How OpenAI's Deep Research Works

OpenAI's Deep Research can accomplish in 30 minutes what takes human researchers 6-8 hours—and it's powered by a specialized reasoning model that autonomously browses the web, reads dozens of sources, and produces fully cited reports.
Deep Research represents a new category of agentic AI that doesn't just answer questions but actually researches them through iterative web searching, data analysis, and synthesis. Understanding how this autonomous research agent works opens the door to building similar systems that can automate knowledge work across domains.
What Deep Research Actually Is
Deep Research is an agent-like AI model originally built on OpenAI's o3 reasoning model, specifically trained for autonomous research tasks. Unlike traditional chatbots that provide quick answers from their training data, Deep Research actively searches the internet, analyzes information, and synthesizes findings into comprehensive reports.
The key capability that sets it apart is its ability to autonomously plan research strategies, search the web, analyze sources, and synthesize findings—all without human intervention after the initial prompt. Once you give it a research question, it independently figures out how to find the answer, spending up to 30 minutes gathering information and reasoning through the problem.
The output is impressive: comprehensive, citation-rich reports comparable to professional analyst work. Every claim is backed by inline citations linking to exact sources. The reports are structured with clear sections, data-rich insights, and specific figures—not generic summaries but analytical documents that rival what a skilled research assistant might produce (source).
In real-world testing, the results have been striking. Professionals rated outputs as "better than intern work" in blind tests. Architects reviewing a 15,000-word building code checklist assembled from 21 sources estimated it would have taken a human 6-8 hours to produce. An antitrust lawyer compared an 8,000-word legal memo favorably to what a junior attorney might deliver, estimating 15-20 hours of human labor saved.
The Five-Phase Research Process
Deep Research follows a sophisticated multi-phase process that mirrors how a skilled human researcher would approach a complex question:
Phase 1: Clarifying the Task Through Interactive Questions
Before diving into research, Deep Research often begins with a clarification phase. The model may ask follow-up questions to ensure it truly understands the requirements. For instance, if asked to plan a vacation, it might inquire about priorities: "How important is the room view versus location?" This proactive clarification reduces the need for revisions later and helps the AI form a concrete research plan aligned with true intent.
Phase 2: Breaking Down Queries Into Sub-Questions and Planning Research Strategy
Once the task is clear, Deep Research internally maps out a plan. It decomposes the high-level query into subtopics or sub-questions that need answering. For example, if asked about the economic impact of a new drug, it might identify sections needed on clinical outcomes, cost effectiveness, and regional pricing. This decomposition happens implicitly—the model decides what pieces of information to investigate and in what order, prioritizing broad context first before drilling into specifics.
Phase 3: Iterative Web Searching With Progressive Query Refinement
With a plan in mind, the agent begins searching the web. But this isn't a single Google search—it's an iterative process. Deep Research will do a search, read some results, then decide on the next search query based on what it learned. It discovers information in the same iterative manner as a human researcher, progressively focusing and refining queries as it uncovers more specific information.
If initial results are too general or hit paywalls, the agent pivots. In one documented case, when confronted with paywalled standards, the model noted internally "Considering a non-ICC site might be a good move" and then searched for public summaries on state government sites. A single Deep Research query can involve dozens of search queries and page fetches—one user's query led the agent to consult 21 different sources across nearly 28 minutes of processing.
Phase 4: Reading and Analyzing Diverse Content Formats
Deep Research doesn't just skim search results—it thoroughly reads and analyzes content. The agent can handle various formats: plain HTML, PDF files, and even images. If a scholarly article is only available as PDF, it opens and parses it. If key data appears in a chart, it can analyze the image or accompanying captions.
The model also has access to a Python code execution environment. If the research requires crunching numbers, making calculations, or plotting charts, Deep Research can write and run code on the fly. For example, it might retrieve a CSV from a source and compute statistics, or generate a graph to visualize trends found in the data.
Phase 5: Synthesizing Findings Into Structured Reports With Inline Citations
As Deep Research gathers material, it gradually forms a comprehensive answer. In the final phase, it synthesizes all information into a coherent, written report. The output is typically well-structured with descriptive headings, sections for each subtopic, and a logical flow from introduction through analysis to conclusions.
Every factual claim is accompanied by an inline citation—a clickable reference pointing to the exact source lines backing up that claim. This citation practice makes the final output fully traceable, alleviating trust issues common with typical AI responses. The system also provides a summary of its reasoning steps, showing what searches it made and why, giving users insight into how the answer was constructed.
The Core Technical Architecture
Under the hood, Deep Research relies on an agent architecture that integrates several key components:
Foundation: o3 Model Trained With Reinforcement Learning
The system is powered by an early version of OpenAI's o3 model, successor to GPT-4, specialized for extended reasoning and web browsing tasks. This model has an expanded "attention span" and can maintain focus through long chains of thought—crucial for handling multi-step research without losing context.
During training, OpenAI used end-to-end reinforcement learning on complex browsing and reasoning tasks. The model was placed in simulated research environments with access to tools and given real-world tasks requiring multi-step problem solving. Through this process, it learned to plan and execute multi-step search trajectories, backtrack when paths are unfruitful, and pivot strategies based on new information.
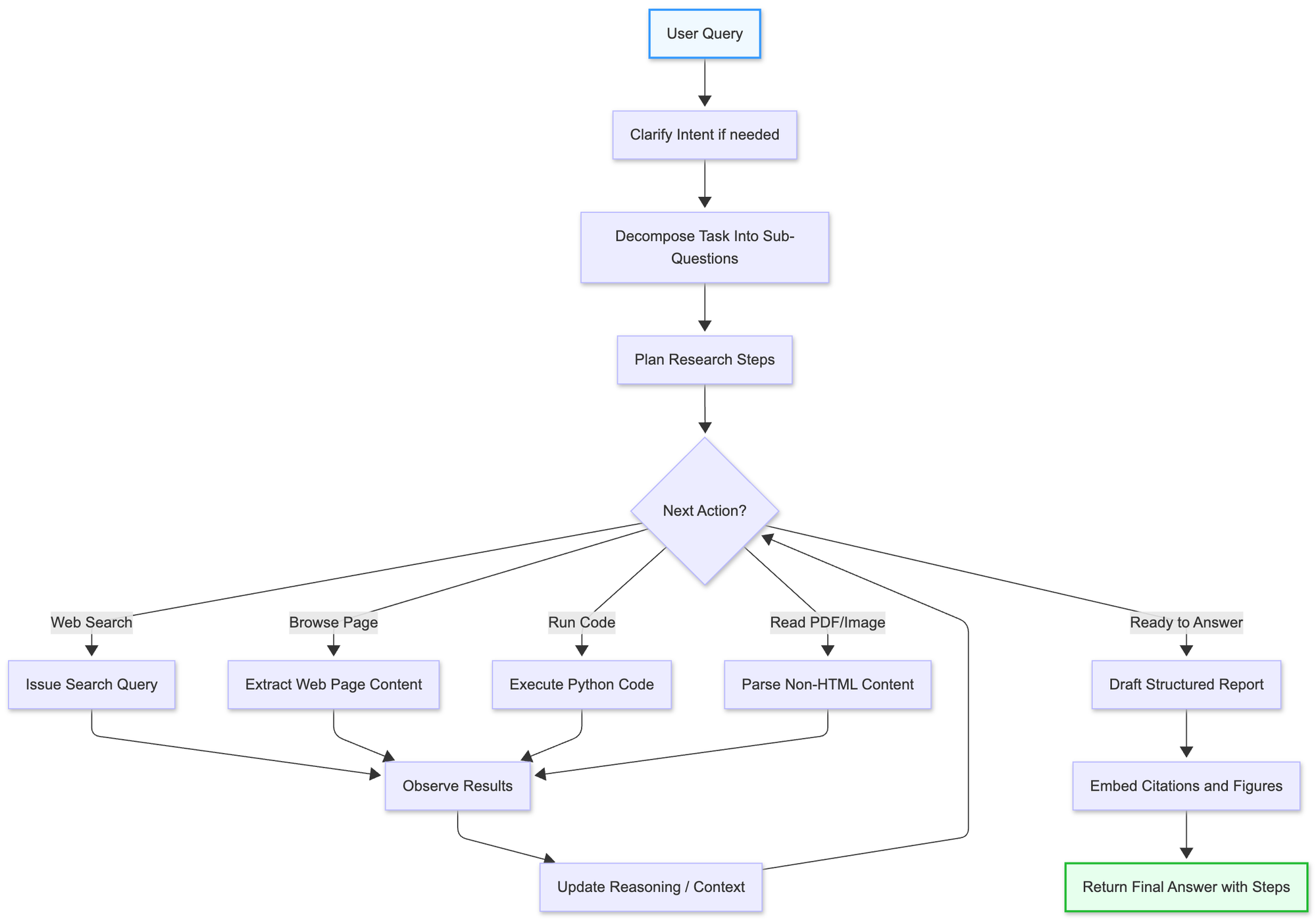
ReAct-Style Loop: Plan → Act → Observe
Deep Research follows the classic "Plan-Act-Observe" loop from the ReAct paradigm. The model plans what it needs to do (often implicit in its chain-of-thought), acts by invoking a tool (like issuing a search query), observes the result (reading the returned webpage), then repeats this cycle until ready to produce the final answer.
This iterative process is key to its effectiveness. Rather than trying to answer in one go, Deep Research can pursue multiple research threads, backtrack from dead ends, and gradually build understanding through many intermediate steps.
Integrated Tools: Web Search, Browser, Code Interpreter, File Parser
The model has access to several critical tools:
- Web search tool for real-time internet queries (mandatory for operation)
- Web browser that can fetch page content, search within pages, and handle scrolling
- Code interpreter for data analysis, calculations, and visualization
- File parser for PDFs, images, and other non-HTML content
These tools are invoked autonomously by the model as needed. The training process taught it when and how to use each tool effectively, much like a skilled researcher knows when to search, when to dive deep into a source, and when to run calculations.
Critical Innovation: Extended Chain-of-Thought Reasoning
A key improvement in the o3 series is the ability to maintain extended chains of thought without diverging or hallucinating. The model can carry out lengthy reasoning chains—sometimes involving hundreds of steps—while staying focused on the original research goal. This is achieved through special training that optimized the model to stay on task through many intermediate steps.
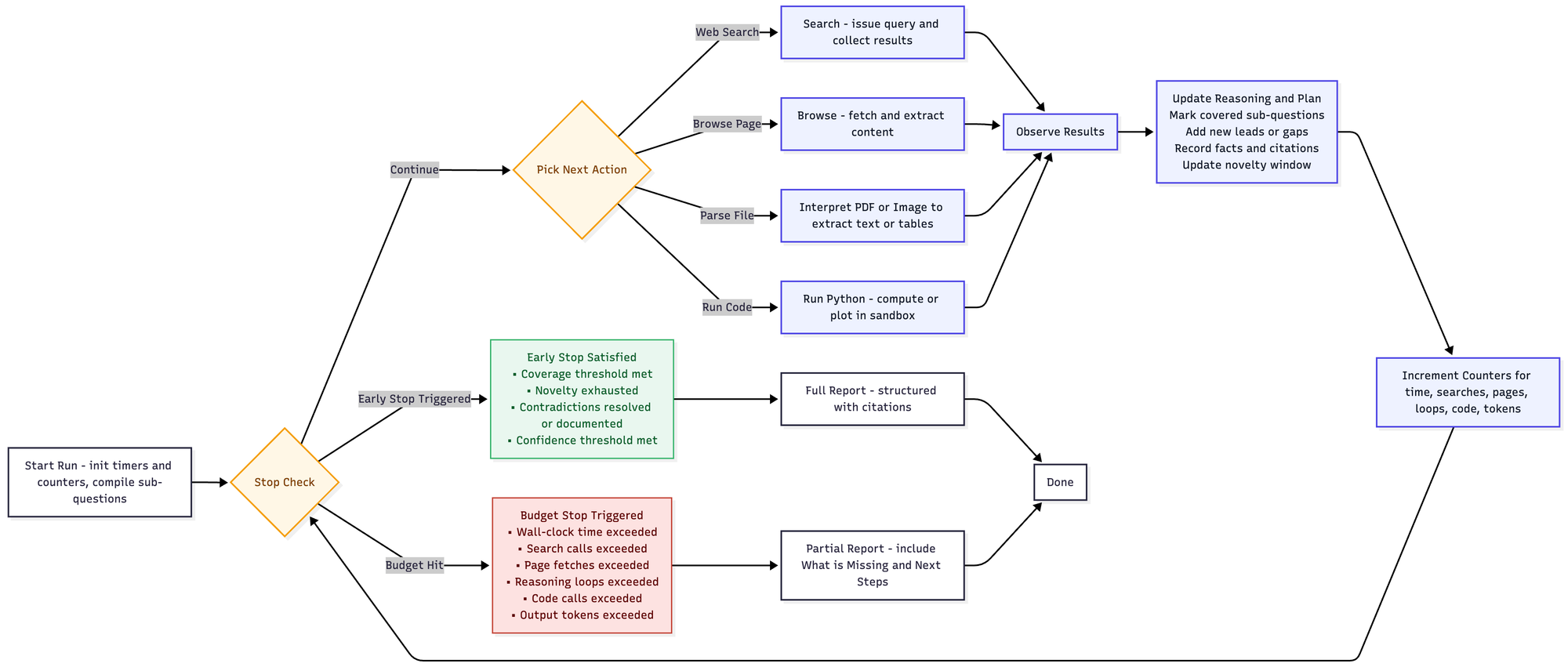
How the Agent Decides When to Stop
Deep Research uses a sophisticated two-tier stopping mechanism that balances thoroughness with practical constraints:
Coverage-Based Early Stops
The agent stops when it determines it has sufficient coverage of the research question:
- Threshold of sources per sub-question met (typically 2+ independent sources, or 1 if authoritative)
- Novelty exhausted—recent searches aren't uncovering new information
- Contradictions resolved or explicitly documented in the report
- Confidence threshold reached for each section and overall
Budget-Driven Hard Stops
To prevent runaway processes, the system enforces hard limits:
- Wall-clock time: typically 20-30 minutes maximum
- Search call limits: often 30-60 web searches per task
- Page fetch caps: usually 120-150 pages maximum
- Reasoning loop maximums: around 150-200 iterations
- Code execution limits: 5-10 calls with 30-60 second timeouts
When a budget limit is reached, Deep Research produces a partial report clearly marking what was completed and what additional research would be beneficial.
Building Your Own Deep Research System
Creating a similar autonomous research agent requires assembling several core components:
Core Components Needed
1. Strong LLM with chain-of-thought capabilities: You need a model that can maintain extended reasoning chains. While GPT-4 can work, models specifically trained for reasoning (like o1 or open-source alternatives) perform better.
2. Tool interface for search and browsing: Implement connectors to search APIs (like Bing or Google) and a web scraper that can extract clean text from pages. Handle different content types including PDFs and images.
3. Controller loop: Build a ReAct-style orchestrator that manages the plan-act-observe cycle, feeding tool outputs back to the model for next steps.
Key Architectural Lessons
Allow iterative calls: Don't limit the model to a single pass. Let it make multiple searches and refine its understanding progressively.
Enable backtracking from dead-ends: When a research path proves unfruitful (paywalls, irrelevant results), the system should be able to pivot to alternative approaches.
Maintain citation metadata: Track the source URL and specific text excerpt for every piece of information extracted. This enables the transparent, verifiable reports that make Deep Research trustworthy.
Best Use Cases
Deep Research shines for:
- Competitive intelligence requiring synthesis across many sources
- Technical research needing comprehensive coverage
- Policy analysis demanding authoritative citations
- Academic literature reviews where thoroughness is paramount
- Due diligence tasks requiring verifiable information trails
What This Means For Building AI Agents
The combination of extended reasoning, tool use, and iterative refinement creates genuinely useful research capability. The agent's ability to maintain focus through long research trajectories, pivot when needed, and synthesize findings with full citations produces outputs that professionals find comparable to human analyst work.
Deep Research represents a template for future AI agents that don't just access knowledge but actively research and synthesize it. As models continue to improve and costs decrease, we can expect these autonomous research capabilities to become standard tools in the knowledge worker's arsenal, fundamentally changing how we approach complex research tasks.


