LLM-as-a-Judge: Using AI Models to Evaluate AI Outputs

Evaluating AI-generated text remains a significant challenge. Traditional metrics often fail when dealing with open-ended tasks. And while human evaluation is considered the gold standard, it's often slow, costly, and hard to scale. Enter the concept of "LLM-as-a-Judge," a novel approach where large language models (LLMs) are used to evaluate the outputs of other AI systems. This idea has gained traction since the release of capable models like GPT-4, which successfully approximate human judgments in various tasks such as summarization and dialogue evaluation.
How we prompt LLM judges matters
Crafting prompts for LLMs to act as judges is trickier than simply asking the model which output is better. For effective evaluations, prompt design plays a crucial role, involving zero-shot and few-shot prompting, rubric design, and choosing an appropriate output format.
- Zero-shot vs. few-shot prompting: In zero-shot, we give minimal instructions, such as "Evaluate for correctness and clarity." Few-shot prompting involves showing examples of good or bad evaluations, which helps clarify criteria for the model. The examples' order and balance can significantly influence the model's judgment, and calibrating prompts can help mitigate bias.
- Rubric design and criteria: It's essential to define clearly what qualities are being evaluated. For example, is an output 'correct' if it accurately answers a query? Multiple criteria like accuracy, style, and completeness might need separate scoring to maintain focus and accuracy.
- Pairwise comparison vs. direct scoring: Pairwise comparisons involve choosing the better of two responses, useful for A/B testing. Direct scoring applies to a single output on a scale, which is harder to calibrate but is flexible for independent scoring.
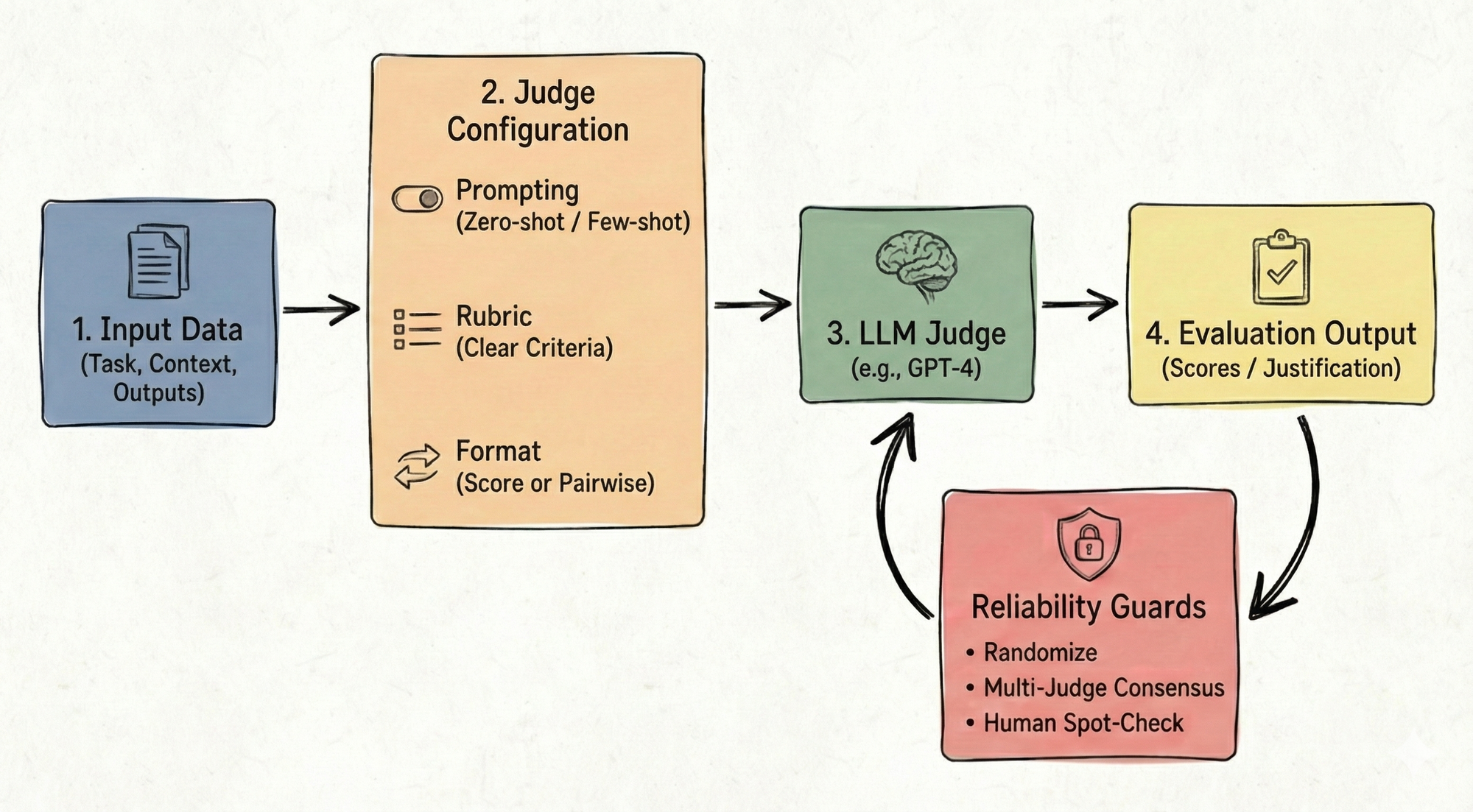
Comparing LLM-as-a-Judge to traditional methods
How does this new approach stack up against tried-and-true methods like human evaluation and traditional metrics?
- Human evaluation: While humans provide nuanced and context-rich assessments, this method is not scalable and can be inconsistent. LLM-as-a-Judge offers a fast, consistent alternative without the disadvantages of fatigue and subjective variance.
- Automated metrics: These struggle with the flexibility and creativity of modern AI outputs. Moreover, they don't correlate well with human preferences. LLM judges provide a flexible, reference-free evaluation method, often aligning more closely with human judgment.
Known biases and reliability issues
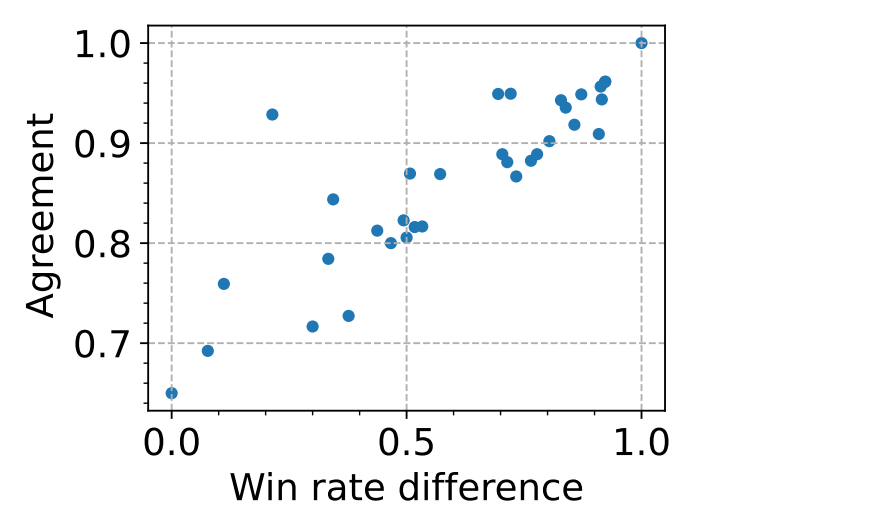
The efficacy of using LLMs as judges also raises questions about reliability and bias. Research indicates strong LLM judges like GPT-4 align with human opinion about 80% of the time. However, LLMs can show positional bias, verbosity bias, and self-enhancement bias. They might favor longer answers or those generated by the same model family. Strategies like randomizing response orders or using multiple judges can mitigate these biases.
Real-world applications are expanding
From summarization to complex question answering, the use of LLM-as-a-Judge spans various domains:
- Text summarization: As traditional metrics often fall short, LLM-as-a-Judge provides more reliable assessments by considering multiple dimensions like fluency and accuracy.
- Code generation: LLM judges help evaluate code outputs beyond mere compilation, considering semantic correctness through code review and logic assessment.
- Dialogue evaluation: Multi-turn conversations pose challenges that LLM judges help overcome by rating response quality, helpfulness, and even detecting user frustration.
Emerging research in AI evaluation
As this field evolves, several exciting directions are gaining attention. Researchers are exploring AI feedback for aligning models with human values, increasing the reliability of self-evaluations, and probing adversarial vulnerabilities of AI judges. There's also a push for developing multi-modal evaluators capable of handling text and image combinations.
Put evaluation on rails
When a strong model can agree with humans a large share of the time on open-ended preferences, you get something we’ve been missing for years: a scalable way to iterate quickly without flying blind on quality.
But don’t confuse “scalable” with “settled.” Judges can be biased toward position, length, and even their own model family, and they can be nudged by the way you frame the prompt. The teams getting real value here treat LLM judging like any other measurement system: calibrate it, randomize what can be randomized, and spot-check it with humans - especially in high-stakes domains.
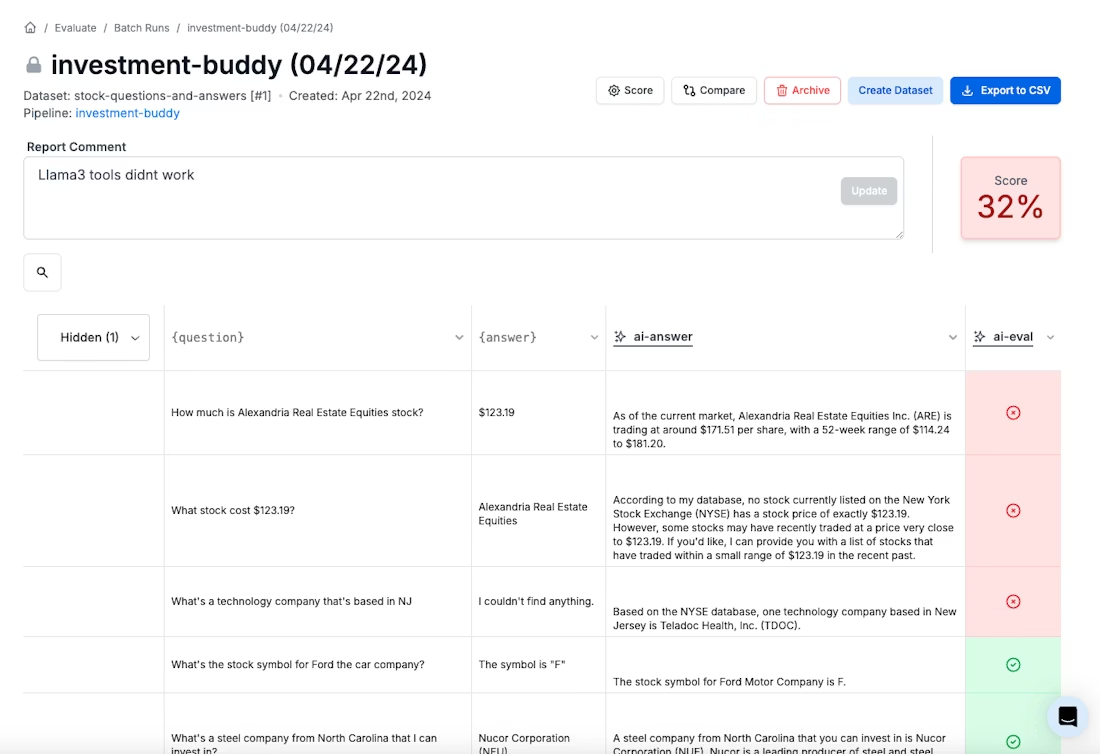
If you’re building with LLMs today, the call-to-action is simple: put evaluation on rails. Start with one workflow (A/B prompt tests or regression checks), write a crisp rubric, and run it through an evaluation layer like PromptLayer. Then harden it: add order randomization, keep scores low-granularity, and bring in a second judge when the decision matters. The faster you can trust your feedback loop, the faster your system gets better.


