Claude AI Pricing: Choosing the Right Model

When Claude 3 launched as a major competitor in the AI landscape, and Claude Sonnet introduced its groundbreaking 1-million-token context window with new pricing, it became clear that understanding Claude's costs is crucial for anyone considering this AI assistant. This guide breaks down everything you need to know about Claude's consumer plans, team and enterprise tiers, API rates by model, cost drivers, and money-saving tactics.
Why does this matter? Clear cost understanding helps you scale effectively, choose the right tier for your needs, and manage context-driven pricing impacts on your budget. Whether you're a casual user exploring AI capabilities or an enterprise deploying Claude across thousands of employees, having transparent pricing information is essential for making informed decisions.
Plans and Prices at a Glance
Claude's subscription tiers create a clear ladder from free exploration to enterprise-grade deployment:
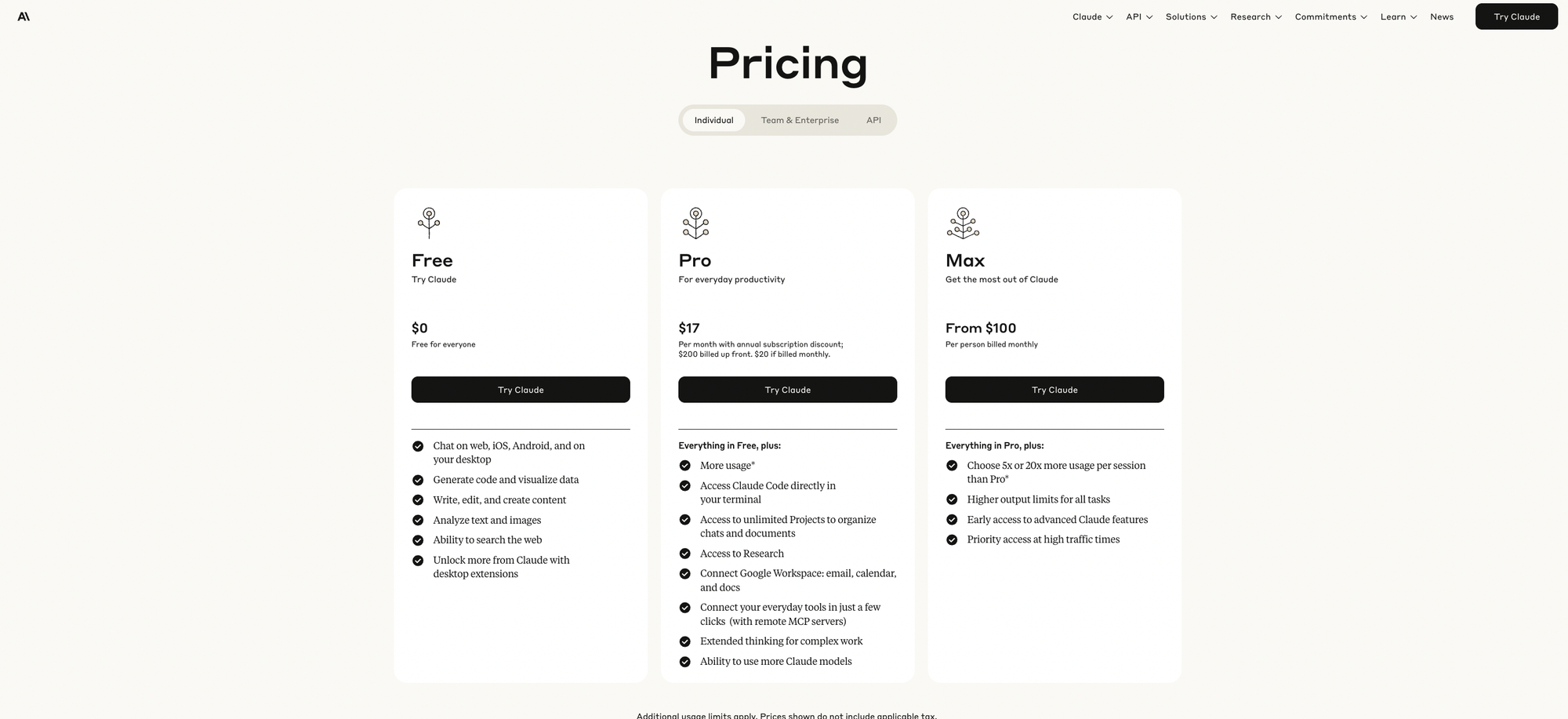
Free ($0/month): The free tier offers basic chat capabilities with limited daily usage. Users get access to the web "Research" tool and trial access to Claude's large context window. However, expect to encounter wait times during peak hours and message limits that reset daily.
Pro ($20/month or ~$17/month annually): This popular tier provides approximately 5× the usage of free accounts, roughly 45 messages per 5-hour window compared to about 9 for free users (varies by message length and model complexity). Pro users enjoy 200,000-token context windows, priority access during busy periods, Claude Code for terminal integration, unlimited Projects, and connectors for Google Drive, email, and calendar. You'll also get early access to new features as they roll out.
Max ($100 or $200/month): Designed for power users, Max offers either 5× or 20× Pro usage limits depending on your chosen tier. Max subscribers receive the highest priority access and earliest access to new models and features. This tier is built specifically for all-day heavy workflows where Claude becomes an integral part of your productivity stack.
Team ($25/user/month annually or $30/month): With a 5-user minimum, Team plans include all Pro features plus administrative controls and unified billing. Early collaboration features are rolled out to Team users first. For development teams, Premium seats at $150/user/month add Claude Code access for enhanced coding capabilities.
Enterprise (custom pricing): Large organizations get higher usage limits, potentially extended context windows beyond standard offerings, SSO integration, domain-level admin controls, audit logs, compliance features, and dedicated support. Pricing is negotiated based on specific organizational needs and scale.
API Pricing by Model (Pay-As-You-Go)
For developers integrating Claude into applications, Anthropic offers three model tiers with distinct pricing:
Claude 3.5 Haiku
- Input: $0.80 per million tokens
- Output: $4.00 per million tokens
The fastest and most economical option, Haiku excels at high-volume, simple tasks where speed matters more than complex reasoning.
Claude Sonnet 4
For prompts up to 200k tokens:
- Input: $3.00 per million tokens
- Output: $15.00 per million tokens
For prompts exceeding 200k tokens (up to 1M):
- Input: $6.00 per million tokens
- Output: $22.50 per million tokens
Sonnet represents the sweet spot for general-purpose applications and long-context tasks, with pricing that doubles when you exceed the 200k token threshold.
Claude Opus 4.1
- Input: $15.00 per million tokens
- Output: $75.00 per million tokens
The premium model for complex reasoning tasks, Opus delivers top-tier performance with a 200k context window and superior accuracy for demanding applications.
Add-ons and Tools
- Prompt Caching: Write ~$1–$18.75/million tokens; Read ~$0.08–$1.50/million tokens
- Web Search API: $10 per 1,000 searches
- Code Execution: Small fee after generous free allowance
- Batch Processing: 50% discount for asynchronous bulk jobs
API access is available through direct integration, AWS Bedrock, or Google Vertex AI across approximately 159 countries.
Which Option Fits Your Use Case?
Choosing the right Claude option depends on your specific needs:
Casual exploration: The free tier provides ample capability for testing Claude's features and occasional personal use.
Daily individual work (writing, analysis, coding): Pro subscription offers the best balance of features and usage limits for professionals who rely on AI assistance regularly.
Heavy power users working with large files and maintaining all-day conversations should consider Max at either the $100 or $200 tier, depending on intensity of use.
Small teams needing administrative controls and collaboration features should opt for Team subscriptions, with Premium seats for developers who need coding capabilities.
Regulated industries or large-scale deployments require Enterprise plans for SSO integration, compliance features, and custom usage limits.
For API users, model selection follows this pattern:
- High-volume, simple tasks → Haiku
- Balanced applications and long documents → Sonnet
- Highest accuracy and complex reasoning → Opus
How Usage Limits and Context Windows Shape Cost
Understanding how Claude calculates usage is crucial for cost management:
Session quotas vary significantly between tiers. While Pro users can send approximately 45 messages every 5 hours, free users are limited to about 9 messages in the same period. These limits adjust dynamically based on message length and model complexity.
Context thresholds create important pricing boundaries. When using Sonnet via API, input costs double from $3 to $6 per million tokens once prompts exceed 200,000 tokens. Output pricing increases proportionally from $15 to $22.50 per million tokens.
The 1-million-token context capability for Sonnet was initially rolled out to higher-tier API customers, with staged availability for broader access. This feature enables entirely new use cases but comes with trade-offs.
Important considerations: Ultra-long prompts not only increase costs but also add latency. Processing a 500,000-token prompt takes significantly longer than a 50,000-token one. Use extended context only when the task genuinely requires it.
Cost Control and Quick Examples
Smart usage patterns can significantly reduce your Claude costs:
Keep prompts concise whenever possible. Avoid exceeding 200k tokens unless your task specifically requires analyzing massive documents or codebases in one go.
Leverage Prompt Caching to amortize costs when working with the same long documents repeatedly. Cached reads cost a fraction of initial processing.
Use batch processing for non-urgent tasks to receive a 50% discount on API usage.
Monitor add-on costs carefully. Web searches and code execution can add up quickly if used liberally.
Reuse Projects and documents in the Claude.ai interface to avoid re-uploading the same content repeatedly.
Opus 4.1:
- 20k input tokens + 2k output tokens
- Cost: $0.30 + $0.15 = $0.45 total
Haiku 3.5:
- 50k input tokens + 1k output tokens
- Cost: $0.04 + $0.004 = $0.044 total
Making Smart Decisions
The strategic advantage lies in matching your specific workflow to Claude's pricing structure. Use prompt caching for recurring analysis, batch processing for non-urgent tasks, and careful model selection based on task complexity. Finally, adding observability through PromptLayer helps ensure you stay on budget while maintaining the same output quality. Whether you're a solo developer testing ideas or an enterprise deploying at scale, treat Claude's pricing tiers like a toolkit: pick the right tool for each job, not the fanciest one in the box.
PromptLayer is an end-to-end prompt engineering workbench for versioning, logging, and evals. Engineers and subject-matter-experts team up on the platform to build and scale production ready AI agents.
Made in NYC 🗽
Sign up for free at www.promptlayer.com 🍰


