What Are Prompt Evaluations?

What makes one prompt more effective than another? And how can we quantify and document those differences? That's where prompt evaluations come in. Prompt evaluations are a way for you to assess and refine the inputs (prompts) you provide to an AI model, resulting in improved performance. Whether you’re a developer, prompt engineer, or just trying to get AI to do some of your work for you, understanding prompt evaluations is key to maximizing an AI’s potential.
Why Are Prompt Evaluations Important?
Prompt evaluations help identify and quantify the impact of even small revisions to your prompts, allowing you to fine-tune them to achieve the desired outcomes. Maybe you already have a "gut feeling" about which of your prompts works the best, but how do you know it works the best? Do the data really corroborate that? Have you tested across a large enough sample size? Have you stress tested? If potential investors in your AI product asked you for performance metrics, could you provide those?
Prompt evaluations are particularly important for:
- Improving accuracy: Ensuring responses are factually correct and relevant.
- Enhancing user experience: Aligning AI behavior with user expectations.
- Reducing hallucinations: Minimizing instances where the AI generates false or misleading information.
- Optimizing workflows: Streamlining tasks like content generation, data extraction, or customer support.
How Do Prompt Evaluations Work?
Step 1: Define Clear Goals
Before diving into evaluations, define what success looks like. What do you want your app or chatbot to be able to do, exactly? Should it be more creative or factual? More detailed or concise?
Step 2: Develop a Rubric
Create a framework for assessing prompt effectiveness. Your rubric might include criteria like:
- Relevance: Does the response directly address the prompt?
- Clarity: Is the response easy to understand?
- Consistency: Are similar prompts producing similar outputs?
- Accuracy: Are facts and data presented correctly?
Step 3: Test Prompts
Use a variety of test cases to evaluate how the model responds. Include:
- Edge cases: Uncommon scenarios or ambiguous phrasing.
- Average cases: Common, straightforward user inputs.
- Stress tests: High-complexity user inputs that push the model’s limits.
Step 4: Analyze Results
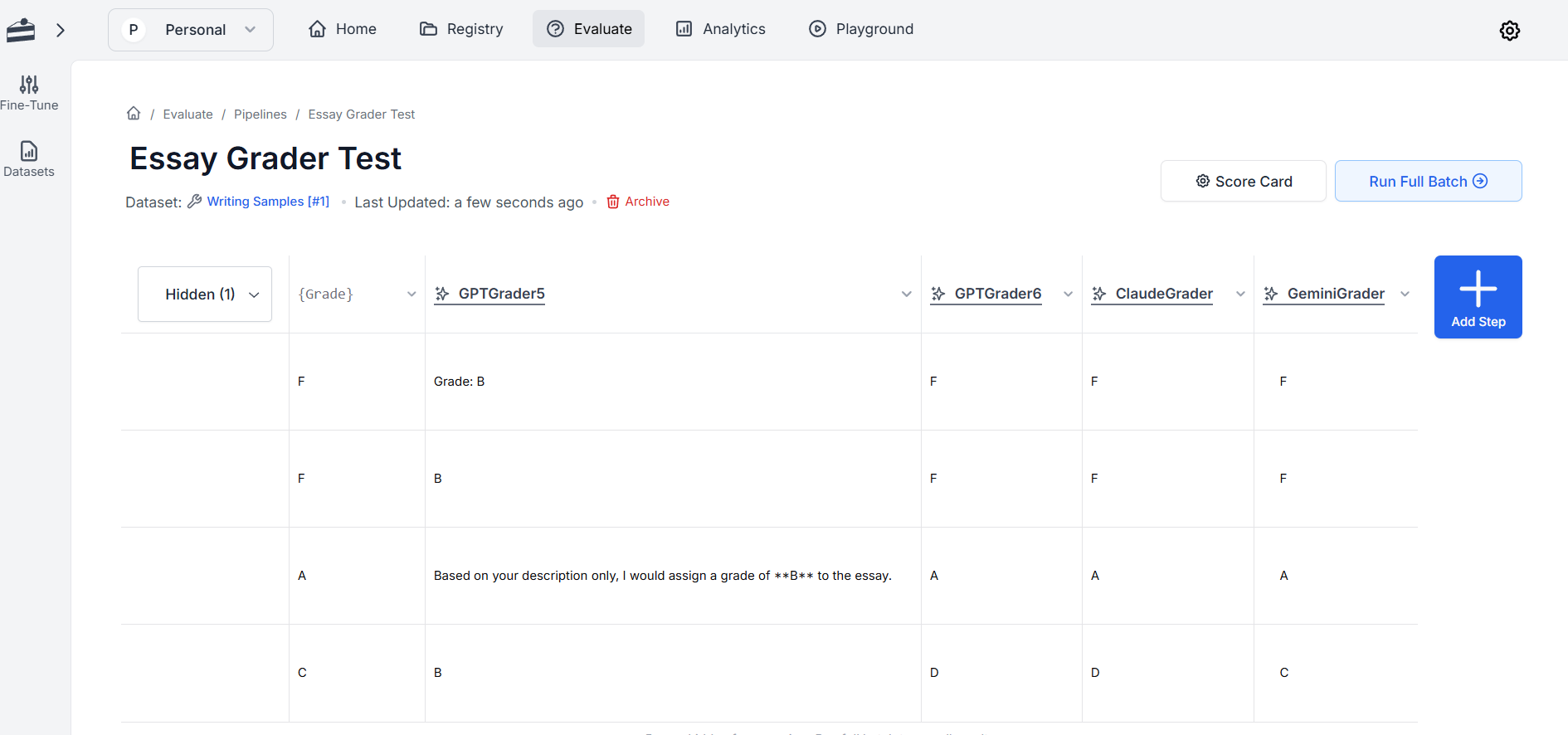
Collect data on the AI’s performance. Tools like PromptLayer, for example, allow you to version prompts and test them across different models, log outputs, and score your prompts with default or custom scoring logic. In the screenshot below, I've evaluated prompts for an "essay grader app." My criteria were simple: did the grader give the same grade to the writing sample that I did? I tested different versions of a prompt on the same AI model, as well as across different AI models. Looks like Gemini did the best job. That's useful for me to know if I want to deploy an essay grader app that people will actually trust and use!
Step 5: Iterate and Refine
Based on your analysis, revise your prompts. Rephrasing an instruction or providing more context or different constraints can make a significant difference. In my essay grader example, I went from "Grade this essay"–an obviously bad prompt– to one that contained a lot more context, clearly defined roles, and specific constraints.
Step 6: Repeat
Prompt evaluation is an ongoing process. As models evolve and your use cases expand, revisit and refine your prompts regularly.
Tools for Prompt Evaluations
Several tools can help streamline the evaluation process:
- PromptLayer: A platform for versioning and evaluating prompts.
- OpenAI Playground: Experiment with different prompts and settings.
- A/B Testing Frameworks: Compare the performance of two or more prompt versions.
Common Challenges in Prompt Evaluations
Prompt evaluations can be challenging. Here are a few common hurdles and how to overcome them:
- Ambiguity in goals: Clearly define what you want the AI to achieve with each prompt.
- Bias in evaluation: Use diverse test cases to ensure fairness and robustness.
- Time-intensive process: Leverage tools and automate where possible to save time, such as testing with public data sets if your own data is a little thin or isn't ready to use.
Final Thoughts
Prompt evaluations are an integral part of working with AI, ensuring that models perform reliably and meet your needs. Whether you're improving an AI chatbot, fine-tuning a content generator, or building a complex workflow, investing time in prompt evaluations will pay off in better outcomes and a more seamless user experience.
Need help writing better prompts? Check out PromptLayer's blogs for guidance and walkthroughs on different prompting techniques.


