LLM Evaluation Fundamentals: Our Guide for Engineering Teams

Moving from the realm of traditional software testing to evaluating LLMs presents a unique set of challenges and opportunities for modern engineering teams. Below, we delve into the nuanced world of LLM evaluation, exploring the best practices, common obstacles, and effective techniques that are shaping the landscape today.
Why evaluating LLMs is more complex than it seems
Evaluating LLMs presents a distinctive challenge due to their probabilistic nature. While traditional software solutions are deterministic, making them relatively straightforward to assess, LLMs generate outputs that can vary significantly even with identical inputs. The magic (and the challenge) of LLMs lies in the fact that they must be evaluated not just for helpfulness, safety, and several loosely defined quality parameters.
Evaluating these models in a holistic manner requires an entirely different approach, one that often begins with simple "vibe checks" and matures into a robust testing ecosystem capable of supporting real-world applications.
Challenges in Defining and Evaluating LLM Output Quality
Defining "good output" in LLM systems is a multi-faceted problem. We must juggle competing demands like correctness, helpfulness, safety, and latency, all while maintaining a consistent tone. This subjectivity necessitates explicit rubrics - a standardized benchmark for qualities such as clarity and coherence.
Given the operational constraints surrounding human review and automated metric drift, a collaborative effort is crucial. Successful evaluation outcomes rely on a harmonious blend of insights from engineering, product, and domain experts.
The fall of traditional metrics for open-ended tasks
Traditional metrics struggle to encapsulate the full richness of LLM outputs due to the possibility of multiple correct answers. While academic benchmarks, such as those developed for language model understanding, offer a baseline for general capability, they often correlate poorly with performance in specific applications. This mismatch highlights the need for custom evaluations that align with specific business and safety goals.
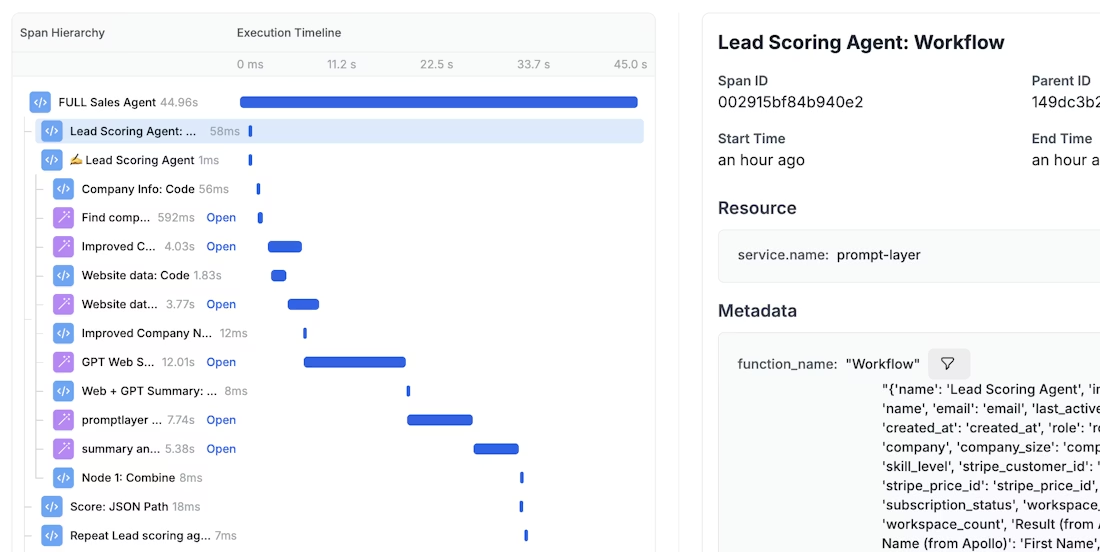
Traces as the foundation
To evaluate anything authentically, we require observability. Traces, which capture everything from inputs to final outputs, offer the necessary structured record of LLM behavior. These traces are indispensable for troubleshooting any failures in an LLM's process - whether they are errors in planning, retrieval, execution, or summarization.
Offline vs. online evaluation strategies
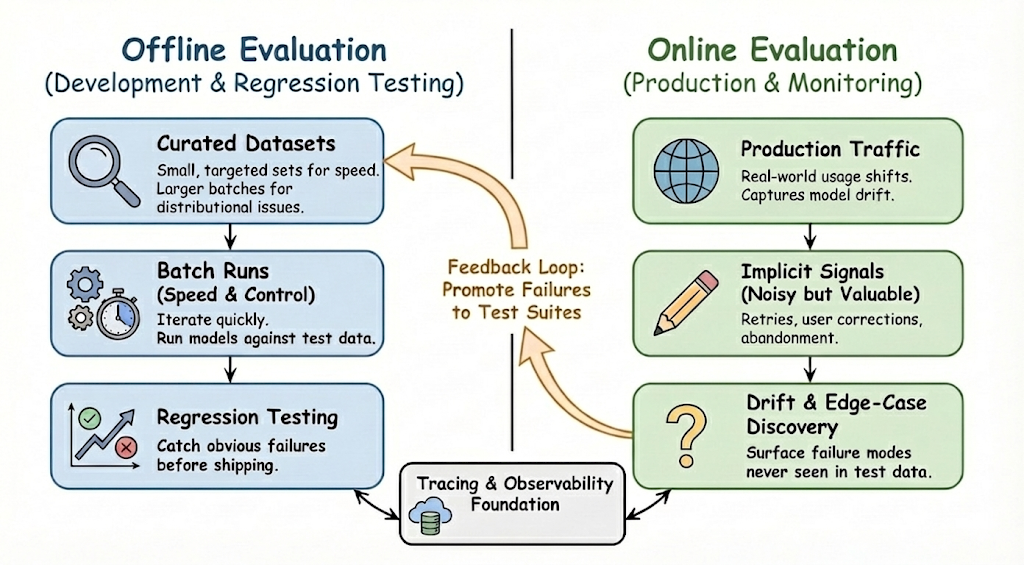
LLM evaluation usually spans two complementary modes: offline and online. Each serves a different purpose and becomes more powerful when used together.
Offline evaluation focuses on speed and control. By running models against curated datasets, teams can iterate quickly during development and perform regression testing before shipping changes. Small, targeted test sets are effective at catching obvious failures, while larger batch runs help surface subtle distributional issues. As real-world usage shifts, these datasets must be refreshed regularly to stay representative.
Online evaluation, by contrast, reflects how the system behaves in production. It captures model drift, long-tail edge cases, and failure modes that never appear in test data. Implicit signals - such as retries, user corrections, or abandonment - provide noisy but valuable indicators of quality. Strong evaluation systems close the loop by promoting production failures back into offline test suites, turning real incidents into future safeguards.
Practical evaluation techniques and when to use them
No single metric or method can capture LLM quality. Effective evaluation combines human judgment, automated signals, and application-aware checks, each used where it adds the most value.
Human-driven signals
Human input remains the gold standard for judging nuanced qualities like usefulness, tone, and safety - but it comes with scale and cost constraints.
- Explicit user feedback provides high-quality, task-specific insight, but is sparse and hard to operationalize.
- Implicit human-in-the-loop signals (edits, retries, abandonments) scale better, though they require careful interpretation.
- Human annotation delivers deep insight for complex or high-risk tasks, making it ideal for creating golden datasets - even if it’s expensive.
Automated signals
Automated evaluations provide speed, consistency, and coverage - but only when grounded in human judgment.
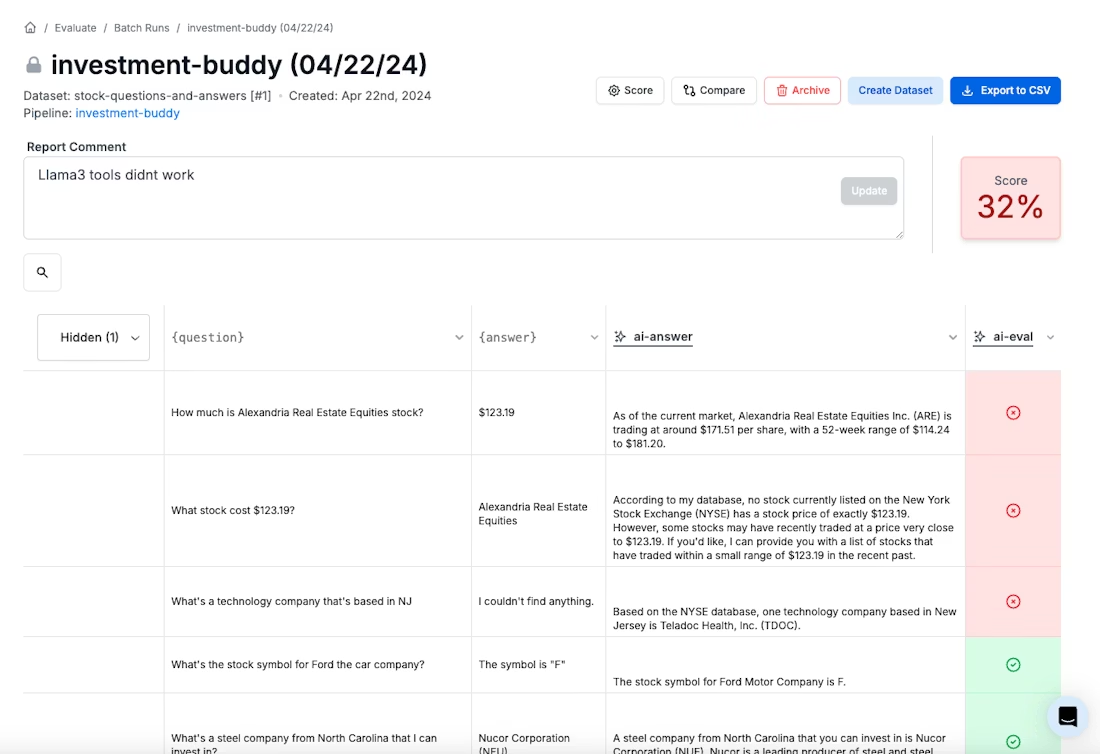
- LLM-as-judge uses models to score or rank outputs in ways that approximate human evaluation, enabling fast iteration across large test sets.
- Embedding-based similarity measures semantic overlap when exact matches aren’t possible.
- Rule-based and deterministic checks enforce safety, formatting, and hard constraints.
In practice, LLM-as-judge workflows work best when tightly integrated with trace data, prompt versions, and side-by-side comparisons. Platforms like PromptLayer make this operational by allowing teams to run structured evals over logged traces, compare judges across prompt or model variants, and track score changes over time - without building custom evaluation plumbing.
Application-aware evaluation
Different system architectures introduce different failure modes, and evaluations should reflect that reality.
- RAG systems benefit from separate evaluation of retrieval quality and generation quality, making it easier to pinpoint where failures originate.
- Agentic systems require evaluating more than the final output - intermediate plans, tool choices, and decision sequences often matter just as much.
Make evaluation your unfair advantage
Reliable LLM features stem from treating evaluation as an "always-on" product surface: instrumented, repeatable, and integrated into the CI/CD pipeline. This enables consistent regression detection as components evolve. Promote real user interactions to "golden datasets," and use versioning for safe iteration. Every production failure should become a new test case, replayed against future changes to steadily reduce risk. A platform like PromptLayer can help operationalize this by logging traces, versioning prompts, and backtesting changes to keep evaluation aligned with shipping cadence.


