How large organizations and enetrrpises standardize LLM benchmarks

As LLMs move from experimental projects into production systems handling real customer queries, financial decisions, and content generation, large organizations face a pressing question: how do you actually evaluate these models in a way that's consistent, comparable, and meaningful? Here at PromptLayer we've watched this challenge evolve as enterprises discover that "just run it through a benchmark" doesn't cut it when you're deploying models across dozens of teams, use cases, and risk profiles.
The complexity runs deeper than picking the right dataset. Organizations need to answer questions about which metrics matter for their specific workflows, how to reconcile public leaderboard scores with internal performance, and how to make evaluation repeatable enough that auditors and executives can trust the results. What emerges isn't a single benchmark but an entire evaluation discipline.
Standardization means agreeing on the process, not just the test
When large organizations talk about "standardizing" LLM benchmarks, they're rarely talking about picking one dataset and calling it done. Instead, standardization means defining a repeatable protocol that teams across the company can follow.
Mature enterprises typically adopt a layered evaluation stack:
- Public comparability layer: Broad academic benchmarks that let teams have informed conversations with vendors and establish baseline expectations
- Internal golden set layer: Curated tasks drawn from actual workflows, with stable scoring rules and clear pass/fail thresholds that drive real decisions
- Continuous regression layer: Short, cheap tests that run on every model or prompt change, functioning like unit tests for LLM behavior
- Risk and safety layer: Adversarial testing, policy compliance checks, and privacy/security evaluations that gate releases

This layered approach acknowledges a fundamental tension. Public benchmarks provide comparability across vendors and models, but they rarely capture what matters for a specific organization's use cases. Internal evaluations capture business reality but lack external validity - the solution is building infrastructure that supports both.
What goes into a benchmark protocol
The real work of standardization happens in the protocol details. Organizations that treat benchmarks as governance tools, not just technical artifacts, document several key components.
Task specifications define the intent, allowed inputs and outputs, success criteria, and edge case taxonomy. Prompting rules fix the templates, few-shot examples, and tool-calling policies so results are comparable across runs. Sampling settings lock down temperature, top-p, max tokens, and stop sequences - unless explicitly varied as part of the experiment.
Scoring mechanisms combine deterministic automated metrics where possible with calibrated human evaluation where needed. Statistical requirements specify confidence intervals, minimum sample sizes, and definitions of what constitutes a "material regression."
Documentation is equally critical. Borrowing from practices like Datasheets for Datasets and Model Cards, leading organizations create "benchmark cards" that capture what a test measures, what it doesn't, the scoring rules, and known failure modes. This documentation makes evaluations auditable and helps new team members understand why certain thresholds exist.
External frameworks increasingly shape what enterprises measure. The NIST AI Risk Management Framework has become a common anchor, prompting organizations to evaluate not just accuracy but validity, reliability, safety, privacy, security, and transparency. Regulated industries often map their evaluation dimensions directly to risk categories their auditors expect to see.
Running evals as software quality gates
For standardization to actually work, benchmarks can't live in research notebooks. They need to run in continuous integration pipelines with the same discipline applied to traditional software testing.
This operationalization involves several practices:
- Versioning: Datasets, prompts, and scorers are treated as code with proper version control
- Change control: Modifications to evaluations require review, and removing failing test cases demands written rationale
- Release criteria: Defined thresholds for quality, safety, and cost/latency budgets that must pass before deployment
- Monitoring dashboards: Trendlines by model version, task category, language, and user segment
Tools like PromptLayer, the LM Evaluation Harness, and OpenAI Evals demonstrate this "eval-as-code" philosophy, making it possible to integrate evaluation into existing engineering workflows rather than treating it as a separate research activity.
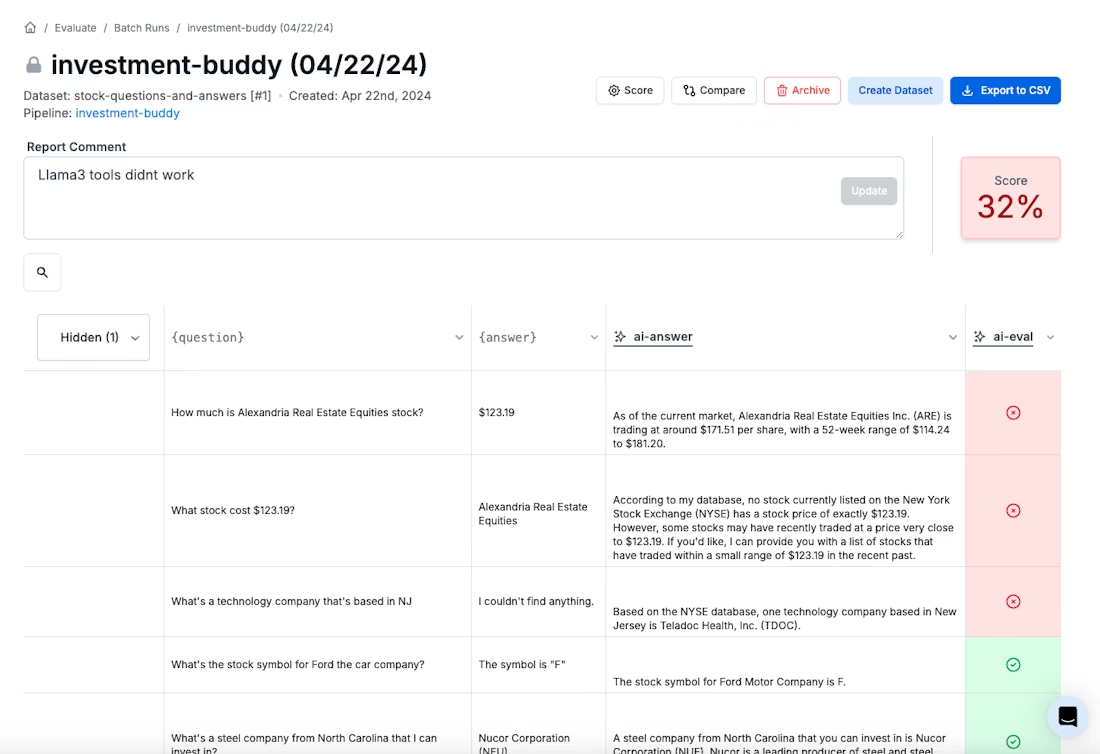
The practical benefit is significant. When a model update ships and customer satisfaction drops, teams can trace back to specific evaluation results. When executives ask whether a new vendor's model is ready for production, there's a documented answer based on predefined criteria rather than a subjective impression.
Pitfalls that undermine benchmark credibility
Even well-intentioned standardization efforts can fail. Several common pitfalls deserve attention.
- Data contamination occurs when models have been trained on benchmark data, making scores meaningless. This is increasingly difficult to detect with foundation models trained on web-scale corpora. Organizations mitigate this by maintaining truly private evaluation sets and regularly refreshing examples.
- Benchmark leakage happens when teams optimize prompts or fine-tuning specifically to pass internal tests without improving real-world performance. Clear separation between development and held-out evaluation sets helps, but requires discipline.
- Overfitting to proxy metrics is perhaps the subtlest problem. A model might score well on automated coherence metrics while producing outputs that users find unhelpful or off-putting. This is where human evaluation becomes essential - but human evaluation brings its own challenges.
Rater reliability varies dramatically depending on training, rubric clarity, and fatigue. Inter-rater agreement often goes unreported. Rubrics drift over time as raters develop shared intuitions that aren't documented. Organizations that take human evaluation seriously invest in rater calibration, regular agreement measurement, and rubric version control.
The benchmark stack is your LLM control system
In production, your LLM is a probabilistic system, not a deterministic one. That is exactly why standardized evaluation has to behave less like a one-time report and more like a control loop: every model change, prompt tweak, retrieval adjustment, or tool update should run through the same versioned gates, with results you can slice, explain, and defend.
If you want a practical starting point, pick one workflow and make it boring. Build a small golden set from real cases, lock the prompt and sampling settings, write down the rubric, and wire a cheap regression suite into CI. Then add the parts that keep you honest - held-out tests, calibrated human review, and risk and safety checks that actually block releases.
Benchmarks do not exist to win leaderboards. They exist to catch the silent failures before your customers do. Treat your evals like you treat security and uptime, and your org can ship LLMs with confidence instead of vibes.


