GPT-5 Context Window: The AI Memory Revolution That Changes Everything

Like Moore's Law transformed computing power, context windows in AI have been doubling every year, and GPT-5's massive 400K-token leap represents the most dramatic expansion yet. This isn't just another incremental upgrade; it's a fundamental shift in what artificial intelligence can process, remember, and understand in a single interaction.
With GPT-5's ability to handle roughly 300,000 words at once, equivalent to an entire novel, massive codebase, or months of conversation history, we're entering an era where AI can truly grasp complex, interconnected information without losing the thread. Here's what this breakthrough means for the future of AI applications.
The Evolution of Context Windows
The journey from GPT-1's modest 512-token window to GPT-5's expansive 400K capacity tells a story of exponential technological progress. Each generation has doubled or tripled what came before.
GPT-1 (2018) started with just 512 tokens, barely enough for a few paragraphs. GPT-2 (2019) doubled this to 1,024 tokens, while GPT-3 (2020) reached 2,048 tokens, finally enabling processing of medium-length documents. The real acceleration began with GPT-3.5 (2022) at 4,096 tokens, then GPT-4 (2023) which launched at 8,192 tokens before expanding to 128,000 tokens in its Turbo variant.
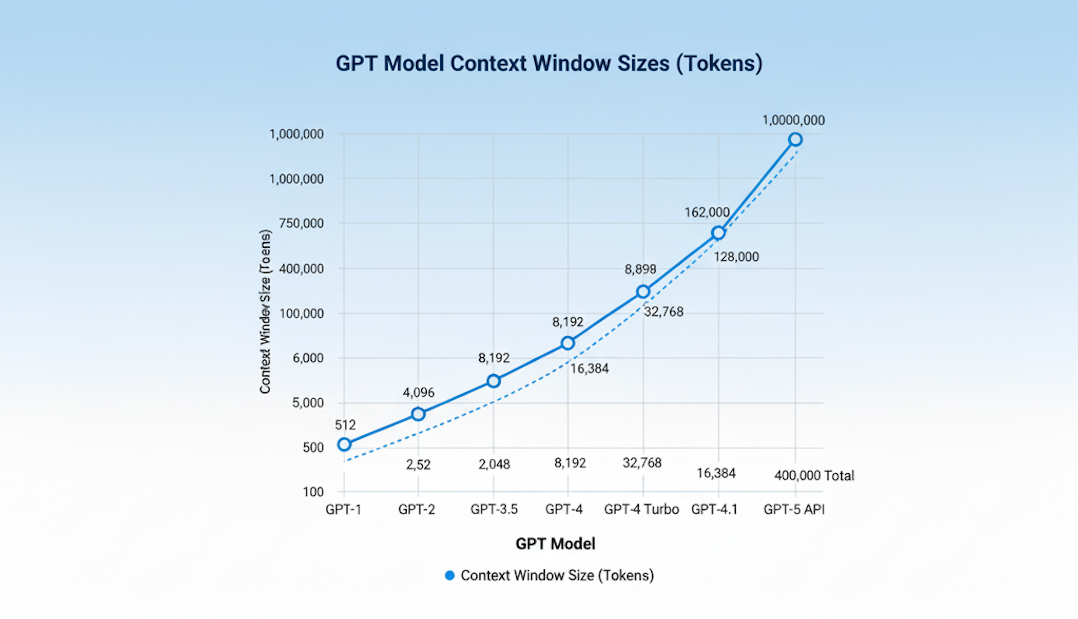
This growth wasn't just about throwing more computing power at the problem. Critical innovations made it possible: FlashAttention algorithms that run in near-linear time instead of quadratic, and rotary positional encoding that helps models understand token relationships across vast distances. Without these breakthroughs, the computational cost of processing hundreds of thousands of tokens would be prohibitive.
GPT-5's Actual Context Specifications
Understanding GPT-5's context window requires distinguishing between API capabilities and ChatGPT interface limits, because they're dramatically different.
API Access: The Full Power
Through the API, developers get access to GPT-5's full 400,000 total tokens capacity. This breaks down to approximately:
- 272,000 input tokens for your prompt
- 128,000 output tokens for the model's response
This massive capacity means you can feed GPT-5 an entire technical manual, complete codebase, or multiple research papers in a single API call.
ChatGPT Interface: Tiered Access
The consumer-facing ChatGPT app implements more conservative limits based on subscription tiers:
- Free users: 16,000 tokens per conversation
- Plus/Business subscribers: 32,000 tokens
- Pro/Enterprise customers: 128,000 tokens (or up to 196,000 in "Thinking" mode)
The special "GPT-5 Thinking" mode, which activates automatically for complex tasks or can be manually selected, extends these limits further. When engaged, even Plus subscribers can access up to 196,000 tokens for deep analysis tasks.
Why the Disparity?
This gap between API and interface limits exists for practical reasons: resource management, cost control, and ensuring consistent performance for millions of users. The full 400K window requires substantial computational resources that would be unsustainable if every ChatGPT query maxed out the capacity.
Long-Document Analysis
Instead of chunking a 500-page legal contract into dozens of segments, lawyers can now upload the entire document and ask nuanced questions about cross-references, contradictions, or specific clauses. Academic researchers can analyze entire dissertations, while publishers can review full manuscripts, all while maintaining perfect awareness of how different sections relate to each other.
Codebase Understanding
Software developers can paste entire repositories into a single prompt. Imagine uploading your complete React application, every component, every configuration file, every test, and asking GPT-5 to identify performance bottlenecks, suggest refactoring strategies, or explain how different modules interact.
// Example: GPT-5 can now analyze this entire codebase structure at once:
// - 50+ component files
// - State management logic
// - API integrations
// - Test suites
// - Configuration files
// And provide coherent, context-aware suggestions across all files
Extended Conversations
Customer service applications can maintain months of interaction history, ensuring every response considers the full context of a customer's journey. Educational platforms can track a student's entire learning progression, adapting instruction based on comprehensive understanding rather than fragmented sessions.
Data Analysis at Scale
Financial analysts can upload entire datasets, quarterly reports spanning years, market data across multiple sectors, comprehensive audit trails, and receive insights that consider all the interconnections and patterns that would be invisible when analyzing chunks in isolation.
The Real-World Trade-offs
With great context comes great responsibility, and several significant challenges:
Compute Cost and Latency
Processing 400,000 tokens isn't free, computationally or financially. Response times increase substantially as you approach the context limit. What might take 2-3 seconds with a small prompt could stretch to 30+ seconds with maximum context, even with optimizations like FlashAttention.
Token Usage Expenses
At current API pricing, a single maximum-context query can cost several dollars. For businesses processing thousands of documents daily, this adds up quickly. Smart prompt engineering, deciding when you actually need the full context versus when chunking would suffice, becomes a critical skill.Tools like Promptlayer can help teams monitor and optimize their token usage, providing analytics and prompt versioning that make it easier to control costs as context windows grow.
Quality Degradation
Paradoxically, using too much context can sometimes hurt performance. As you approach the 400K limit, the model may struggle to maintain focus, producing generic responses or missing crucial details buried in the middle of massive inputs. The "lost in the middle" phenomenon, where models pay less attention to information in the center of very long contexts, remains a challenge.
The Competition Factor
While GPT-5's 400K window seemed revolutionary at launch, the competition hasn't stood still. Claude Sonnet 4 and Gemini 2.5 Pro already offer 1-million-token windows, with Gemini planning expansion to 2 million. This context arms race shows no signs of slowing, suggesting GPT-5's advantage may be temporary.
When to Use Maximum Context
Use the full 400K window when:
- Analyzing documents with complex internal references
- Working with codebases where component interactions matter
- Processing datasets where patterns emerge only at scale
- Maintaining conversation continuity over extended interactions
When to Chunk Instead
Stick with smaller contexts when:
- Tasks are clearly segmented and independent
- Response speed is critical
- Budget constraints make full-context queries impractical
- You're doing iterative refinement where earlier context becomes irrelevant
Future Outlook
The trajectory is clear: million-token windows will become standard within the next year. The real innovation will shift from raw capacity to intelligent context management, models that know what to remember, what to forget, and how to synthesize vast amounts of information into actionable insights.
Balancing Power and Practicality
GPT-5's 400K-token context window represents a major milestone in AI development, but it's best understood as part of an ongoing revolution rather than a final destination. While the raw capacity enables unprecedented applications, from whole-book analysis to comprehensive codebase understanding, the real-world value comes from balancing this capability with practical considerations of cost, speed, and quality.
As we race toward million-token models and beyond, the winners will be those able to understand when and how to use massive context windows. GPT-5 has given us a powerful new tool; learning to wield it wisely will determine whether this memory revolution truly transforms how we work with AI or simply gives us a more expensive way to process information we could have handled more efficiently in smaller chunks.
The context window revolution is about fundamentally rethinking how we structure our interactions with AI. And in that sense, GPT-5's 400K tokens are just the beginning.


