GPT-5.2: What’s New

The AI landscape is marked by fierce competition - and OpenAI has just doubled down with the release of GPT-5.2.
Rolled out amidst reports of an internal "code red" following Google’s Gemini 3 release, this update isn't just about flashy demos. It represents a substantial shift in professional utility: deeper reasoning, higher reliability, and a massive jump in context retention.
The GPT-5.2 update introduces several challenges for developers and prompt engineers, including new model variants, inconsistent naming between the Chat and API, and revised pricing. This guide outlines the key changes in GPT-5.2 and provides instructions for integrating it into your workflows.
The Core Upgrades: Smarter, Deeper, Reliable
OpenAI’s headline for GPT-5.2 is reliability. While previous models focused on creative leaps, GPT-5.2 targets the gap between "AI output" and "expert human work."
Enhanced General Intelligence
On the new GDPval benchmark, which spans 44 knowledge-heavy occupations, the GPT-5.2 "Thinking" variant reportedly beats or ties expert human judgments in 70.9% of direct comparisons. In practice, this means fewer hallucinations in multi-step workflows.
Coding Proficiency: From Copilot to Engineer
For software tasks, GPT-5.2 has eclipsed both its predecessors and Gemini 3. These aren't just vanity metrics; they are the industry's toughest stress tests for reliability.
SWE-Bench measures the ability to autonomously solve real-world coding issues - moving the model from a helpful "copilot" to a capable engineer. Meanwhile, the Tau2-bench confirms it can execute complex, multi-step API actions without getting confused. Together, they signal that GPT-5.2 has finally crossed the threshold from an experimental tool to a production-ready engine:
- SWE-Bench Pro: 55.6% accuracy.
- SWE-Bench Verified: 80.0% accuracy.
- Tau2-bench Telecom: 98.7% reliability on tool-use chains.
Long-Context & The compact Feature
Perhaps the biggest leap for RAG applications is the expanded context window. The model demonstrates near-perfect recall on OpenAI’s MRCRv2 benchmarks up to 256k tokens.
Additionally, OpenAI introduced a new Responses API /compact feature. This allows developers to compress history in agentic workflows. This "Context Compaction" pattern - advocated by engineering teams at Anthropic and Google ADK - is now native to GPT-5.2, significantly reducing handoff errors in long-running tasks.
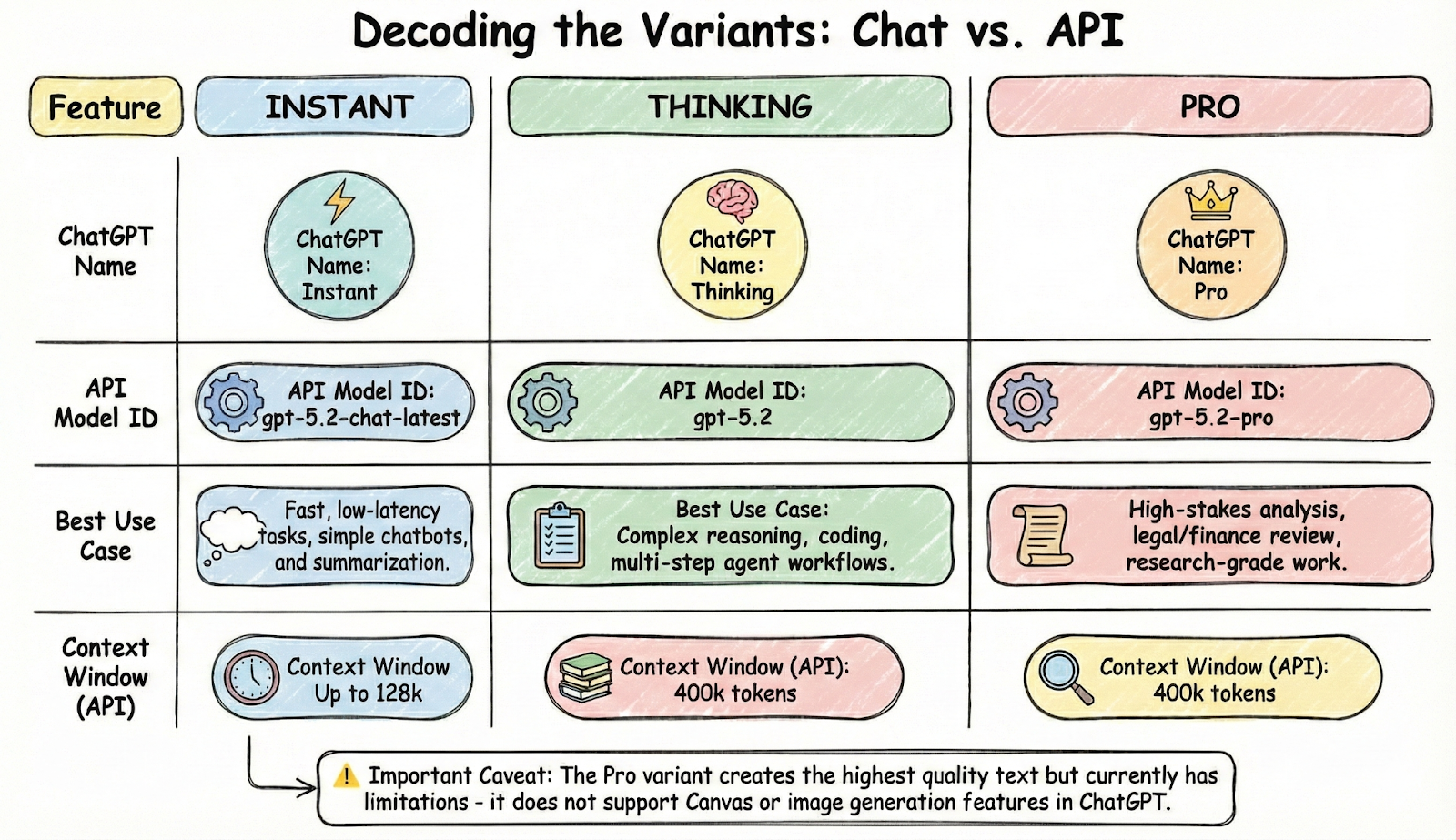
Decoding the Variants: Chat vs. API
OpenAI has introduced three distinct "flavors" of GPT-5.2. Crucially, the names used in ChatGPT do not match the Model IDs you will use in your code.
API Pricing and Specs
If you are building backend systems, here is how the costs break down. OpenAI has maintained the trend of aggressive pricing for the standard model while placing a premium on the "Pro" tier. (See full OpenAI Pricing for legacy models).
| Model Variant | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Cached Input Discount |
|---|---|---|---|
| GPT-5.2 (Thinking) | $1.75 | $14.00 | 90% |
| GPT-5.2 Pro | $21.00 | $168.00 | 90% |
Knowledge Cutoff: August 31, 2025.
Mapping GPT-5.2 to Your Workflow
With the split between Instant, Thinking, and Pro, GPT-5.2 is not a "one-size-fits-all" model. Here is how we recommend mapping these to your prompt engineering strategy:
- Use gpt-5.2-chat-latest (Instant) for: High-throughput everyday tasks, fast classification, and basic sentiment analysis where cost and speed are priorities.
- Use gpt-5.2 (Thinking) for: Most production applications. It hits the sweet spot for complex drafting, coding assistance, and handling massive documents via RAG.
- Use gpt-5.2-pro (Pro) for: "Golden record" generation or zero-shot tasks where accuracy is non-negotiable and volume is low.
How to Migrate Without Breaking Production
New models mean new behaviors. While GPT-5.2 boasts a 30% reduction in hallucinations, it will inevitably respond differently to your existing prompts than GPT-4 or GPT-5.1.
The Deprecation Timeline: OpenAI notes that in ChatGPT, GPT-5.1 will sunset for paid users roughly three months post-launch (March 2026). However, the API models for 5.1 and 4o remain active for now.
How to Migrate Safely: Don't switch your production keys overnight.
- Snapshot Your Prompts: Use a prompt management tool like PromptLayer, to version and tag your current working prompts and their outputs with GPT-5.1.
- A/B Test: Run gpt-5.2 alongside your current model on a subset of traffic using PromptLayer evaluations. Monitor for "drift" - cases where the new model might be too concise or refuse to answer due to updated safety guardrails.
- Lock Your Version: For stability, we recommend targeting the specific snapshot (e.g., gpt-5.2-2025-12-11) rather than the alias, so your app doesn't break when OpenAI pushes a stealth update.
Precision Over Hype
GPT-5.2 feels less like a headline grab and more like a quiet step forward for teams building real systems. The gains aren’t about novelty - they show up in fewer edge-case failures, more consistent reasoning across long tasks, and better behavior when models are asked to act, not just respond.
For developers, this shift changes where the work lives. Model choice, prompt design, evaluation, and cost control now matter as much as raw intelligence. Getting value from GPT-5.2 means treating it like production infrastructure: version it, test it, observe it, and route tasks to the right variant based on risk and scale.
Teams that approach GPT-5.2 this way will move faster with fewer surprises. The advantage won’t come from chasing every new capability, but from knowing exactly where this model fits - and using it deliberately.


