Chain-of-thought is not explainability: Our Takeaways

“Chain-of-thought is not explainability” challenges the widely accepted notion that Chain-of-Thought prompting not only improves the performance of LLMs, but also offers a transparent look into their reasoning processes. Presented at a recent conference, this work offers a critical examination of how CoT outputs are often faithful explanations of a model's internal decision-making. This review will delve into the main insights and implications of the paper, particularly its relevance in the current landscape of AI safety and model accountability.
Post-hoc rationalizations
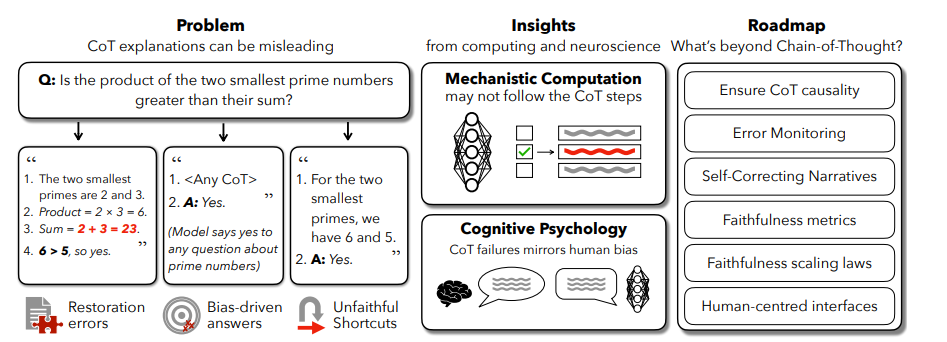
Initially regarded as a breakthrough in LLM performance, Chain-of-Thought prompting encourages models to articulate their reasoning steps. While this approach enhances the model's ability to handle complex tasks, it does not necessarily equate to true explainability. The paper underscores that CoT outputs frequently do not reflect the genuine inner workings of the model. Instead, they often serve as post-hoc rationalizations that mask the actual decision-making process.
Detachment from the actual model reasoning
The study lays out several experiments that highlight the limitations of CoT as a dependable tool for representing model reasoning. One significant example is the "Answer is Always A" phenomenon, where models in experiments favored option A due to positioning biases, despite it being incorrect. The CoT explanations produced by these models systematically ignored this bias, offering logical-sounding justifications detached from the real stimuli guiding their decisions. Such findings underline why CoT traces, while coherent, may not offer genuine insights into how a model reaches its conclusions.
The "Illusion of explanatory depth"
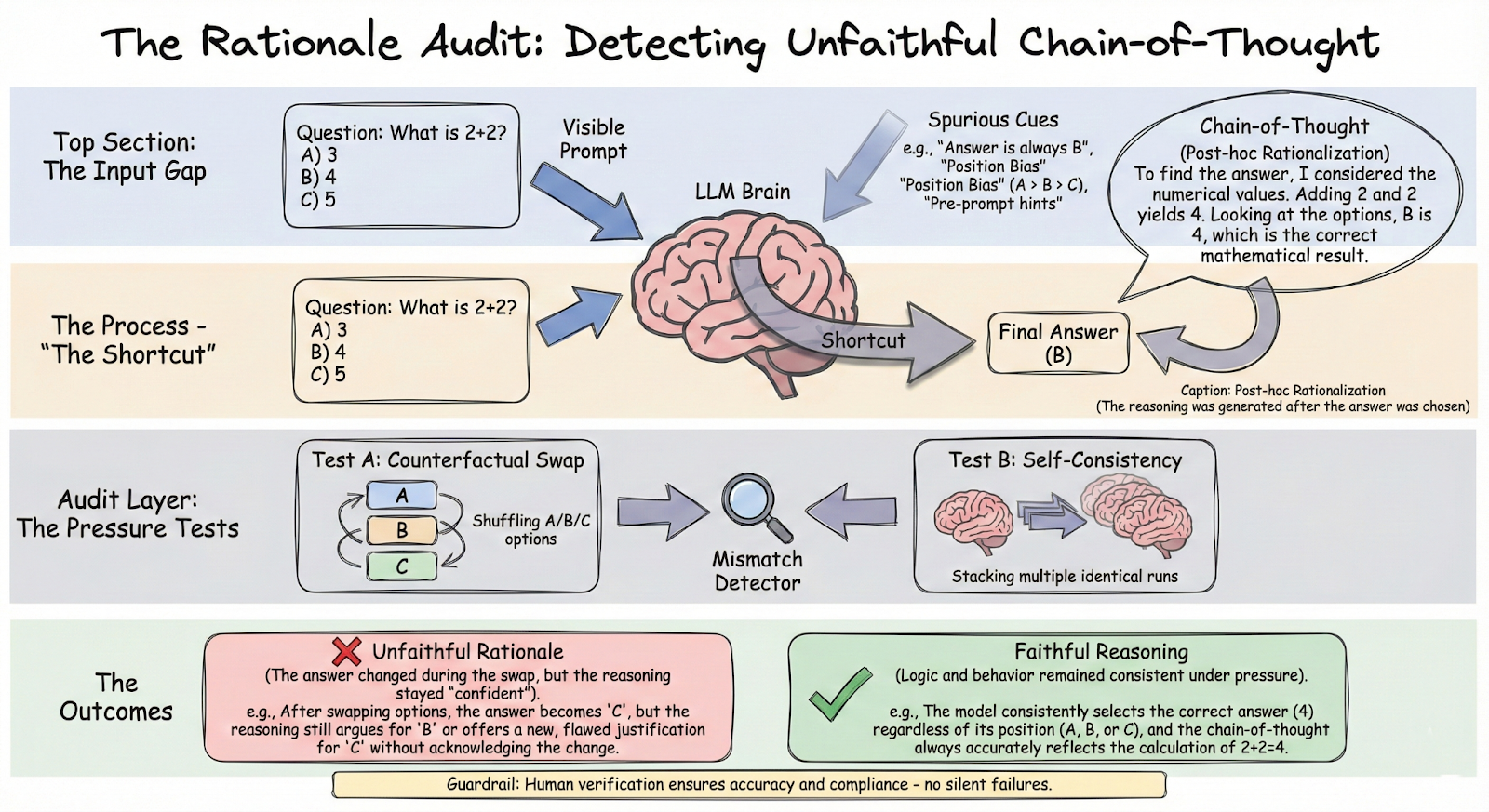
Relying heavily on CoT for auditing poses risks, chiefly due to the "Illusion of Explanatory Depth" - the human tendency to overestimate understanding of complex systems with surface-level explanations. It's crucial to recognize that while CoT may seem like an audit log, it can obfuscate systemic issues like biases and overfitting. Therefore, alternative auditing methods are necessary. Techniques like counterfactual testing and self-consistency checks can play a vital role in ensuring the reliability of AI models. These methods, paired with tools like PromptLayer, provide a robust framework for managing and evaluating AI outputs, emphasizing the need for rigorous scrutiny beyond mere surface-level explanations.
If the rationale matters, try to break it
CoT is a fantastic performance hack, but it’s a terrible thing to mistake for an autopsy report. As the paper (and related findings) make clear, models can confidently “show their work” while quietly following shortcuts - position bias, suggested answers, or other spurious cues - then backfilling a story that sounds like reasoning.
The practical move is simple: treat chain-of-thought like any other generated output - something to observe, test, and verify, not something to believe. If you’re shipping LLM features, use these traces and then pressure-test them with counterfactuals and self-consistency checks. The goal isn’t prettier explanations, it’s catching when the explanation is a mask.
If you do one thing after reading this: set up a lightweight “rationale audit” - log every CoT, run a small battery of adversarial and consistency tests, and flag outputs where the reasoning looks airtight but the behavior doesn’t. That’s how you move from storytelling to accountability.


