Benchmarking Gemini 3.1 Pro: Latency, cost, and reasoning trade-offs

Google's Gemini 3.1 Pro represents a meaningful step forward for developers building applications that require advanced reasoning. Announced in February 2026, the model promises smarter problem-solving without forcing users to pay more for the privilege. At PromptLayer, where teams manage prompts and evaluate model performance, we're examining what its benchmarks and specifications reveal about where it fits in the current landscape - just days after launch.
This piece examines three dimensions that matter most when evaluating a new model: reasoning performance, response latency, and pricing. Understanding how these factors interact helps developers make informed decisions about when Gemini 3.1 Pro is the right tool and when a lighter alternative might serve better.
The reasoning benchmarks tell an interesting story
Gemini 3.1 Pro delivers a substantial improvement in reasoning performance over its predecessor. On the ARC-AGI-2 logical reasoning benchmark, it scored 77.1% - more than double what Gemini 3.0 Pro achieved. That jump signals genuine progress in handling novel logic puzzles and complex analytical tasks.
In Google's internal evaluations, 3.1 Pro outscored rival models from Anthropic and OpenAI on the majority of benchmarks tested. It edged out Anthropic's Claude Opus 4.6 and a preview of OpenAI's GPT-5.2 on several reasoning and multitask exams. The model has also demonstrated creative capabilities, generating SVG animations and coding elaborate projects in single passes.
But context matters here. No single model wins every test. On the full "Human's Last Exam" evaluation and certain coding benchmarks, an advanced Claude model still held the top spot. The takeaway is that Gemini 3.1 Pro positions itself among the most capable reasoning models available, particularly for complex analytical work, without claiming universal dominance.
Adjusting thinking levels changes everything
One persistent challenge with highly intelligent models is that deeper reasoning means slower responses. Gemini 3.1 Pro addresses this with configurable thinking levels that let developers balance accuracy against response time.
The model supports three settings:
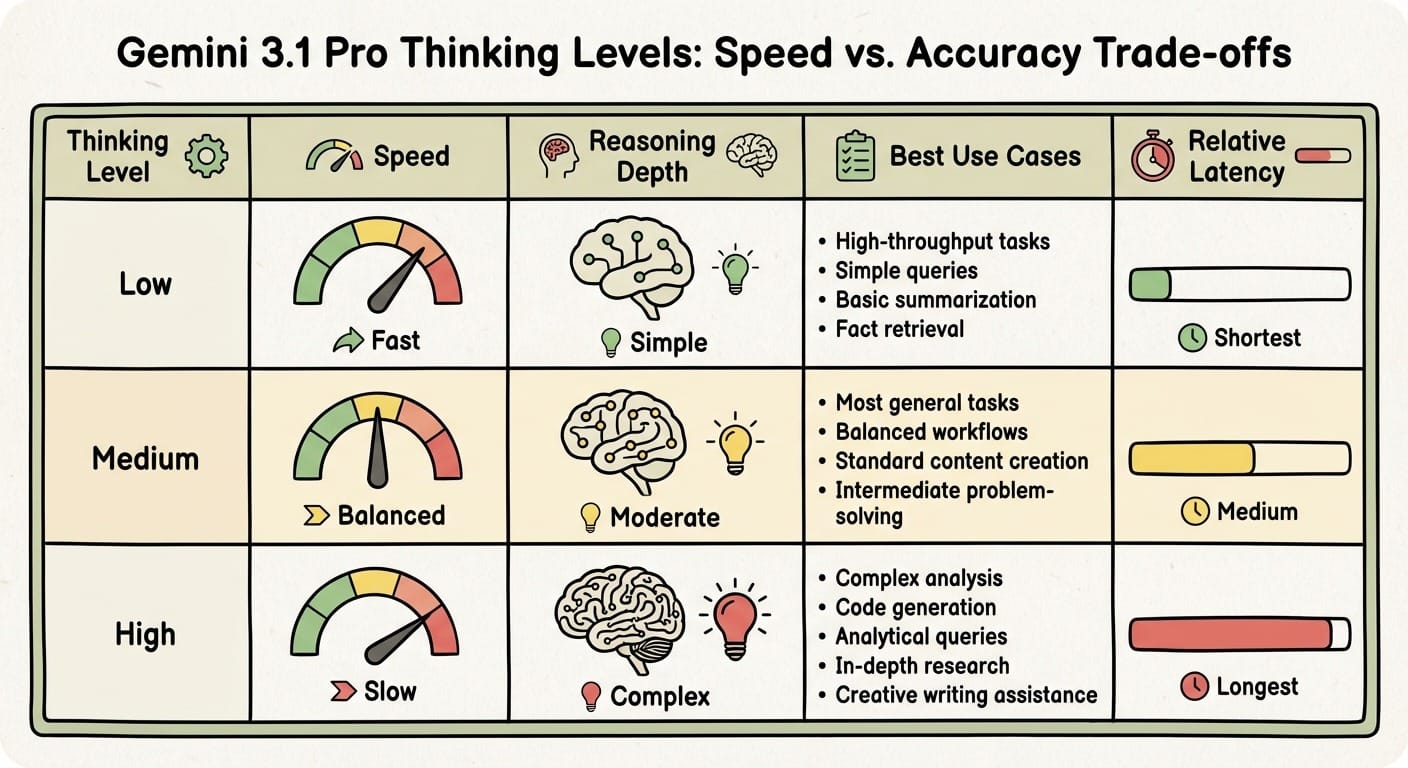
- Low: Fastest responses for simple or high-throughput tasks with minimal reasoning overhead
- Medium: Balanced depth for most tasks, offering a middle ground on latency
- High (default): Full reasoning engagement for complex problems, thorough but slowest
This approach replaces the older method of manually setting a "thinking budget" in tokens. Developers no longer need to calculate token limits themselves - the model self-regulates reasoning depth at each level. For real-time interactions where quick answers matter, the low setting yields faster replies. For complex code generation or analytical queries, high mode engages the model's full capability.
The model also retains multimodal support for text, images, audio, and video, along with a one million input tokens context window. Using very large contexts or high reasoning depth naturally increases latency, but the key is that users control the trade-off rather than accepting a fixed configuration.
Pricing stays competitive despite improved performance
Gemini 3.1 Pro's API pricing remains unchanged from the previous generation, which reflects Google's strategy of delivering more value at the same cost. The model uses tiered token billing: for prompts up to 200k tokens, users pay $2 per million input tokens and $12 per million output tokens. Prompts exceeding 200k tokens cost $4 and $18 per million respectively.
This positions Google aggressively against competitors. One analysis described Gemini 3 Pro as offering the best value, with reasoning API calls running at roughly 85% lower cost than OpenAI's top-tier models. At approximately $0.002 per thousand input tokens, Gemini undercuts GPT-4's equivalent pricing by an order of magnitude for reasoning tasks.
The comparison with Gemini 3 Flash is also instructive. Flash runs about three times faster than the older 2.5 Pro model and costs roughly four to five times less than 3.1 Pro. The trade-off is that Flash provides "Pro-grade reasoning at Flash-level speed" - capable for many tasks but not as strong on truly complex reasoning. This highlights the cost-performance choices within Google's model family and reinforces that users must select the right tool for specific needs.
Finding the right balance for your application
Gemini 3.1 Pro is not just "smarter", it is tunable. You can pay the same rates as last generation, then decide request by request whether you want raw depth (High), a practical middle (Medium), or speed-first throughput (Low).
If you're evaluating it for production, treat thinking level like a first-class config, not an afterthought. Run your own prompts across levels, log latency and token usage, and reserve High for the moments that actually need it. When the job is routine, dial it down, or reach for Flash instead.
The teams getting the most out of 3.1 Pro are not chasing a single benchmark score, they're building a workflow. Start benchmarking in PromptLayer, set a default, and make "thinking level" part of your API contract so your app can reason hard only when it counts.


