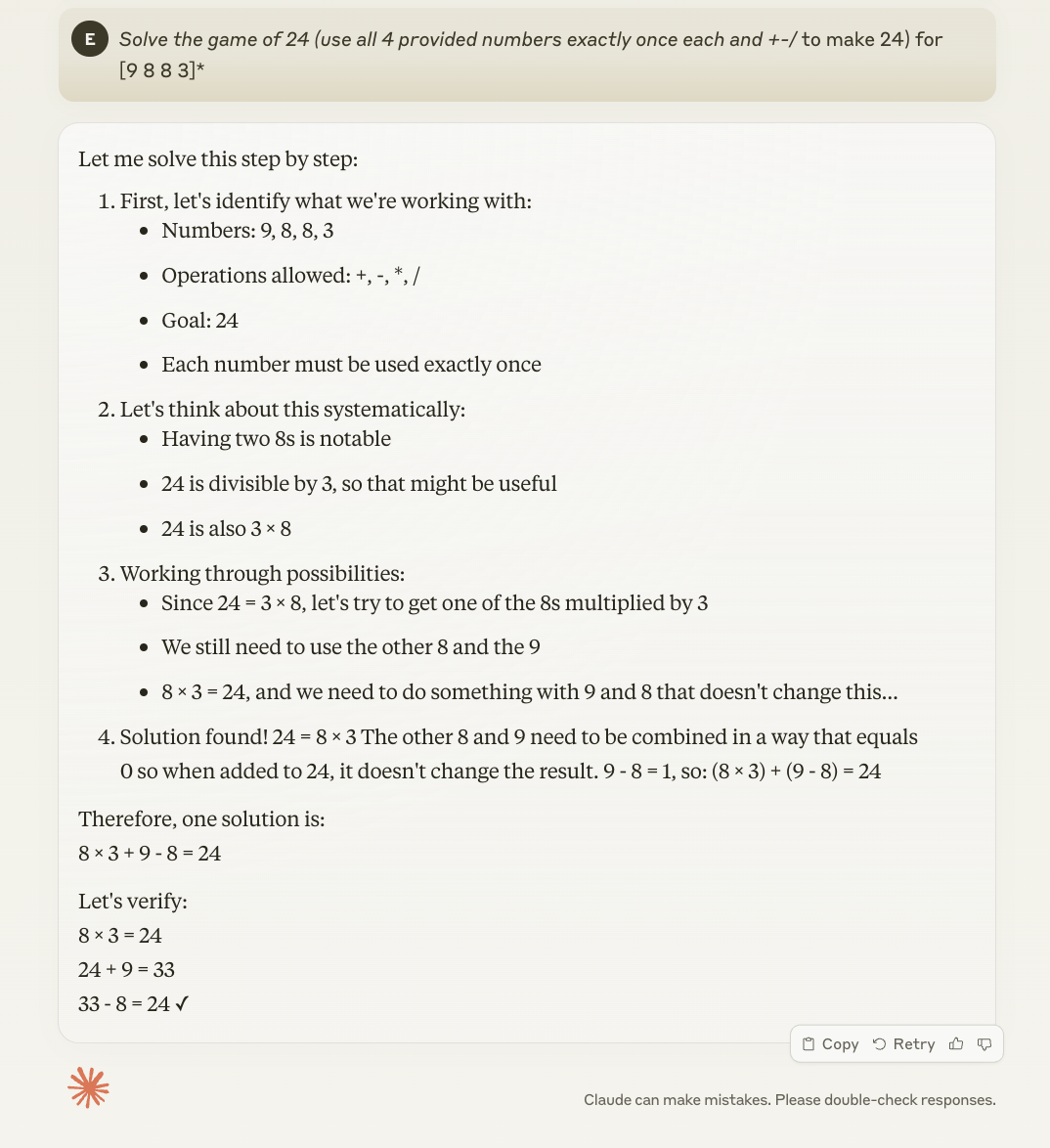
The o1 model breaks down the process, explores solutions, and then provides a step-by-step answer that is accurate.
Claude 3.5 prioritizes a faster response but does not verify that it's solution is correct. Here we see a hallucination where it claims 33 - 8 = 24. In fact, 33 - 8 is 25.
3. Creative Concept Generation for a Mobile Game
Prompt:
Provide a list of 10 creative concepts for a new mobile game targeting teenagers, incorporating elements of fantasy and strategy.
Explanation:
This is a simple prompt that requires the models to generate unique ideas. The user's goal is for a quick brainstorm of concepts, not a fully thought out game.
How Claude 3.5 responds:
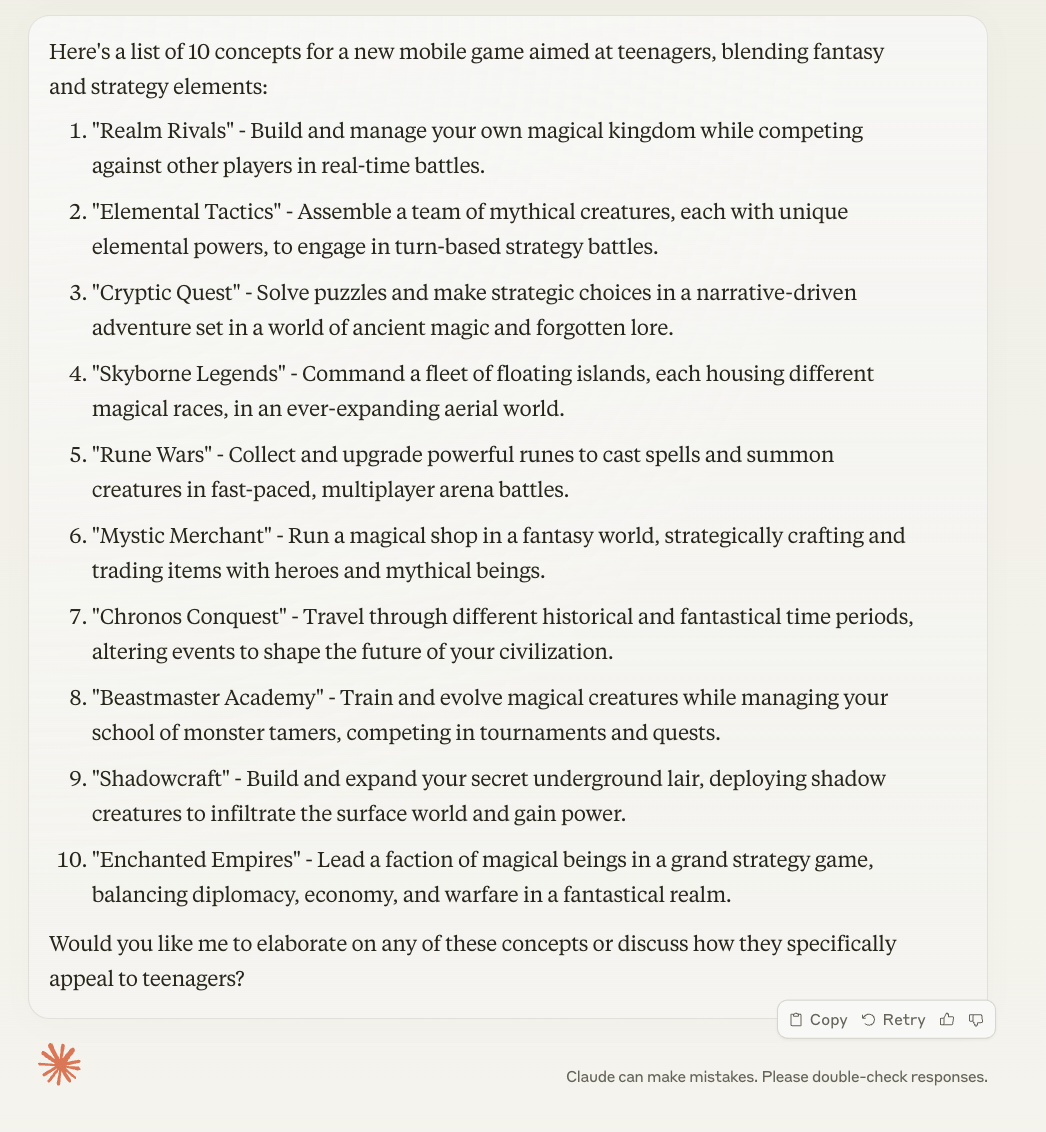
How o1 responds:

While both models offer strong options, Claude 3.5's efficiency and cost-effectiveness make it a better choice for this type of task.
Conclusion:
Choosing between OpenAI o1 and and Claude 3.5 truly depends on your needs and budget.
O1-Preview is ideal for users needing complex reasoning, comprehensive problem-solving, and in-depth code analysis. It excels at difficult tasks in math, science, and backend software development and bears a high cost per token.
Claude 3.5 Sonnet is the better option for content generation, cost efficiency, and rapid prototyping. Its affordability and speed make it suitable for everyday use, creative industries, and applications that need quick and engaging responses.
About PromptLayer
PromptLayer is a prompt management system that helps you iterate on prompts faster — further speeding up the development cycle! Use their prompt CMS to update a prompt, run evaluations, and deploy it to production in minutes. Check them out here. 🍰


