A How-To Guide On Fine-Tuning
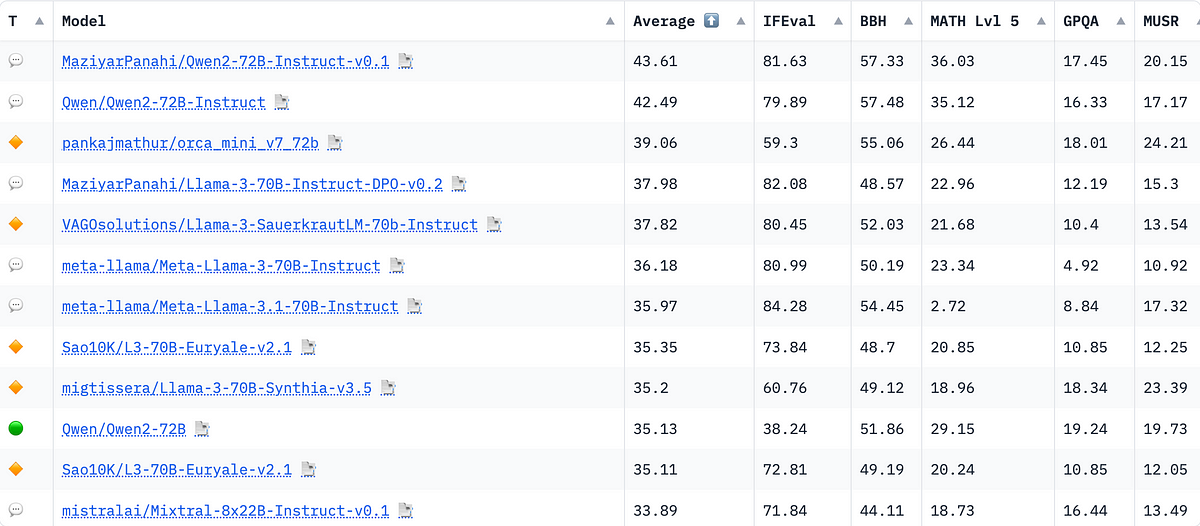
We’ve previously explored the pros and cons of fine-tuning and its potential value for you and your team. For an in-depth look at that topic, refer to our earlier article. In this piece, we’ll dive into the mechanics of fine-tuning and demonstrate its effectiveness through two examples.
So first — What is Fine-Tuning? Put simply, fine-tuning is the process of training a base LLM on new examples, to slightly adjust model behavior. It tends to be most effective for 3 main use cases:
- Forcing a specific output format
- Adjusting tone/writing style
- Complex reasoning
Overview of the Fine-Tuning Process
On paper fine-tuning does not seem that complex. All you need to do is, choose a base LLM, find the data you want to use for the fine-tune, edit the data format to match the LLM, and then run the fine-tune on the model. In practice, you’ll see it is a tad more complex. Finding the data, transforming it, creating the pipeline, setting up the training, and then putting the model into production each time you want to update the model is enough to give you a mid-level migraine.
We’ll explore two scenarios: first, a manual fine-tuning process from the ground up, and second, a streamlined approach using PromptLayer!
Example 1 — Making a Model Write Like I Would:
In this example, we’ll adjust the tone of the model, utilizing some of my own old notes app entries. This presents a nice challenge due to formatting issues that are likely to show up when utilizing a non-pristine data set.
You can use numerous base models to fine-tune, all with individual strengths and weaknesses. Some of the most notable differences include the performance and data format. All the open-source models support fine-tuning, but the most popular tend to be the LLaMA models and Mistral. Of the closed-source models, OpenAI allows for fine-tuning for models up to GPT-4 whereas Anthropic does not currently allow for fine-tuning yet. Most tend to go with open-source models as it is less opaque and you can truly understand the model architecture. For this first example, we’ll use Mistral’s Mixtral 8x7B.
Now that we’ve chosen a model, the next step is to figure out the data we want to train it with! Sourcing the data from my Apple Notes app and my old high school essays solves the problem of finding a lot of text that I’ve handwritten. However, it comes in a very diverse set of formats. For example, the exporter app converted all my notes to markdown (.md files), whereas my essays are stored mainly as PDFs/.DOCX files. To train our model, JSON is the easiest file format. Luckily, ChatGPT is really good at dealing with all these files, and simply asking it to make a script does 99% of the work for you.

Here, we want to convert our notes into a prompt and answer-type format. This will help the model respond to prompts in a natural writing style similar to how I would write. One example would be something in the format:
- Q: What do you love about Natural Language Processing?
- A: I love NLP because it blends the precise nature of computing with the fluidity of language. Since 2017, it’s also been fascinating to see NLP evolve as well, seeing it evolve to be one of the pre-eminent fields of machine learning.
The model learns my writing style by training on pairs of prompts and corresponding excerpts from my notes. This teaches it to generate responses mimicking my style when given similar prompts.
This comes with its own issues though. There are three main ones:
- The examples are very skewed in terms of length (numerous short notes and a few longer essays)
- Many data samples have parts with multiple subjects
- Almost none of the notes are labeled with an appropriate prompt
This also brings up the question of how many examples we really need. While there is no one-size-fits-all, the larger the training set, the better. I unfortunately do not have that many notes/essays saved (or possibly ever written), adding on a fourth issue:
- Not enough training examples (yet)
Normally, these would be huge issues to deal with. However, we can use some data science techniques to fix these issues. Specifically, we want to split our essays into smaller writing samples by topic. This will increase the number of examples we have, fix the issues with length, and make sure each example is focused on a singular subject.
Here’s where LLMs come in!
We can use an LLM to do this splitting work for us. We can then also use the LLM to create a prompt associated with each chunk of writing to solve our last issue of the missing prompts. Doing this manually would take eons, so this saves us a ton of time. Here, I’d recommend Gemini as it has a free tier API you can use. This is great to save some money since we are going through 1,000s of calls to perform this work. You can see below the prompt I used and what the output format we’re getting looks like.
Prompt:
"Generate {num_questions} question and answer pairs based on a given note.:
<note>
{note}
</note>
***Here are some examples to base your response off of.
Note:
My leadership philosophy is to lead from behind / alongside people. I've often found that people take leadership as an excuse to shirk responsibility. To me it should be the exact opposite. The privilege to lead means picking up as much as responsibility as everyone else, on top of the added responsibilities that a leader takes on. In this way, I try to be a leader in many ways in my life. From being involved in club leadership for FBLA or on my National Economics Challenge team, or even in being a leader in a less formal sense in my relationships with my family and friends and in mock trial, I try to uplift those around me and drive towards positive goals.
**Q1:** What is my leadership philosophy?
**A1:** To lead from behind/alongside people. This means not shirking or sidelining responsibility, but taking on the same amount as everyone else.
**Q2:** What does the privledge to lead entail?
**A2:** The privilege to lead means picking up as much as responsibility as everyone else, on top of the added responsibilities that a leader takes on.
####Respond in the format for question x:
**Qx:** [Question]
**Ax:** [Answer]
###Do not hallucinate in the answers. Only generate questions that can be answered from the note. Do not write 'the note' in either the question or the answer. Be very certain of your answers. DO NOT WRITE QUESTIONS YOU DO NOT KNOW THE ANSWER TO."
Now that we have a ton of examples in the correct format, we can proceed with the actual fine-tuning process itself. This part is pretty standard and can be taken straight from the Mistral website. I recommend using Hugging Face’s model hub to interface with and save the models.
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
variables = {
‘Essay’: """When I first stepped into classroom, the Elementary School Math Club was shocking - the loud and overwhelming energy of the children [... essay continues]"""
}
essay_template = promptlayer_client.templates.get("essay_rewrite_template", variables)
prompt = essay_template['llm_kwargs']['messages'][1]['content'][0]['text']
result = pipe(prompt)
print(result[0]['generated_text'])
And viola! We have our fine-tuned model. You can see that its writing style is slightly different. However, this is not really how I would naturally write. Now this probably comes down to a couple of factors:
- Base Mistral isn’t all that powerful compared to what we’re used to with Claude Opus/GPT-4o’s writing
- We haven’t provided all that many training examples in the grand scheme of things (a couple of thousand is workable but non-ideal)
- We haven’t messed around with the hyperparameters/input variables.
Fine-tuning presents frustrating challenges. While access to powerful models is improving with releases like Llama 3.1, the time-intensive data preparation and difficulty in iterating on fine-tuned models remain significant hurdles. These latter issues often force us to restart the entire process from scratch. This means sourcing more examples, running more LLM calls to fix the data, and then re-training the model entirely. Thus, improving our fine-tuning is a very repetitive, time-consuming, and computationally expensive task.
Example 2 — Fine-Tuning a Workout Generator With PromptLayer:
The game plan here is to use GPT-4 to generate workout data for us to fine-tune a GPT-3.5 model, making a significantly cheaper model.
Luckily, this is a 10x simpler process. First, I created a quick prompt I’d use to generate a workout plan in GPT-4.
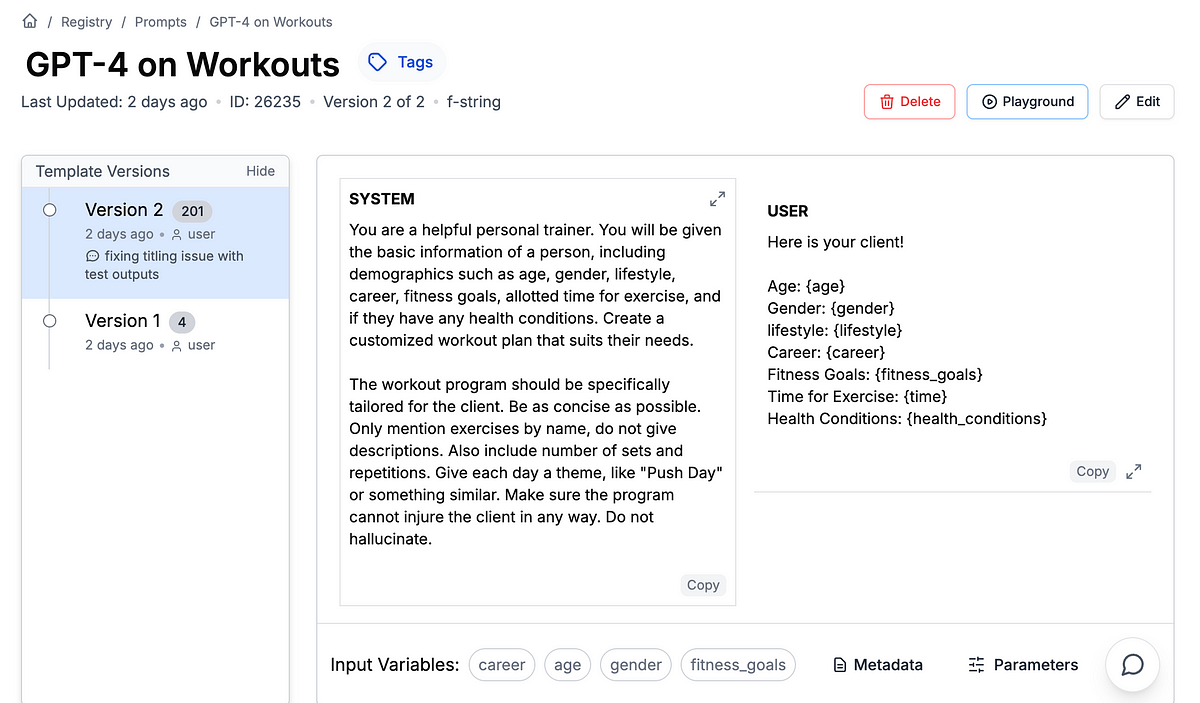
From there, we need to create the data to train with, so we use a quick ChatGPT prompt asking it to create a CSV with 100 examples.
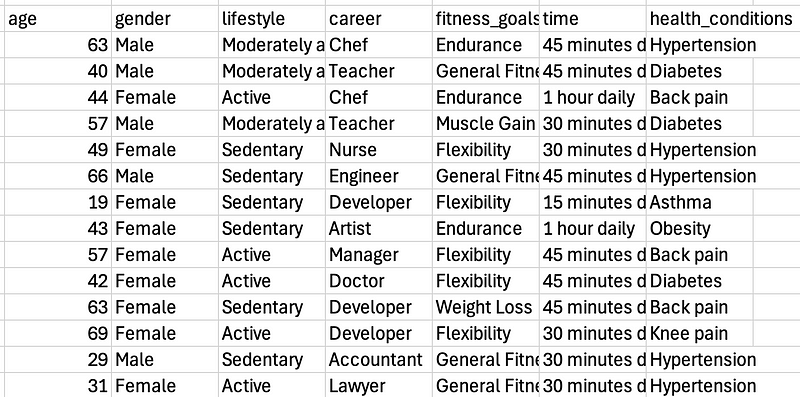
Then, after creating a dataset with it in PromptLayer, we run an eval pipeline to create the 100 test examples.
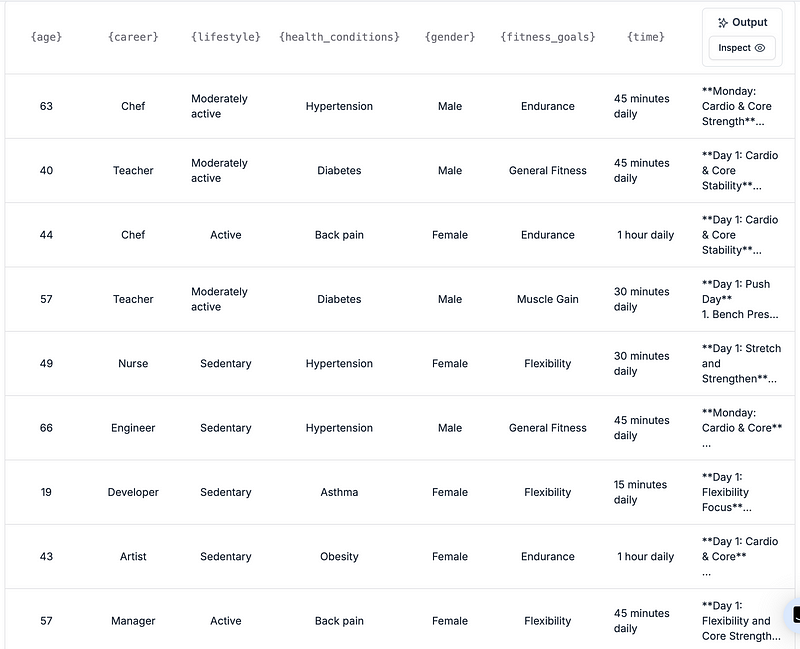
And now, we simply make our selection of prompt request history and then click to fine-tune the model.
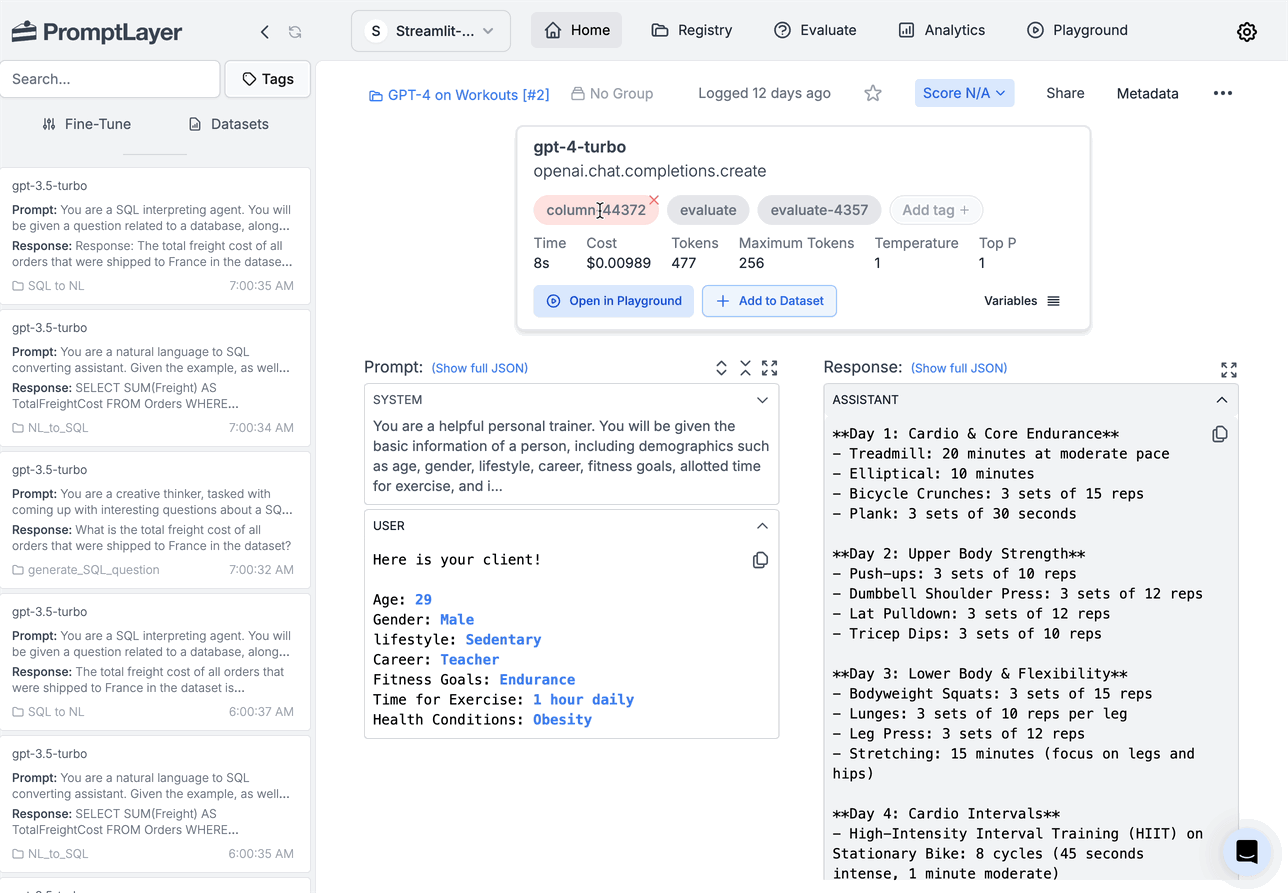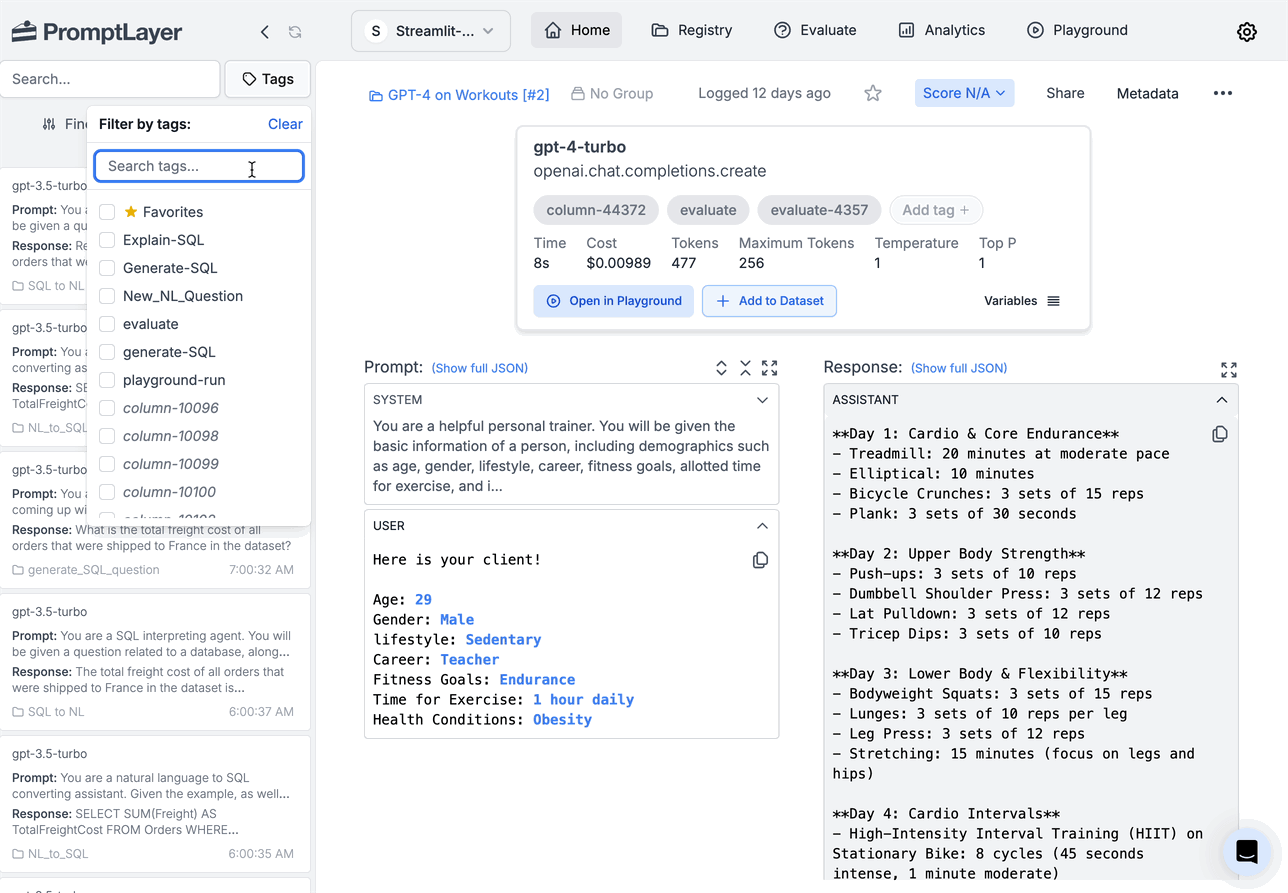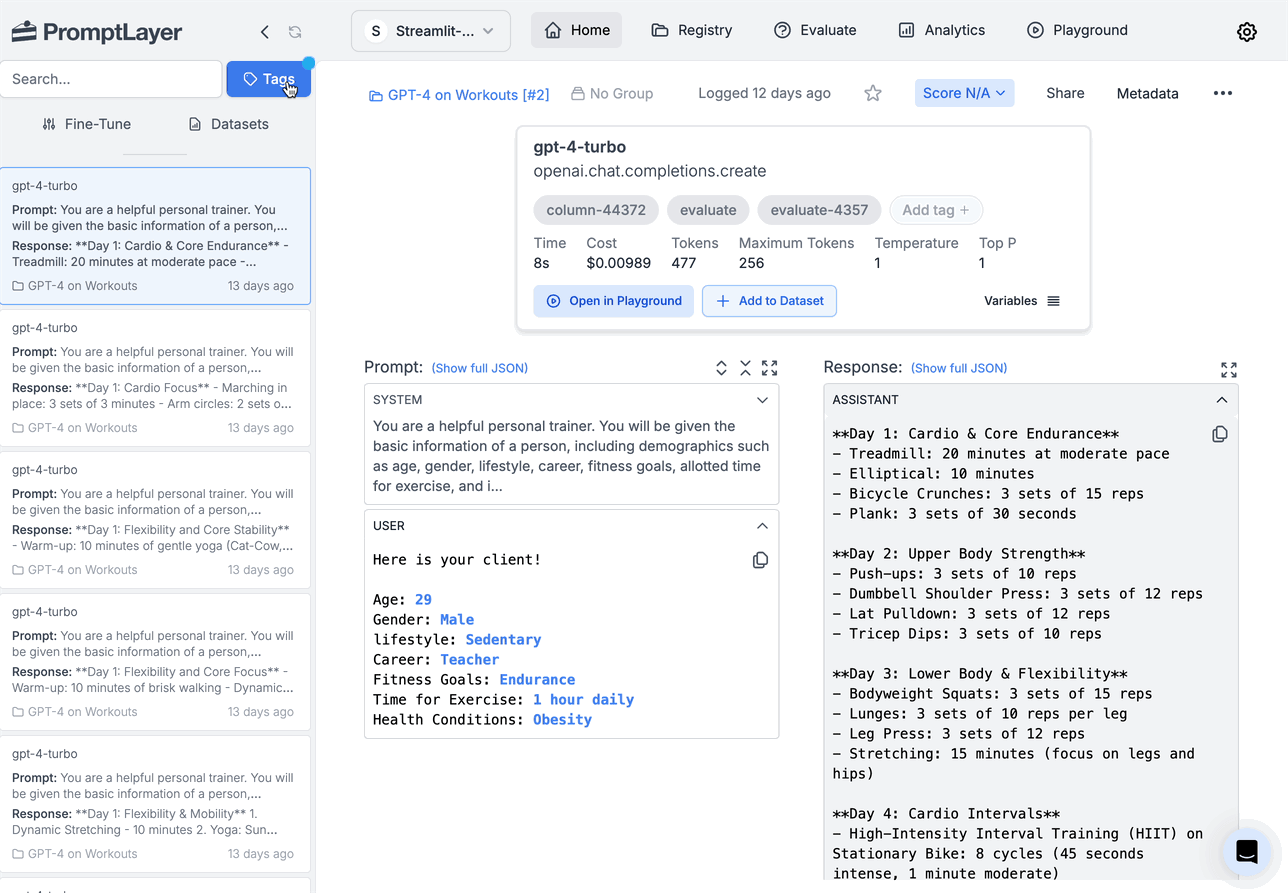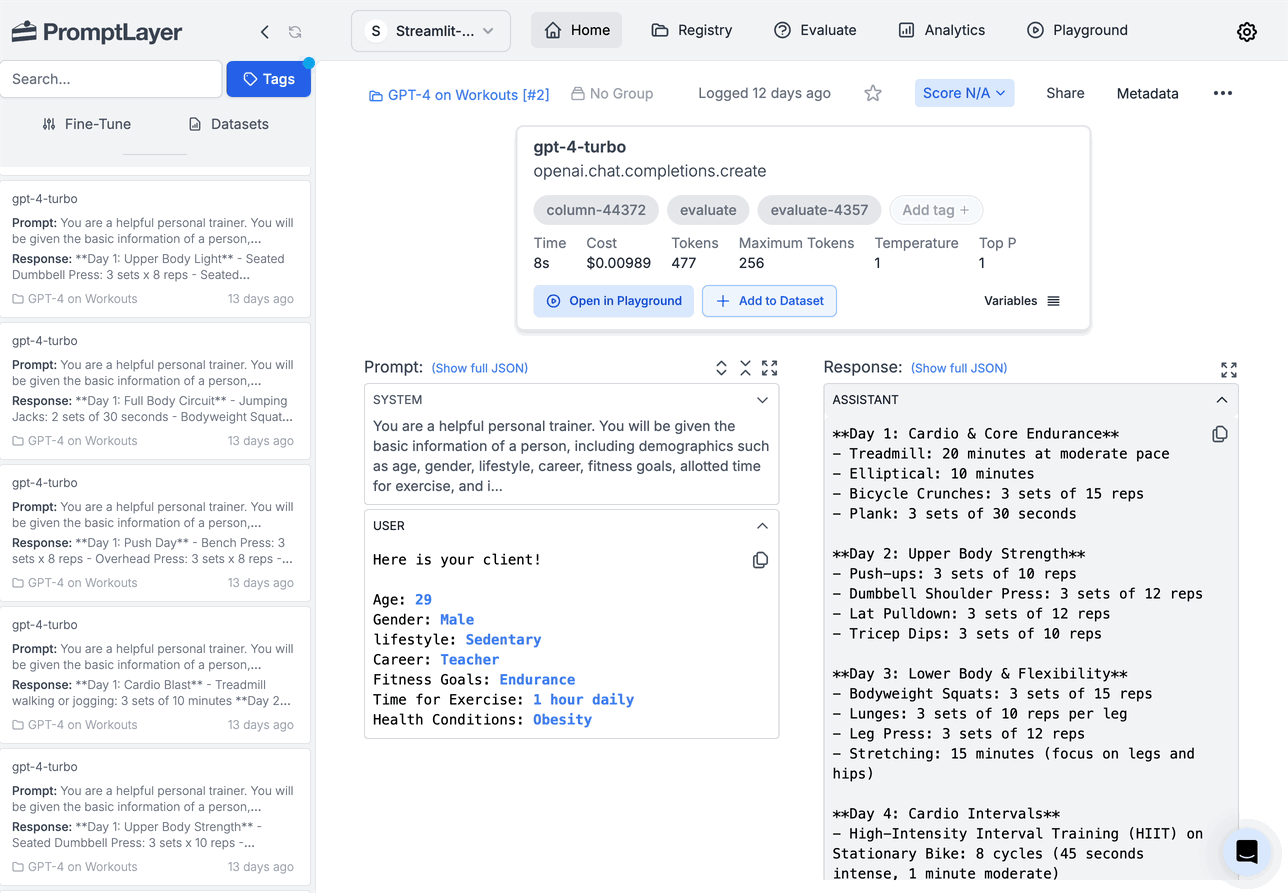
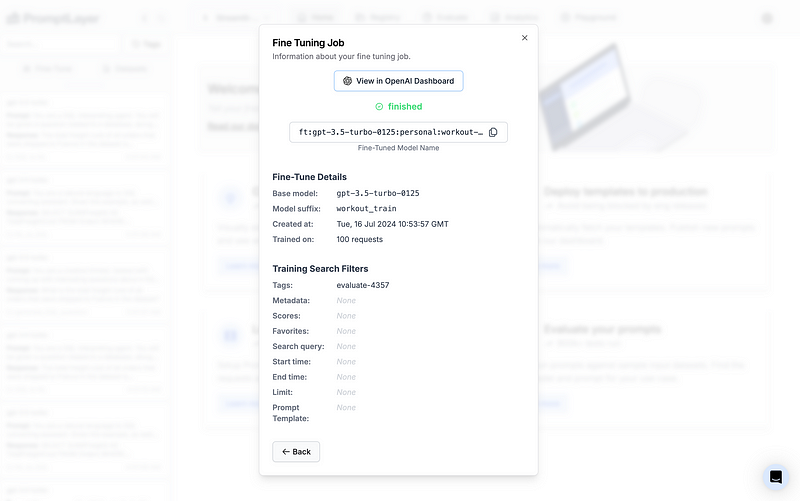
Now that we have our fine-tuned model, it’s ready for use! We can test it directly within PromptLayer using a simple process. First, copy the Fine-Tuned Model name from the screenshot above. Then, open the PromptLayer playground and paste the model name in the “model” field. This allows us to immediately start experimenting with our newly trained model. Here’s an example:
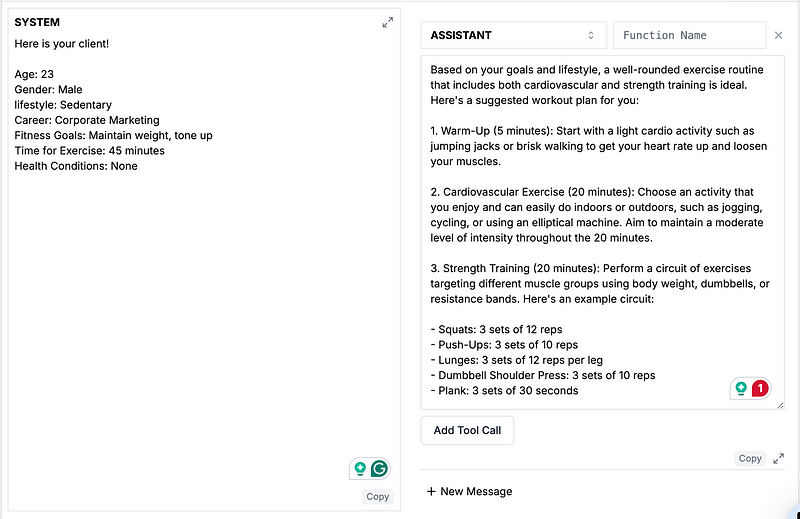
And voila, we’re done fine-tuning in a fraction of the time, with a fraction of the mess. It was significantly faster to train with PromptLayer. Also, having it work on your previous calls means that we don’t have to worry too much about dealing with formatting and wasting time with new data collection. It would have been easy just to jump in after the Gemini calls to fine-tune for the first example.
Concluding Thoughts
Hopefully, you’ve enjoyed reading through the two fine-tuning examples. Fine-tuning can be a frustrating and long process. PromptLayer significantly simplifies the issue, but its probably still a good idea to stick to RAG for most use cases. If you’d like to read more about the trade-off between RAG and fine-tuning, see our article on the topic!
Otherwise, happy fine-tuning!
PromptLayer is a prompt management system that helps you iterate on prompts faster — further speeding up the development cycle! Use their prompt CMS to update a prompt, run evaluations, and deploy it to production in minutes. Check them out here. 🍰


