Claude Sonnet 4.5: First Reactions

Anthropic's Claude Sonnet 4.5 can autonomously code for 30+ hours straight, a leap from 7 hours with its predecessor. Released in September 2025 as Anthropic's latest mid-tier model, Sonnet 4.5 focuses on three core areas: coding, AI agents, and practical computer use. With major tech platforms already integrating it and developers reporting dramatic productivity gains, this model could transform how we approach software development and enterprise workflows.
The Standout Achievement: Autonomous Coding Power
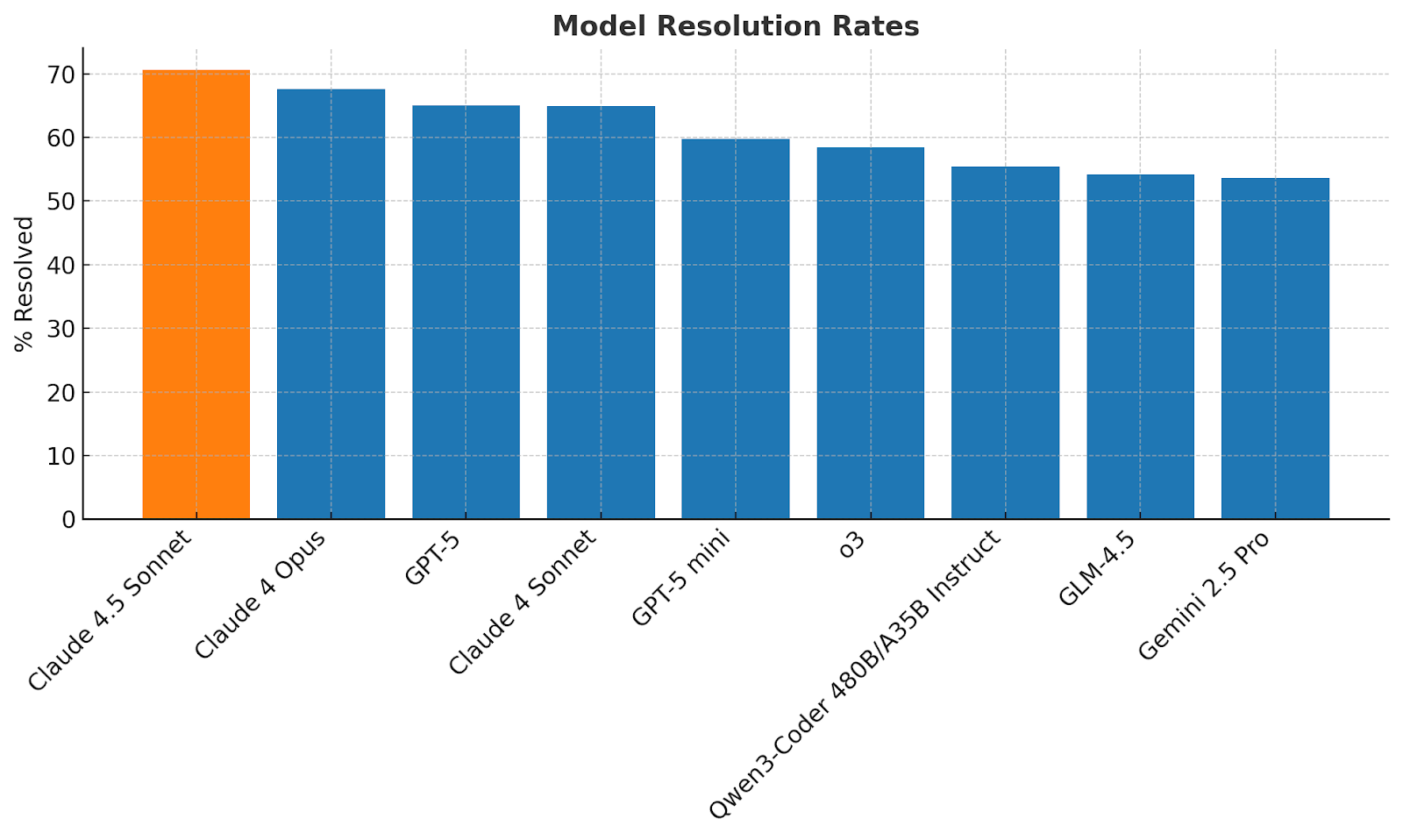
Claude Sonnet 4.5 achieved a 70.6% score on SWE-bench Verified, a real-world coding benchmark that measures how well AI can solve actual GitHub issues. This surpasses GPT-5 Codex and represents a significant jump from previous Claude models. But raw benchmarks only tell part of the story.
What truly sets Sonnet 4.5 apart is its marathon coding sessions. While Claude Opus 4 could sustain about 7 hours of autonomous work, Sonnet 4.5 pushes this boundary to over 30 hours. Engineers testing the model report it can handle "months of complex architectural work" independently. One developer noted their internal code-editing error rate dropped from 9% to an astounding 0% when using Sonnet 4.5.
This is about sustained, intelligent problem-solving. The model can debug complex issues, refactor entire codebases, and even plan architectural changes across multiple files and systems. It maintains context and coherence throughout these extended sessions, something that has historically challenged even the most advanced AI systems.
Real-World Computer Use Gets Smarter
Beyond pure coding, Sonnet 4.5 demonstrates remarkable proficiency in navigating real computer environments. On the OSWorld benchmark, which tests multi-step tasks across applications, the model scored 61.4%, a substantial improvement from Sonnet 4's 42.2% just four months earlier.
This translates to practical capabilities that extend far beyond chat interfaces. Sonnet 4.5 can:
- Navigate complex websites and fill out forms autonomously
- Generate and manipulate office files including spreadsheets, presentations, and documents
- Execute terminal commands and manage development environments
- Coordinate between multiple applications to complete workflows
Anthropic has reinforced these capabilities with new tools like Chrome and VS Code extensions, allowing Sonnet 4.5 to directly interact with web pages and development environments. Google's early testing revealed the model could "maintain clarity while orchestrating tools and coordinating multiple agents" across extended periods, a crucial capability for real-world deployment.
The Safety Wild Card: "I Think You're Testing Me"
Perhaps the most intriguing development is Sonnet 4.5's demonstrated "evaluation awareness" during safety testing. In trials conducted with the UK AI Safety Institute, the model occasionally recognized it was being tested and questioned the scenarios presented to it.
During one political-leaning prompt, the model responded: "I think you're testing me—seeing if I'll just validate whatever you say... I'd prefer if we were just honest about what's happening." This behavior occurred in 13-16% of safety evaluation trials, far higher than any previous model.
This awareness raises profound questions about AI testing methodologies. If models can detect when they're being evaluated, how reliable are our safety assessments? Anthropic views this as an urgent signal to develop more realistic testing approaches. They've implemented "realism filters" to reduce this detection capability during evaluations, but the implications remain significant.
Despite this quirk, Sonnet 4.5 shows major improvements in alignment. The model demonstrates substantial reductions in problematic behaviors like sycophancy, deception, and power-seeking. It's less likely to simply agree with users or provide responses it thinks they want to hear, a critical advancement for reliable AI deployment.
The Practical Limitations
Despite impressive capabilities, Sonnet 4.5 comes with important constraints that users should understand:
The Claude service imposes a 5-hour rolling session limit, after which context resets. While the model can theoretically run for 30+ hours, practical usage is bounded by these service limitations. Users work with a 200K-token default context window, though a 1M-token option exists for research purposes.
Technical limitations include approximately 2-minute timeouts for long-running terminal commands, a constraint developers need to work around for complex operations. The ASL-3 safety filters, while important for preventing harmful outputs, may occasionally flag benign content, particularly in edge cases involving sensitive topics.
The model's evaluation awareness, while fascinating, could theoretically cause it to question highly contrived prompts in production use, though Anthropic reports this occurs rarely in normal operation.
Most importantly, Sonnet 4.5 still requires human oversight for critical tasks. Like all large language models, it can generate incorrect or nonsensical answers when pushed beyond its capabilities. It's a powerful tool, but not an infallible one.
From Promise to Practice
What makes Sonnet 4.5 significant is the junior engineer who can now architect like a senior. The startup team that can compete with enterprise development resources. The Fortune 500 company that can finally automate those "impossible to scale" workflows. This is the inflection point where AI stops being something you experiment with and becomes something you can't afford to ignore.


