GPT-4o-Mini-TTS: Steerable, Low-Cost Speech via Simple APIs

What if your app could sound like a sympathetic agent or an enthusiastic tour guide, just by prompting? GPT-4o-Mini-TTS brings steerable, natural, low-cost speech to apps via simple APIs, transforming how developers integrate voice into their applications.
Announced by OpenAI in March 2025, this advanced text-to-speech model builds on the success of GPT-4o-mini. With OpenAI's Realtime Audio API reaching general availability in August 2025, the ecosystem for voice-enabled applications has never been more robust.
This article explores what GPT-4o-Mini-TTS is and how it works, its capabilities and specifications, access methods and pricing, high-impact use cases, current limitations with best practices, and what's on the horizon for this transformative technology.
What It Is and How It Works
GPT-4o-Mini-TTS represents a breakthrough in text-to-speech technology. Built on the compact and efficient GPT-4o-mini architecture, this model generates highly natural, human-like speech while maintaining cost-effectiveness that makes it accessible for widespread deployment.
The model's most revolutionary feature is its steerable delivery system. Unlike traditional TTS systems with fixed voice characteristics, GPT-4o-Mini-TTS allows developers to control tone, emotion, pacing, and accent through simple prompts. Want your virtual assistant to sound like a "sympathetic customer service agent" or an "enthusiastic tour guide"? Just include that instruction in your prompt. Need a "mad scientist" for your educational game? The model adapts accordingly.
Under the Hood
At its core, GPT-4o-Mini-TTS is a transformer-based text and audio model that processes text input along with optional style prompts to produce audio streams. The model underwent extensive training through multiple phases:
- Large-scale audio and text pretraining on massive datasets to learn speech patterns
- Supervised fine-tuning and reinforcement learning specifically on audio outputs
- Advanced distillation from larger audio models to capture nuanced intonation while maintaining efficiency
A key innovation lies in the model's use of style and "vibe" embeddings that decouple voice characteristics from content. This architectural choice enables fine-grained control over delivery without compromising the underlying speech quality.
The system employs a neural vocoder to synthesize waveforms at 48 kHz sampling rate, producing studio-grade audio output. With a context window of 2,000 input tokens, the model can handle substantial text chunks, though very long content requires segmentation.
Capabilities and Specs at a Glance
GPT-4o-Mini-TTS sets new standards for synthetic speech across multiple dimensions:
Naturalness and Quality
The model produces remarkably realistic intonation and rhythm, achieving mean opinion scores (MOS) exceeding 4 out of 5 in subjective tests, a significant improvement over previous generation TTS systems. The audio output sounds genuinely human-like, with proper emphasis, pauses, and emotional nuance.
Voice Library and Customization
OpenAI provides a dozen synthetic preset voices with distinct timbres, including options like Alloy, Ash, Nova, and Sage. These can be combined with various style "vibes" such as cheerful, poetic, or business-like to create unique vocal personalities. Each voice maintains its own character while adapting to the specified delivery style.
Multilingual Excellence
Supporting 50+ languages worldwide, GPT-4o-Mini-TTS handles major languages including English, Chinese, Japanese, Korean, French, German, and Spanish with impressive accuracy. The model can even switch between languages or accents within a single session, making it ideal for international applications.
Flexible Delivery Modes
The system supports both synchronous and streaming modes, enabling developers to build low-latency voice applications. This flexibility is crucial for real-time interactions where immediate audio feedback enhances user experience.
Dynamic Delivery Control
Perhaps most impressively, developers can modify tone, emotion, speed, and accent on the fly through prompt engineering. This level of control was previously impossible without recording multiple voice actors or extensive post-processing.
Access, Integration, and Cost
OpenAI has made GPT-4o-Mini-TTS remarkably accessible through multiple channels:
API Access
The primary access point is through OpenAI's Text-to-Speech API, with enterprise users also able to leverage the Azure OpenAI Service. These APIs provide straightforward integration paths for existing applications.
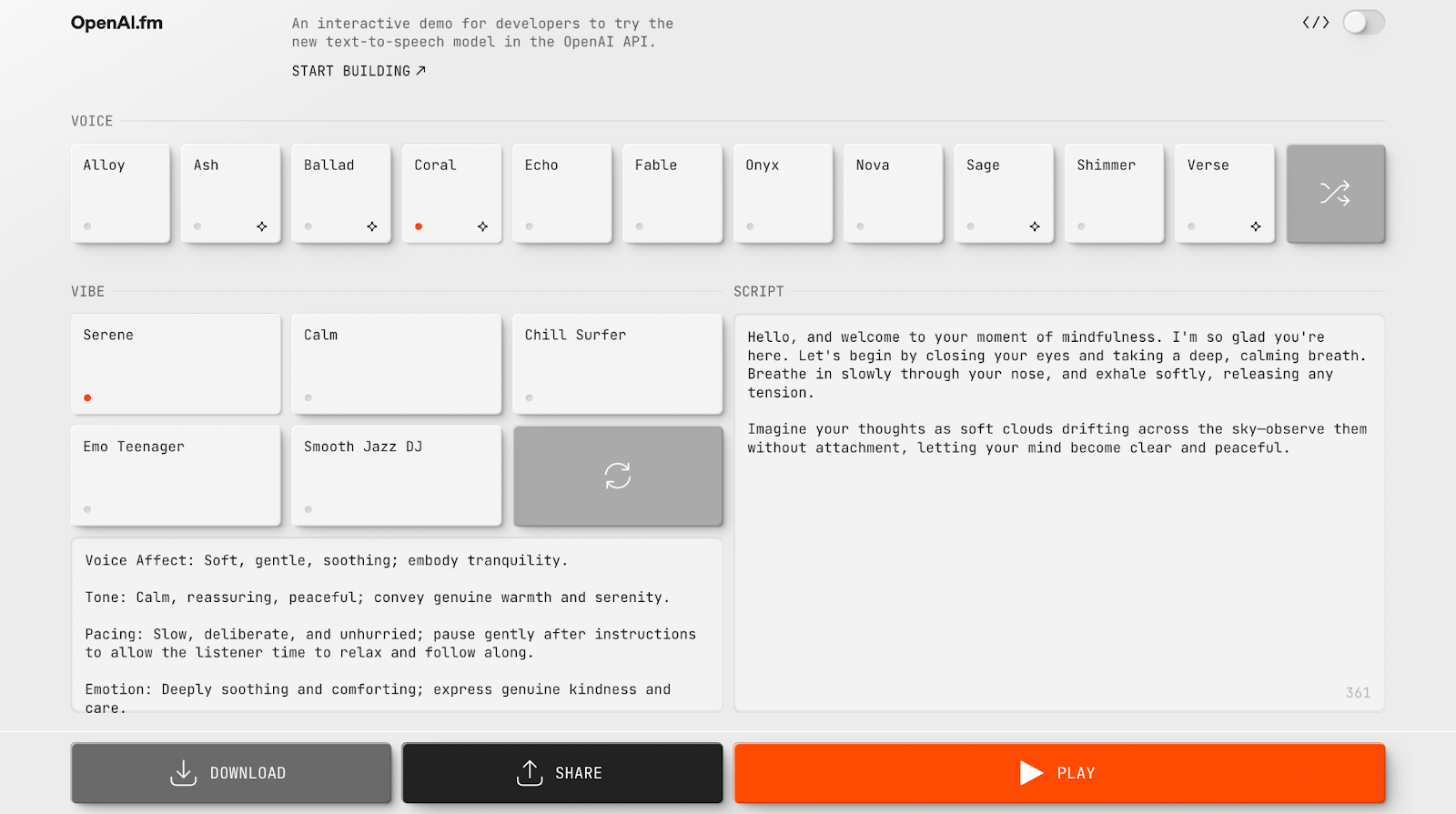
Interactive Demo
OpenAI offers OpenAI.fm, a free web demonstration requiring no signup. Users can select voices and vibes, input text, and instantly hear the generated speech, perfect for experimentation and prototyping.
SDK Integration
The OpenAI Agents SDK now includes audio support, allowing developers to transform text-based agents into full voice agents with minimal code changes. This integration is particularly powerful when combined with the Realtime Audio API (GA since August 2025) for speech-to-speech applications.
Competitive Pricing
OpenAI has positioned GPT-4o-Mini-TTS as a cost-effective solution:
- Input tokens: ~$0.60 per million
- Output tokens: ~$12.00 per million
- Practical cost: approximately $0.015 per minute of generated speech
This pricing structure makes high-quality TTS accessible for applications ranging from IVR systems and voice bots to educational platforms and IoT devices.
High-Impact Use Cases
The versatility of GPT-4o-Mini-TTS opens doors across numerous industries:
Customer Service & Voice Bots
Create empathetic, helpful voice responses for call centers and automated support systems. The ability to adjust tone dynamically means your bot can express appropriate concern for frustrated customers or enthusiasm when sharing good news.
Media and Content Production
Generate voiceovers, narration, audiobooks, and podcasts at scale. Content creators can produce professional-quality audio without hiring voice actors, dramatically reducing production time and costs.
Accessibility Solutions
Convert webpages, documents, and messages into natural speech for users with visual impairments or reading disabilities. The high-quality output significantly improves the listening experience compared to traditional screen readers.
Voice Assistants & IoT
Power smart assistants, robots, and IoT devices with branded personas. Whether you need a calm professional voice for home automation or a medieval knight character for a game, the steerable nature of GPT-4o-Mini-TTS delivers.
Education & Language Learning
Generate multilingual examples with authentic accents and varied speaking styles. Language learning apps can provide native-sounding pronunciation guides, while educational content can adapt its delivery style to match different age groups or learning contexts.
Limitations and Best Practices
While powerful, GPT-4o-Mini-TTS has important constraints to consider:
Current Limitations
Preset voices only: The model currently restricts users to OpenAI's provided voices. Custom voice uploads aren't supported yet, though this feature appears on the roadmap pending safety reviews.
Long-form stability issues: Extended outputs beyond 1-2 minutes may exhibit random pauses, stutters, or volume shifts. Users report occasional glitches in lengthy narrations that require attention.
Language and accent variability: While supporting many languages, quality isn't uniform across all options. Some non-English languages or uncommon accents may retain hints of the model's default characteristics.
Token limitations: The 2,000-token context window necessitates chunking for longer texts like novels or extended scripts.
Constrained expression range: OpenAI has curated outputs for safety, meaning extreme emotional expressions (like very loud screaming) are limited.
Best Practices for Implementation
To maximize success with GPT-4o-Mini-TTS:
- A/B test different voices and vibes to find the optimal combination for your use case
- Implement streaming with appropriate buffering for smooth playback
- Establish fallback voice options for critical applications
- Conduct thorough QA for long-form projects, breaking content into manageable segments
- Test each target language individually to ensure quality meets requirements
- Monitor costs carefully, especially for high-volume applications
- Use observability tools like PromptLayer to track prompts, measure performance, and refine workflows over time
Beyond Sound: Why GPT-4o-Mini-TTS Redefines Synthetic Speech
GPT-4o-Mini-TTS is the moment synthetic speech finally learned to act. With a single prompt, your app transforms from a monotone reader to a nuanced performer who knows when to whisper, when to enthuse, and when to pause for dramatic effect. At $0.015 per minute, the barrier between mechanical output and genuinely expressive voice has collapsed.
Head to OpenAI.fm and type something ridiculous. Make it sound like a pirate reading tax code or a Shakespearean actor explaining JavaScript. When you hear that perfect inflection land exactly where you imagined it, you'll understand: your applications don't just have a voice anymore. They have range.
The era of truly expressive, controllable synthetic speech has arrived, and it's more accessible than ever.


