Agentic RAG: Embracing The Evolution

Imagine an AI assistant that doesn’t just retrieve documents from a static index, but actively plans, reasons, and adapts - diving into multiple knowledge sources, rerouting based on ambiguous queries, and validating its own outputs. This, in a nutshell, is the promise of Agentic Retrieval-Augmented Generation (RAG).
As LLM-powered products demand more reliability, context awareness, and transparency, the shift from “vanilla” RAG to agentic RAG is underway - and it’s reshaping how we build, debug, and trust advanced AI systems.
Let’s dive into what “agentic” really means in this context, how it differs from classic RAG design patterns, and how platforms like PromptLayer make agentic RAG operable and observable in the real world.
From Vanilla RAG to Agentic RAG
The Shortcomings of “Plain” RAG
Traditional RAG is a powerful concept: pair an LLM with an external knowledge base, retrieve relevant documents, and let the LLM generate a response. This “retrieve-then-generate” architecture delivers up-to-date responses… in theory.
But in practice, vanilla RAG is static. It grabs context once, feeds it to the model, and hopes the answer is accurate. This falls short for:
- Ambiguous queries (where a clarifying question is needed)
- Complex reasoning (multi-step problems)
- Cost efficiency (every query retrieves the same way, regardless of difficulty)
There’s no room for the system to plan, adapt, or “know what it doesn’t know.”
Enter Agentic RAG: The Move Toward Autonomous Agents
Agentic RAG changes this picture. Instead of a rigid pipeline, you introduce agents - LLMs that decide, step-by-step, how to tackle a query. These agents can:
- Decide if and when to retrieve.
- Iteratively reformulate queries or route them to different tools.
- Verify their own answers before showing them to the user.
Beyond the Basics: Common Agentic Patterns
How do you actually build this? You don't need to invent a new architecture from scratch. Researchers and engineers have identified reliable design patterns that turn chaotic reasoning into structured workflows.
Here are the three most effective patterns you can implement today:
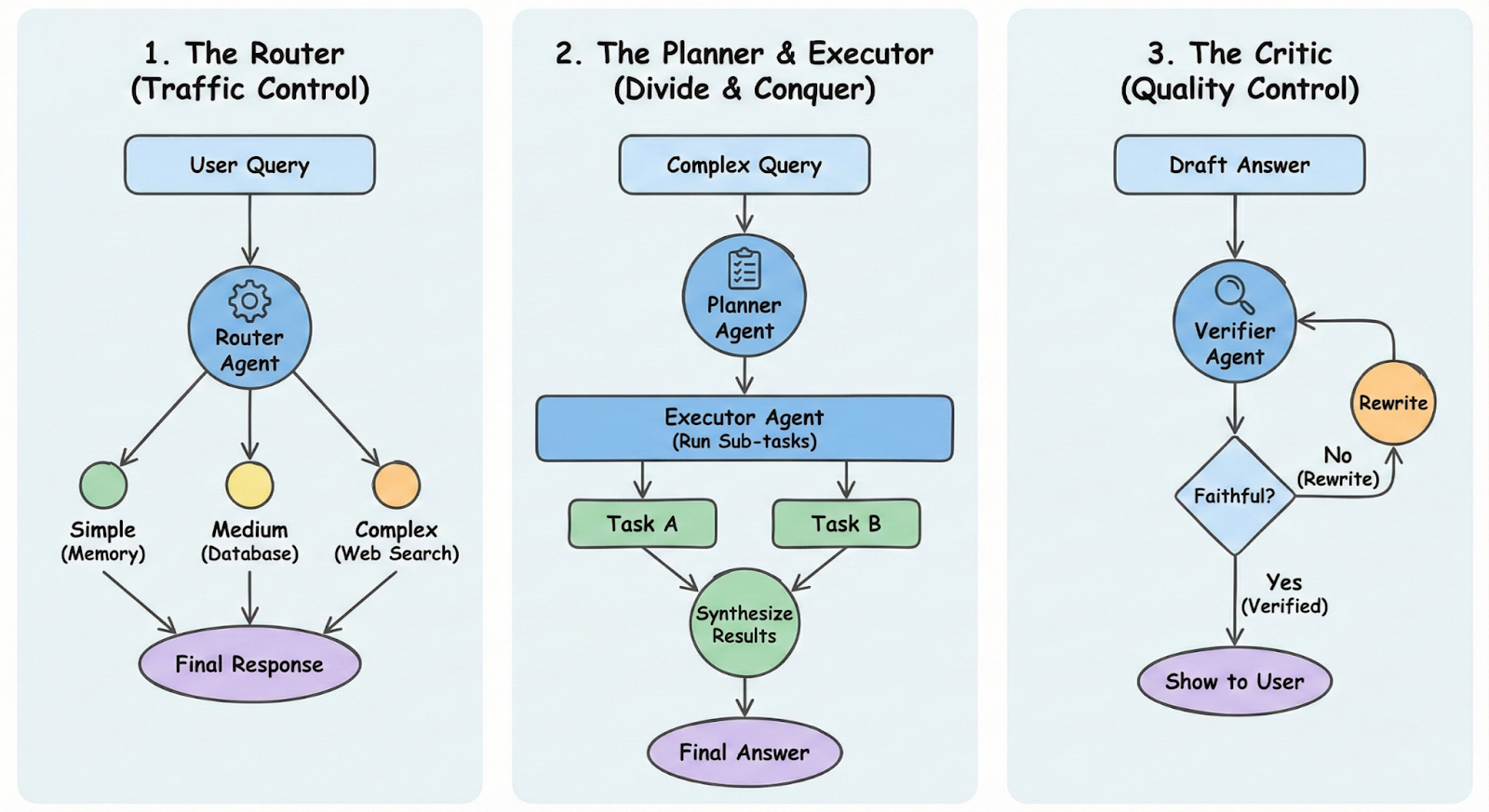
The Intelligent Router (Traffic Control)
Instead of treating every query the same, a "Router" agent analyzes the user's intent first.
- The agent decides if the question is simple enough to answer from memory, requires a database lookup, or needs a web search.
- It saves money and reduces latency. You don't burn tokens retrieving documents for a user who just said "Hi."
See it in the wild: This mirrors the Single-Agent Retriever pattern found in frameworks like LangGraph, where the agent acts as a gatekeeper for expensive tools.
The Planner & Executor (Divide and Conquer)
For complex questions (e.g., "Compare the revenue growth of Apple vs. Microsoft over the last 5 years"), a single retrieval step often fails because the information lives in different documents.
- A Planner agent breaks the query into sub-tasks ("Get Apple revenue," "Get Microsoft revenue," "Calculate growth"). An Executor agent then runs these steps sequentially or in parallel before synthesizing the final answer.
- It handles multi-hop reasoning that baffles standard RAG.
Papers like MA-RAG show that separating "planning" from "retrieving" significantly reduces hallucinations in complex topics.
The Critic / Self-Corrector (Quality Control)
This is the "safety net" pattern.
- Before showing the answer to the user, a separate Verifier agent critiques the draft. It asks: "Does this answer actually cite the retrieved documents?" If not, it sends the draft back for a rewrite.
- It drastically improves "faithfulness" - ensuring the AI isn't making things up.
Systems like RAGentA and active verification loops have demonstrated double-digit improvements in accuracy simply by adding this self-reflection step.
The Crucial Role of Observability
With greater intelligence comes greater complexity. Agentic RAG introduces loops, branches, and non-deterministic behavior. This adds up to a debugging nightmare if you don’t have the right observability stack.
Unique Challenges
- Tracing Decision Paths: Why did the Router choose a web search for a simple question?
- Attributing Errors: Did the answer fail because the Planner made a bad plan, or because the Retriever couldn't find the doc?
- Monitoring Cost: An agent getting stuck in a loop can explode your API bill in seconds.
Without transparency into every step, Agentic RAG becomes a "black box."
Observability Requirements
To run this in production, you need:
- Span Tracing: Every thought, tool call, and retrieval must be a traceable span.
- Prompt-Specific Analytics: You need to know which specific prompt (Planner vs. Critic) caused a failure.
- Cost Metrics: Token usage tracked per-agent, not just per-request.
The "Build vs. Buy" Trap
Faced with these requirements, engineering teams often attempt to build their own logging stacks. However, this quickly becomes a resource sink. Unlike linear API calls, agentic workflows are non-deterministic and deeply nested. Trying to force-fit these dynamic execution trees into rigid SQL tables or standard APM tools usually results in a mess of unreadable logs. You lose the context of why an agent made a decision, and debugging becomes an exercise in forensic data science rather than simple error tracking. PromptLayer addresses these gaps by logging full request metadata, nested spans, and costs at each step. This turns Agentic RAG from a risky experiment into a predictable system.
Real-World Example: Building a Financial Analyst Agent
Theory is useful, but let’s look at a concrete implementation of "Stock Buddy" - an agent designed to answer questions about the New York Stock Exchange. This example perfectly illustrates the Planner, Executor, and Critic patterns in action.
The Workflow: Decomposing the Black Box
Instead of a single black-box call, the workflow is decomposed into distinct, observable spans:
- Step 1: Retrieval (The Tool) The system first hits a custom API endpoint to fetch raw JSON data about specific stocks.
- Step 2: Generation (The Agent) The "Stock Buddy" agent takes the user’s question and the raw JSON to synthesize a human-readable answer.
- Step 3: The Critic (The Evaluator) This is the "agentic" unlock. A separate "Evaluator Agent" (running on GPT-4) analyzes the generated answer against a set of ground-truth facts to determine if the answer is accurate.
From "Guessing" to "Optimizing"
The initial agent configuration only achieved a 72% accuracy rating. Because the workflow was observable in PromptLayer, the developer could see exactly where it failed - specifically in how the agent interpreted the retrieved JSON. To understand why the system was failing, let's look at the actual trace data that PromptLayer revealed.
The Loop: Closing the Gap
By tweaking the prompt instructions (iterating on the agent's "reasoning"), they re-ran the evaluation pipeline and boosted accuracy to 80% in minutes. This process - building a reliable "Evaluator" offline - is the exact blueprint you need to build a Self-Correction Agent that runs online.
Key Takeaway: You cannot build an Agentic RAG system without the ability to trace these multi-step flows. The ability to visualize the Retrieval → Answer → Critique loop is what turns a prototype into a production-ready system.
Turning the Black Box into a Glass Box
Agentic RAG represents a turning point for retrieval-augmented AI. We are moving from brittle, one-shot pipelines to adaptable, traceable reasoning flows. The early numbers are compelling: measurable gains in fidelity and accuracy.
But these gains come with operational headaches. The path forward is clear: Agentic RAG is only worth the investment if you pair it with first-class observability. Platforms like PromptLayer allow you to trace, tune, and trust your agents - turning a black box into a glass box.
Start by tracing every agent’s decision, and you’ll build not just smarter AI, but AI you can understand, govern, and continuously improve.


