Code World Model: First Reactions to Meta's Release
Imagine an AI that doesn't just autocomplete your code but actually understands what happens when code runs. That's the revolutionary promise of Code World Models (CWMs) — a new breed of AI that bridges the gap between pattern-matching and true computational reasoning.
While traditional code AI learned to mimic syntax and structure, CWMs represent a fundamental shift: they model the execution world of code itself, tracking how variables change, predicting outputs, and reasoning through multi-step debugging tasks. Meta's groundbreaking 32-billion parameter CWM, released in September 2025, exemplifies this paradigm shift — achieving near state-of-the-art performance on complex coding benchmarks while remaining fully open for research.
This article dives deep into what makes Code World Models special, how Meta's implementation works under the hood, and why this technology matters for the future of AI-assisted programming. We'll explore the architecture, capabilities, and practical applications of these "thinking" code models that promise to transform how we build software.
Why Model the "World" of Code?
Traditional code-focused large language models like Codex or earlier versions of Code Llama excel at generating syntactically correct code by learning patterns from massive datasets. However, they treat code as static text sequences, predicting the next token based on what "looks right" rather than understanding what actually happens when code executes.
This fundamental limitation becomes apparent when dealing with runtime behavior. A model trained only on source code can learn syntax and common patterns, but it "does not understand the execution process" — it can't reliably predict how variables change during execution, anticipate error states, or reason about the causal effects of code modifications.
The core innovation of Code World Models is learning from observe-act-observe trajectories. Instead of just seeing finished code, CWMs are trained on execution traces that capture the dynamic state changes as programs run. They observe initial states, see actions taken (code execution), and learn from the resulting observations (outputs, errors, state changes). This creates an internal model of code behavior that goes beyond surface-level patterns.
The benefits of this approach are huge:
- Executability: CWMs generate code more likely to run correctly because they understand execution semantics
- Verifiability: The models can predict outputs and catch errors before running code
- Self-repair: When code fails, CWMs can reason about the failure and attempt fixes
- Long-horizon reasoning: Complex multi-step coding tasks become tractable when the model understands cause and effect
This paradigm builds on broader research in the field. Projects like SWE-RL applied reinforcement learning to software evolution tasks, while the GIF-MCTS (Generate, Improve, and Fix with Monte Carlo Tree Search) strategy showed how iterative refinement could improve code generation. The Code World Models Benchmark (CWMB), comprising 18 diverse RL environments, provides a standardized way to evaluate these capabilities.
Inside Meta's Code World Model (CWM)
Meta's CWM represents the most ambitious implementation of the code world model concept to date. At its core, it's a 32-billion parameter decoder-only transformer with 64 layers, but its architecture includes several innovations specifically designed for understanding code execution.
The model employs Grouped-Query Attention (GQA) with 48 query heads and 8 key-value heads per layer, reducing memory usage while maintaining expressiveness. It uses RoPE (Rotary Positional Embeddings) scaled to support extremely long sequences, and SwiGLU activation in feed-forward layers following modern best practices.
What truly sets CWM apart is its alternating attention mechanism for handling long contexts. The model interleaves local attention blocks (8,192-token windows) with global attention blocks (131,072-token sliding windows) in a 3:1 ratio. This means every fourth transformer layer can attend to the full 131k context, enabling the model to process entire codebases or lengthy debugging sessions without losing track of distant information.
The tokenization strategy is equally sophisticated. CWM uses an expanded 128,000 token vocabulary based on the LLaMA-3 tokenizer, with 256 special tokens reserved for reasoning markers like <think>, execution traces, and tool-use indicators. This large vocabulary efficiently encodes common code patterns and special formatting used during training.
The three-stage training pipeline reveals how CWM develops its unique capabilities:
1) Pre-training established the foundation with 8 trillion tokens at 8k context length. The corpus was approximately 30% code and 70% general text (English and STEM content), giving the model broad programming knowledge across multiple languages with a focus on Python.
2) Mid-training is where the "world modeling" magic happens. Over 5 trillion tokens at the full 131k context length, the model learned from:
- ~200 million Python memory traces capturing function calls, variable states, and execution flow
- ~3 million agent trajectories from AI agents solving coding tasks in 30,000+ containerized environments
- Specialized data including GitHub PR diffs, compiler intermediate representations, Triton GPU kernels, and Lean mathematical proofs
This mid-training phase taught CWM to internalize how code behaves when executed, not just how it looks.
3) Post-training refined the model through supervised fine-tuning (~100 billion tokens) introducing the explicit reasoning format, followed by reinforcement learning (~172 billion tokens) using GRPO (Group Relative Policy Optimization). The RL phase involved multi-task training on verifiable coding challenges, mathematical problems, and software engineering scenarios where the model received rewards for successful outcomes like passing tests or correct solutions.
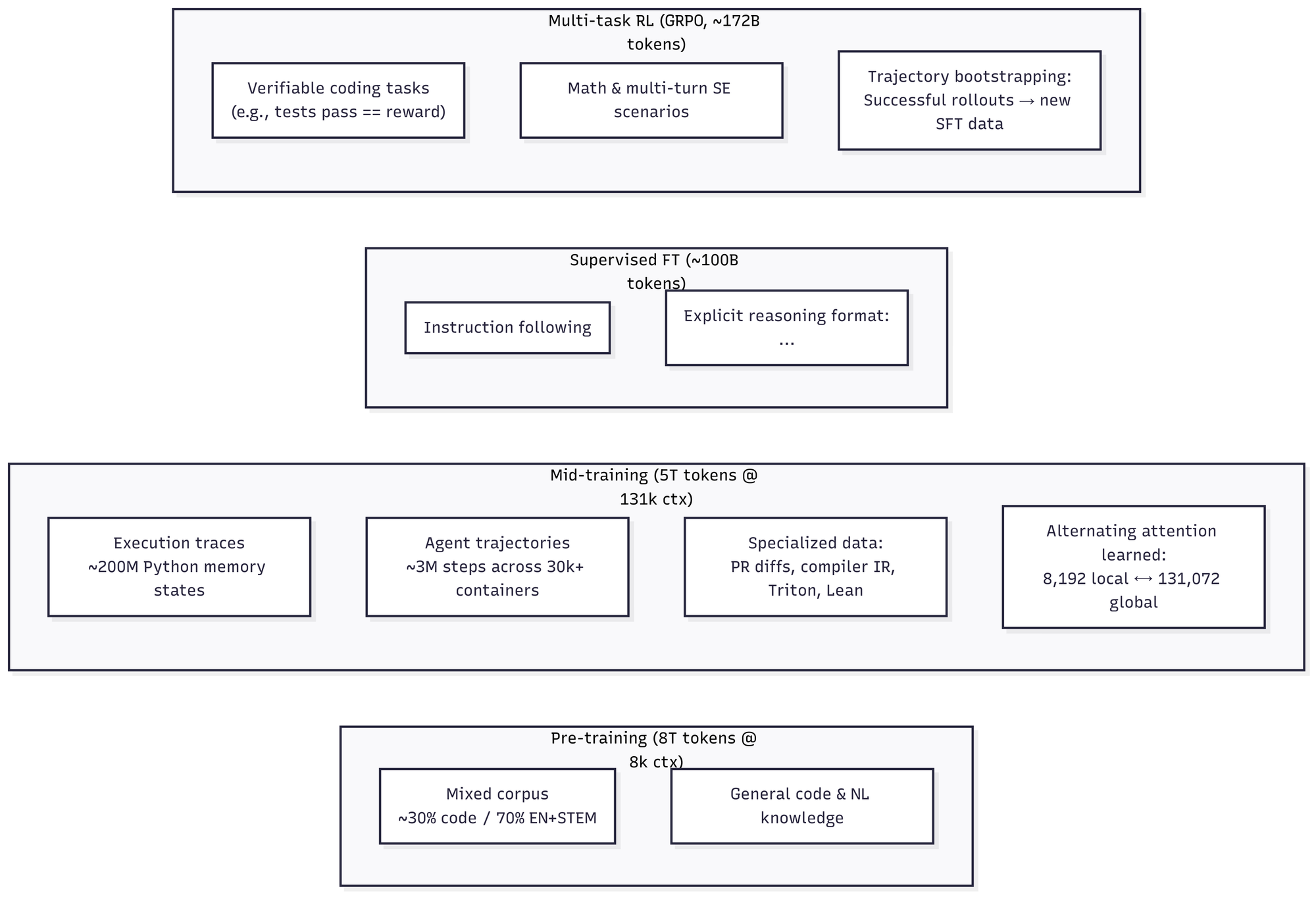
A clever bootstrapping technique fed high-quality trajectories generated by the model back into supervised training, creating a virtuous cycle that reinforced successful problem-solving patterns while reducing noise from suboptimal exploration.
What CWM Can Do (Capabilities)
The extensive training regimen endows CWM with capabilities that go far beyond traditional code completion:
Neural Debugger: CWM can simulate code execution internally, predicting variable values, execution flow, and outputs without running the code. Given a function and initial state, it traces through execution line-by-line, effectively serving as a "neural debugger" that understands how program state evolves. This is invaluable for catching logical bugs or reasoning about algorithm behavior.
Agentic Coding: Unlike passive code generators, CWM can engage in multi-turn problem-solving using tools. It can edit files, run tests, examine outputs, and iterate until a solution works. The model outputs actions in specific formats (like diffs or patches) and incorporates feedback from test results or error messages. This enables it to tackle tasks like "fix this failing test" through autonomous exploration and refinement.
Long-Context Reasoning: The 131k token context window allows CWM to analyze entire repositories, process extensive logs, or maintain context across lengthy coding sessions. The alternating attention mechanism ensures information from early in the context can still influence generation tens of thousands of tokens later.
Grounded Reasoning: Because CWM trained on real execution feedback, it excels at incorporating runtime signals into its reasoning. When given an error message or test failure, it can diagnose the issue and propose fixes based on its understanding of cause and effect. This grounded approach addresses the limitation where "text prediction alone can't reason through" complex software issues.
Thinking Mode: CWM uses an explicit chain-of-thought format with <think> tags separating internal reasoning from external responses. This transparency allows developers to see the model's problem-solving process, making it easier to verify correctness or debug mistakes. The thinking mode is enabled by default and significantly improves solution accuracy.
Self-Improvement via Bootstrapping: The model's training included feeding its own successful solutions back into the training data, allowing it to learn from its best outputs. This technique helps reduce noise and steadily improves performance on complex tasks.
Performance and Reception
CWM demonstrates state-of-the-art performance among open models across key benchmarks:
SWE-Bench Verified tests real-world software engineering tasks requiring code fixes. CWM achieves 53.9% pass@1 in standard mode, jumping to an impressive 65.8% with test-time scaling (generating multiple solutions). This rivals or exceeds some reports of GPT-4 on code repair tasks — remarkable for an open model.
LiveCodeBench evaluates dynamic code generation with execution verification. CWM scores 68.6% on v5 and 63.5% on v6, placing it at or near the top of open models in its size class.
Mathematical Reasoning showcases another strength. CWM reaches 96.6% on Math-500 (basic math word problems), demonstrating near-perfect performance. On the challenging AIME competitions, it achieves 76.0% on AIME-24 and 68.2% on AIME-25 — respectable scores for Olympiad-level problems.
Additional benchmarks reinforce CWM's capabilities:
- 94.3% on CruxEval-Output (coding puzzles)
- Top performance on BigOBench (algorithmic complexity reasoning)
- Strong results on RULER and LoCoDiff (long-context code understanding)
The community reception has been enthusiastic. MarkTechPost highlighted the breakthrough nature of world modeling for code, while 36Kr emphasized how CWM enables AI to "think like a programmer." The r/LocalLLaMA community praised both the benchmark achievements and the feasibility of running a 32B model locally with quantization.
This represents a shift from "autocomplete" to "thinking AI" for code. Researchers and practitioners recognize CWM as validation that understanding code execution, not just syntax, is crucial for advancing AI coding assistants.
Using CWM in Practice
Access and Licensing: CWM is available through Hugging Face under Meta's FAIR Non-Commercial Research License. The weights require registration and agreement to terms restricting commercial use. The accompanying code on GitHub uses a permissive BSD-3 license.
Hardware Requirements: Running CWM demands significant resources:
- Recommended: 160GB VRAM (e.g., 2x H100 GPUs) for full 131k context
- Minimum: Single 80GB GPU with 4-bit quantization
- Inference engines like vLLM or the provided Fastgen server help optimize performance
Critical Prompting Requirements:
The model requires a specific system prompt to function correctly:
You are a helpful AI assistant. You always reason before responding, using the following format:
<think>
[your internal reasoning]
</think>
[your external response]
Without this prompt, output quality degrades significantly. The <think> tags separate the model's chain-of-thought from its final answer.
For agentic workflows, append tool specifications describing available actions and their formats. This activates CWM's ability to interact with environments iteratively.

Best Practices for Long Contexts: When working with extensive codebases:
- Label files and sections clearly (e.g.,
// File: utils.py) - Guide attention to relevant parts in your prompt
- Structure information logically to help the model navigate
Practical Tips:
- Always enable thinking mode — benchmarks show 12% improvement with reasoning enabled
- Set up verification loops — let CWM run tests and incorporate results
- Monitor chain-of-thought — the
<think>content helps debug issues - Consider output filtering — strip
<think>blocks for end users if needed
Known Limitations:
- Not a general chatbot — lacks RLHF alignment for open-ended conversation
- English-only interface for prompts and explanations
- Formatting quirks possible from complex training data
- High latency on large contexts even with good hardware
- Safety considerations — may output problematic code without proper safeguards
- Knowledge cutoff around mid-2025
- Non-commercial only — cannot be used in production systems
Autocomplete to Understanding
Code World Models represent a paradigm shift in how AI understands and generates code. By modeling not just syntax but the actual execution and effects of code, CWM moves beyond pattern matching to genuine computational reasoning.
Meta's release of CWM matters for several reasons. It validates the approach — showing that training on execution traces and agent trajectories produces measurably better results.
Looking ahead, we can expect to see larger variants, multilingual support, cleaner output formatting, and deeper integration with actual execution environments. The techniques pioneered in CWM will likely influence the next generation of both open and proprietary coding models.
For now, CWM stands as proof that when AI learns to think about code the way programmers do — considering state, effects, and execution — it becomes a fundamentally more capable partner in software development. The shift from autocomplete to thinking AI for code has begun.


