Is Opus smarter than Sonnet? Opus vs. Sonnet

The question of which AI model is "smarter" depends entirely on what you need that intelligence to do. At PromptLayer, we spend a lot of time watching how different models perform across real workflows. Both models come from Anthropic's Claude family, but they serve fundamentally different purposes. Opus is built for maximum reasoning depth, while Sonnet prioritizes speed and practical efficiency. Understanding where each excels can transform how you build and deploy AI systems.
Opus wins the reasoning benchmarks
When raw intelligence is the metric, Opus pulls ahead consistently. The most striking example comes from ARC-AGI-2, a benchmark generalization. Opus 4.5 scores 37.6% on this test, nearly three times better than Sonnet 4.5's 13.6%. That gap matters because ARC-AGI-2 specifically measures how well a model handles problems it has never seen before, the kind of abstract reasoning that separates sophisticated analysis from pattern matching.
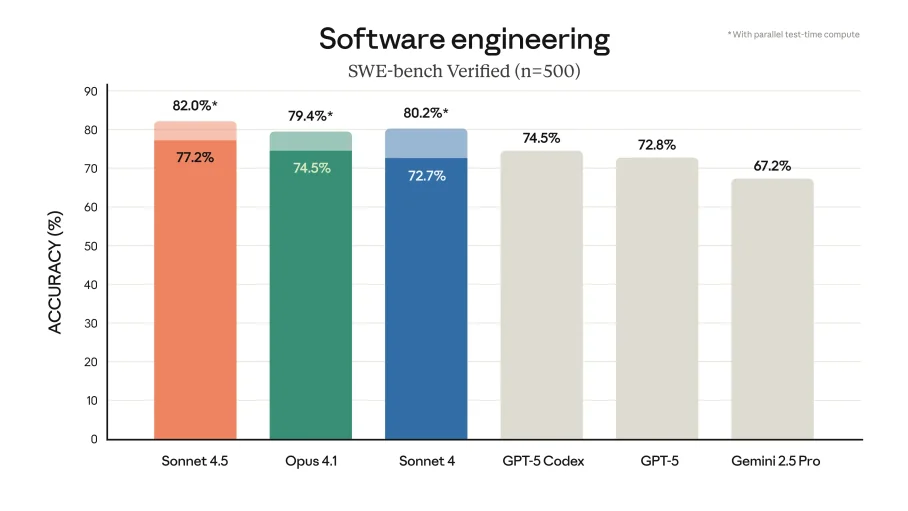
Opus 4.5 also demonstrates a clearer advantage in practical coding, particularly in software engineering tasks. On the SWE-bench Verified benchmark, Opus 4.5 scored 80.9%, outperforming Sonnet 4.5, which achieved 77.2%. The newer Opus 4.6 pushes even further with a 32% improvement in agentic coding scenarios, multi-file autonomous work.
Where this matters most:
- Research and development requiring novel problem-solving
- Strategic planning with ambiguous inputs
- Complex multi-step analysis where errors compound
- Autonomous agent workflows managing interconnected systems
Opus also uses tokens more efficiently on hard problems, planning shorter solution paths despite its higher per-token cost. On app development tasks, Opus consumes 19.3% fewer total tokens than Sonnet, which can offset the pricing difference in specialized scenarios.
Sonnet delivers where speed matters
Sonnet's design philosophy trades some reasoning depth for dramatically better throughput. Operating at twice the speed of previous Claude models while costing 40-60% less per token, Sonnet becomes the obvious choice when responsiveness drives value.
The practical implications show up immediately in interactive applications. Chatbots, IDE autocompletion, real-time content generation, and customer support systems all benefit from Sonnet's faster responses. When users are waiting, latency matters more than marginal improvements in reasoning quality.
Sonnet also introduced a 1M token context window in beta, enabling work with massive codebases or document collections that would otherwise require chunking and summarization. While context utilization (76% versus Sonnet's 18.5% on long-context benchmarks), Sonnet's raw capacity opens doors for certain applications.
Best applications for Sonnet include:
- Content generation at scale
- Customer support automation
- Rapid prototyping and iterative development
- High-volume data summarization
- Browser-based operations and cross-file debugging
In one real-world test content marketing synthesis, Sonnet 4.5 actually outperformed Opus 4.1, extracting 4-5 strategic insights from 12 sources versus Opus's 2-3, with smoother prose. The lesson is that benchmarks do not capture everything.
Balancing cost and capability
The pricing gap between these models is substantial. Sonnet 4.5 costs $3/$15 per million input/output tokens, while Opus 4.5 runs $5/$25 and Opus 4.6 jumps to $15/$75. That difference compounds quickly at scale.
Smart teams are adopting hybrid strategies that leverage both models strategically. The most effective pattern uses Sonnet for development and iteration, then routes to Opus for final review and complex reasoning steps. This approach can yield 60-80% cost savings compared to running Opus exclusively, without sacrificing quality where it counts.
Haiku might be better for preparation and simple formatting tasks. Sonnet might be ideal for development, testing, and handling volume work. Opus might be better reserved for review, complex analysis, and high-stakes decision-making.
The key insight is that Opus's higher upfront costs sometimes result in lower total ownership costs. Because it uses fewer tokens on difficult problems and produces more accurate results on the first pass, you spend less on retries and corrections. For workflows involving strategic planning or autonomous agents, the math can favor Opus despite the price tag.
Pick the model, then pick the moment
Opus handles the hard stuff better - novel problems, multi-step reasoning, tasks where sloppy thinking means starting over. Sonnet is fast, cheap, and more than capable for the bulk of everyday work.
So don't debate which is "better." Both models have real strengths, and the smart move is matching each one to the right job. Route your high-volume, iterative tasks to Sonnet. Bring in Opus where the extra depth actually saves you retries and cleanup. Treat model selection as an architecture decision, not a religious one, and your costs and outputs will both improve.


