Humans Last Exam LLM: A Comprehensive Evaluation

Top AI models that ace traditional benchmarks are stumbling badly on a new test called "Humanity's Last Exam," scoring a mere 25%. This dramatic performance gap reveals just how far we still are from achieving expert-level artificial intelligence, despite the impressive capabilities of today's large language models.
Humanity's Last Exam represents a new frontier in AI evaluation, an ultra-hard benchmark specifically designed to identify when machines can truly match human expertise across diverse fields. Created through a collaboration between the Center for AI Safety and Scale AI, this benchmark emerged from a critical need: earlier tests had become too easy, failing to distinguish between increasingly powerful models. We'll explore how HLE works, examine current model performance, understand the critiques it has faced, and unpack why this benchmark matters for the future of AI development.
What HLE Is and How It Was Built
The origins of Humanity's Last Exam trace back to conversations among AI leaders who recognized a pressing problem. By 2024, leading models were achieving over 90% accuracy on established benchmarks like MMLU, rendering these tests essentially useless for measuring further progress. Elon Musk was among those who noted this saturation effect, spurring Dan Hendrycks (CAIS) and Alexandr Wang (Scale AI) to spearhead the creation of a genuinely challenging alternative.
Announced in September 2024 and finalized in spring 2025, HLE underwent an extraordinarily rigorous development process. The creators issued a global call for the toughest questions imaginable, offering a $500,000 prize pool and co-authorship opportunities to attract top talent. The response was overwhelming: nearly 1,000 domain experts from over 500 institutions across 50+ countries contributed to the project.
The final dataset comprises 2,500 carefully vetted questions covering more than 100 subjects. The distribution reflects a strong emphasis on technical fields, with approximately 41% focusing on mathematics and 11% on biology. The remaining questions span physics, chemistry, computer science, humanities, social sciences, and engineering.
Format diversity adds another layer of complexity. About 14% of questions are multimodal, requiring interpretation of diagrams, scientific figures, or historical inscriptions. Roughly 24% use multiple-choice format, while the remainder demand precise short-answer responses. Every question is designed to have one objectively correct answer, eliminating ambiguity in scoring.
The vetting process was exceptionally stringent. From over 70,000 initial submissions, only questions that stumped state-of-the-art LLMs at chance levels advanced to expert review. Approximately 13,000 questions passed this initial filter, undergoing two rounds of PhD-level expert evaluation. Reviewers verified domain alignment, difficulty level, and answer precision, though they weren't required to exhaustively check reasoning if it took more than five minutes.
A community bug bounty in early 2025 provided additional quality control, identifying and removing problematic questions to arrive at the final 2,500-question set. The creators also maintain a private held-out test set to detect potential overfitting and ensure long-term benchmark integrity.
How HLE Scores Models
- Models receive points only for exact-match accuracy on each question, whether multiple-choice or short-answer
- This strict criterion ensures that partial credit or "close enough" answers don't inflate scores
- No points are awarded for partially correct responses
Confidence Calibration
- HLE measures calibration - how well a model's confidence aligns with its actual performance
- Each model reports a 0-100% confidence score with its answer
- Researchers calculate calibration error to assess whether models "know what they don't know"
- This metric reveals if models exhibit dangerous overconfidence in their responses
Ranking System
- The leaderboard uses a sophisticated "rank upper-bound" groups system at 95% statistical confidence
- This approach prevents minor performance differences from creating misleading rankings
- Separate leaderboards are maintained for text-only and full multimodal performance
- Vision capabilities are acknowledged to significantly impact performance on certain questions
Anti-Contamination Measures
- Questions are designed to avoid easily searchable content
- Periodic retesting with private held-out sets helps detect any data leakage into training corpora
- These measures ensure that improvements reflect genuine capability gains rather than memorization
- Vigilant monitoring prevents models from simply recalling answers from training data
How LLMs Are Doing Right Now
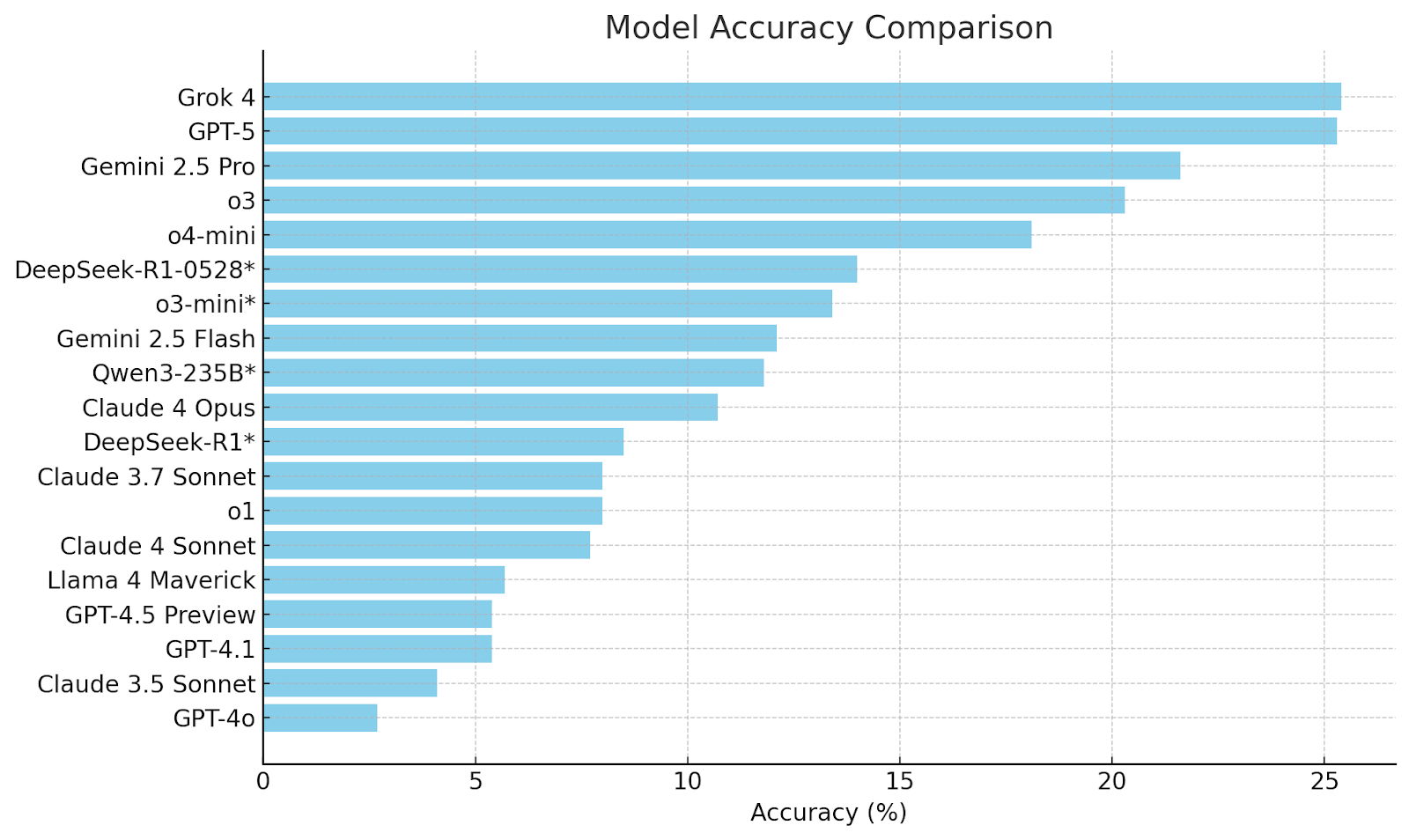
- Current state of performance: As of mid-2025, even the most advanced LLMs struggle to exceed 25% accuracy on HLE, painting a sobering picture of where the technology stands today.
- Leading the pack: xAI's Grok 4 currently holds the top position with approximately 25.4% accuracy, though this marginal lead highlights how challenging the benchmark remains.
- Close competition: GPT-5 follows closely behind at 25.3%, demonstrating that the frontier models are clustered tightly together with minimal performance gaps.
- Mid-tier performance: Google's Gemini 2.5 Pro hovers in the low 20s, representing solid but not breakthrough performance on this demanding benchmark.
- The mainstream gap: Many widely-used models continue to languish between 10-15% accuracy, revealing a significant performance divide between frontier and mainstream AI systems.
These numbers become even more striking when contextualized against performance on older benchmarks. The same models routinely achieve over 90% on MMLU, have rendered the ARC science test trivial, and have largely cracked BigBench Hard challenges. HLE's difficulty represents a quantum leap beyond these saturated tests.
Calibration errors compound the accuracy problem. Models frequently express high confidence in incorrect answers, indicating systematic overconfidence on challenging questions. This pattern suggests that current LLMs struggle to recognize the limits of their knowledge when facing expert-level problems.
Tracking calibration experiments systematically with platforms like PromptLayer helps researchers identify when models improve in both accuracy and self-awareness
Tool augmentation provides some improvement but falls far short of human expert performance. FutureHouse analysis found that Grok 4's accuracy on text questions jumps from 26.9% without web access to approximately 44% with search and internet tools. While significant, this boost still leaves models failing more often than succeeding on expert-level questions.
Looking ahead, HLE's creators anticipate rapid progress. They expect models to surpass 50% accuracy by the end of 2025. These projections reflect both the current pace of AI advancement and the benchmark's design as a moving target for capability measurement.
Why HLE Matters vs Earlier Benchmarks
Humanity's Last Exam addresses fundamental limitations in previous AI evaluation methods. Traditional benchmarks have become victims of their own success, with rapid AI progress rendering them obsolete as meaningful tests. MMLU scores jumped from 10% in 2021 to over 90% by 2024. The challenging MATH competition problems saw similar saturation within just a few years.
HLE distinguishes itself through several key features. First, it targets frontier knowledge requiring graduate-level understanding across diverse fields. Questions demand the kind of specialized expertise typically found in advanced research settings.
The multimodal elements set HLE apart from primarily text-based benchmarks. Scientific diagrams, mathematical figures, and historical inscriptions require integrated visual-textual reasoning, a capability poorly tested by traditional language benchmarks.
The adversarial, unsearchable nature of questions prevents simple retrieval strategies from succeeding. Unlike benchmarks that can be "gamed" through massive training data, HLE rewards genuine reasoning and knowledge synthesis.
Perhaps most importantly, HLE remains model-agnostic. Success doesn't depend on specific architectural choices but rather on fundamental capabilities: vast knowledge stores combined with sophisticated reasoning. This design ensures the benchmark's relevance regardless of future technical developments in AI systems.
Critiques, Revisions, and What HLE Doesn't Measure
Despite its ambitious goals, HLE has faced significant criticism for accuracy issues. FutureHouse researchers found 20-30% of biology and chemistry answers questionable when checked against published evidence, with errors like identifying oganesson as Earth's rarest noble gas despite it not being considered a terrestrial gas at all. The benchmark's intense focus on stumping AI incentivized convoluted questions that sometimes prioritized difficulty over accuracy, while the five-minute rationale verification limit allowed errors to slip through. Organizers acknowledged an approximately 18% error rate and instituted a rolling revision process to continuously remove problematic questions and add validated replacements.
HLE's scope limitations are intentional but significant. The benchmark exclusively tests closed-ended academic questions, excluding open-ended reasoning, creativity, social common sense, and dynamic planning capabilities. Hazardous domains are deliberately omitted for safety, while multimodal testing covers only static images, missing video or interactive graphics. Critics also note that HLE's dramatic framing can skew public perception—media coverage often implies that passing this "last exam" equates to achieving AGI, a claim the creators explicitly reject.
How to Use HLE Scores (Builders, Educators, Policymakers)
For AI developers, HLE serves as a critical progress tracker where sudden score improvements signal capability jumps requiring investigation, and performance gaps between text-only and multimodal modes highlight specific development needs. Policymakers find HLE valuable as a shared reference point for capability discussions, with specific thresholds like 50% accuracy potentially triggering oversight reviews or safety evaluations. Educators can take reassurance that advanced AI still cannot answer truly challenging off-the-books questions, preserving space for human expertise, though the benchmark prompts reflection on whether assessment should focus on problems that stump both students and AI or emphasize collaborative human-AI problem-solving. In hiring contexts, HLE performance serves as a proxy for technical interviews—a model scoring 25% isn't ready to replace domain experts, but one approaching 60-70% might meaningfully augment specialists.
Beyond the Current Scorecard
Humanity's Last Exam stands as a rigorous stress-test revealing the substantial gap between current AI capabilities and true expert-level performance. With top models achieving only 25% accuracy, HLE starkly illustrates how far we remain from artificial intelligence that can reliably match human expertise across diverse domains.
Yet HLE is more than just a humbling reality check. It provides the AI community with a clear, measurable target for progress while maintaining scientific rigor through continuous refinement. The benchmark's evolution, from 70,000 submissions to 2,500 carefully vetted questions, with ongoing revisions based on community feedback, demonstrates a commitment to accuracy over hype.
It's crucial to remember that passing HLE, even with high scores, represents a milestone rather than the finish line for AI development. The benchmark measures specific types of closed-ended expertise. As models improve and eventually surpass human performance on HLE, we'll need new benchmarks capturing different dimensions of capability, creativity, ethical reasoning, and real-world problem-solving.
For now, HLE serves its intended purpose admirably: providing a challenging, trustworthy measure of progress toward expert-level AI while keeping our expectations grounded in reality.


