GPT-5 API Features (Our Breakdown)

GPT-5 isn’t just another model upgrade – it’s a tectonic shift in the landscape of developer tools for AI. If you’ve spent time wrangling with the limits of GPT-3.5 or GPT-4, prepare for a different experience: enormous 400,000-token context windows, agent-level tool usage, nuanced parameter controls, and API infrastructure that feels tailor-made for orchestration, prompt management, and large-scale experimentation. For developers seeking to build smarter, faster, and more controllable AI-driven apps, understanding the feature set of GPT-5 is now mission-critical.
Below, you’ll find a deep dive into the primary features, practical tradeoffs, and the changes that will reshape your approach to prompt engineering, tool integration, and cost management.
Model Versions and Context Limits
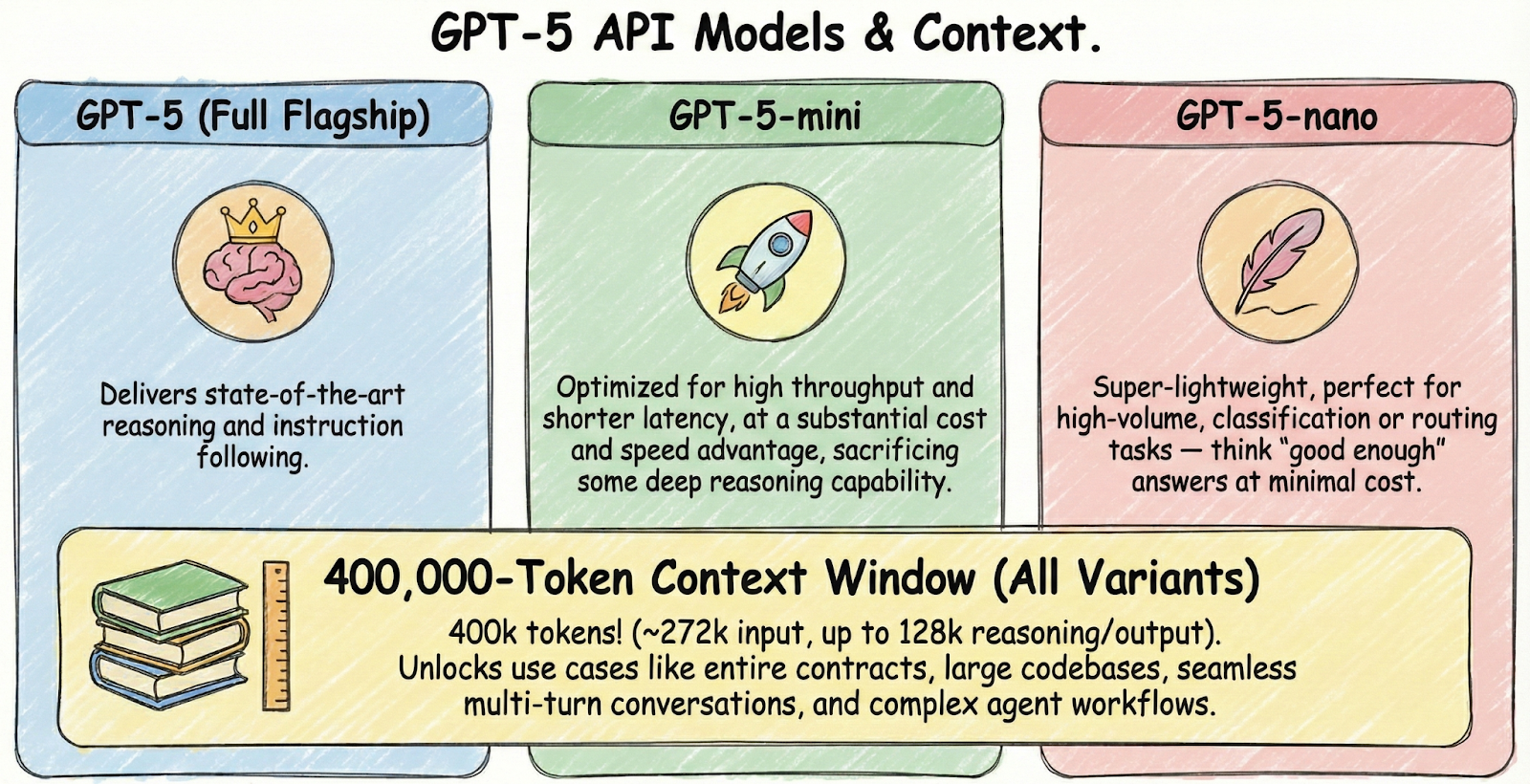
A defining feature of the GPT-5 API is its versatile, tiered model family. You now have the flexibility to choose from:
- GPT-5 (the full, flagship model): Delivers state-of-the-art reasoning and instruction following.
- GPT-5-mini: Optimized for high throughput and shorter latency, at a substantial cost and speed advantage, sacrificing some deep reasoning capability.
- GPT-5-nano: Super-lightweight, perfect for high-volume, classification or routing tasks - think “good enough” answers at minimal cost.
All GPT-5 variants share a jaw-dropping 400,000-token context window (commonly split as ~272,000 input tokens and up to 128,000 reasoning/output tokens in the API). For context, GPT-4 maxed out at 32k tokens, and GPT-3.5 at just 4k–16k. This massive window unlocks use cases like:
- Passing entire legal contracts, books, or large codebases in a single interaction.
- Maintaining seamless, highly contextual multi-turn conversations without truncating history.
- Prompting agentic workflows where dozens of tool calls and intermediate computations stack up in a single session.
With these context gains come new challenges - token costs, latency, and cache management become essential to monitor. Modeling large-scale, long-context workflows (like those common in PromptLayer’s orchestration pipelines) is now feasible - but careful planning is a must.
Endpoints and Interfaces
GPT-5 extends beyond the familiar Chat Completions endpoint, introducing a suite of specialized APIs:
- Chat Completions (/v1/chat/completions): The standard for classic conversational turns.
- Responses API (/v1/responses): Designed for advanced, multi-step agentic workflows and tool use, featuring server-managed conversation state and built-in support for chain-of-thought transparency.
- Realtime Endpoint (/v1/realtime): Enables true streaming and voice-mode sessions (often used with GPT-4o for the fastest possible latency).
- Assistants API (/v1/assistants): Lets you define persistent AI assistants with structured logic, toolkits, and workflow rules.
Batch APIs are also available for asynchronous, high-volume jobs - especially handy when you’re running large distributed experiments or want to optimize for cost using Batch API’s deep discounts.
An important caveat: fine-tuning is not supported for GPT-5. Instead, developers are encouraged to use system instructions, custom tools, or model distillation training smaller models on GPT-5 outputs for task-specific performance:

- Teacher: An expensive, powerful model (GPT-5) generates "perfect" answers.
- Student: A cheap, fast model (Mini/Nano) studies those answers to learn the logic.
- Result: You get high-end intelligence at a fraction of the cost and time.
Essentially, you pay for the "education" once so you can run the "student" cheaply forever.
Input/Output Modalities
GPT-5 is natively multimodal. Text and image inputs are fully supported, so you can, for example, ask the model to analyze a chart or solve a problem based on a diagram. This unlocks a broader range of intelligent applications - think document review, code + screenshot debugging, or education apps that take image-based questions.
However, GPT-5’s outputs remain text-only. Audio and video are not direct input types; for those, OpenAI recommends pairing specialized models (like Whisper for speech-to-text) upstream in your pipeline. Image generation is supported via tool calls (with DALL-E style APIs), not as direct output.
Throughput and Latency
Despite its expanded context and reasoning power, GPT-5 delivers improved or comparable latency to earlier models - thanks to backend optimizations and new developer controls. Here’s what stands out:
- reasoning_effort parameter: Lets you tune the model’s internal “thinking” depth on a scale from none/minimal all the way to high/xhigh (varies by version). Minimal or none yields snappy, near-instant responses; high means more tokens and time spent reasoning (ideal for tough or high-stakes queries).
- Streaming and batching: Both are fully supported. Streaming means your app (or end user) can start consuming output as soon as the first token is ready, which is crucial for large, slow-to-generate responses.
For ultra-low-latency applications, GPT-5-mini and GPT-5-nano offer the highest throughput at the lowest cost.
Pricing and Rate Limits
GPT-5 is a premium model, and pricing reflects its advanced feature set:
| Model | Best for | Cost tier | Latency tier | Context window | Input ($ / 1M tokens) | Output ($ / 1M tokens) |
|---|---|---|---|---|---|---|
| GPT-5 | Hardest reasoning, agentic workflows, complex orchestration | High | Higher | 400k | 1.25 | 10.00 |
| GPT-5 mini | Balanced quality + speed for most production workloads | Mid | Medium | 400k | 0.25 | 2.00 |
| GPT-5 nano | High-throughput, low-cost classification/extraction/routing | Low | Lowest | 400k | 0.05 | 0.40 |
Pricing can change, so check OpenAI’s pricing page for current details. Output tokens are more costly relative to input, so verbosity and output-length controls are your friends.
Rate limits are tiered by account, not available on free plans. Entry tiers allow around 500 requests and 500k tokens per minute, with enterprise options scaling much higher. For large-scale production or analytics workloads, prefer using the Batch API and prompt caching discounts to slash costs and optimize for high throughput.
Strategies for cost-effective use:
- Deploy a model router pattern: use nano or mini for “easy” requests, escalate up to full GPT-5 for complex queries.
- Exploit prompt caching: identical prefixes can drastically lower your bill on repeated context.
- Meter and alert on token counts and cache hit rates per workflow - integrations with platforms like PromptLayer make this observable and controllable.
Developer-Focused Tools and Capabilities
Here's where GPT-5’s API feels like it was designed by developers, for developers:
Streaming Responses
- Receive output token-by-token in real time for faster end-user experiences. Especially vital with long outputs or when building conversation UIs.
Function Calling & Custom Tools
- Enhanced function calling allows you to register both classic JSON-based functions and a “custom” tool type, where inputs can be free-form text (code, SQL, multi-line configs, etc.). Use regex or context-free grammar constraints for deterministic outputs when needed.
- Robust error handling, visible preamble messages before and after tool calls (e.g., “Searching knowledge base…”), and support for parallel/multi-step operations - this makes complex agentic workflows much smoother and easier to debug.
System Instructions and Role Messages
- Still based on role-paradigm (system/assistant/user), but now extended with explicit API-level parameters:
- verbosity (low/medium/high): steer general answer length/coarseness.
- reasoning_effort: dial in how much computation the model does before answering, balancing cost and accuracy.
- These parameters don’t override user requests, but offer strong coarse control for default behaviors.
Built-in Tool Suite
- File search, web search, image generation, and code execution (within a sandboxed environment) can be enabled just by configuring tool access - enabling true end-to-end automation for everything from coding agents to legal research assistants.
Structured Outputs and Observability
- GPT-5 reliably outputs JSON or other schema-constrained formats, enforced through grammar constraints. This eliminates the “hallucinated JSON” issues of earlier models.
- Pairing the API with an orchestration and observability platform, like PromptLayer, allows for comprehensive monitoring and analysis. This includes tracking every tool call, reasoning depth, token usage, and the per-step chain-of-thought data revealed by the Responses API.
The Real Upgrade Is Control
GPT-5’s headline features - 400k context, multimodal input, tool calling - are impressive. But the real unlock is that you can finally engineer behavior, not just hope for it: dial reasoning up or down, cap verbosity, and make tools and structured outputs feel like reliable building blocks instead of brittle hacks.
If you want GPT-5 to pay off in production, treat it like infrastructure. Pick the smallest model that can win, route intelligently, cache aggressively, and instrument everything: token spend, cache hit rate, tool-call success, and latency. That’s how “wow demos” turn into stable systems.
So here’s the move: take one workflow you already run on GPT-4 (a long-doc analysis, a tool chain, a support flow), port it to GPT-5, and run it as an experiment - with reasoning_effort and verbosity as your knobs, and observability as your safety net. The teams that learn to control GPT-5 - not just call it - are the ones that will ship the next generation of AI products.


