Prompt Engineering Guide to Summarization

Summarizing information effectively is one of the most powerful ways we can use language models today. But creating a truly impactful summarization agent goes far beyond a simple "summarize this" command. In this guide, we’ll dive into advanced prompt engineering techniques that will turn summarization agents into robust tools capable of handling diverse and complex challenges.
We'll explore techniques like extractive versus abstractive summaries, breaking down large documents with chunking and accumulative summarization, refining summaries through multiple iterations, synthesizing information across multiple documents. We’ll also cover domain-specific fine-tuning and the integration of Q&A capabilities.
Get ready to transform your summarization projects into engaging, context-aware systems that don’t just summarize—they deliver meaningful value and insight.
1. Extractive vs. Abstractive Summarization: Crafting the Right Prompts
One of the key decisions in building a summarizing agent is choosing between extractive and abstractive summarization. Each has its own strengths and is better suited to different types of content and purposes.
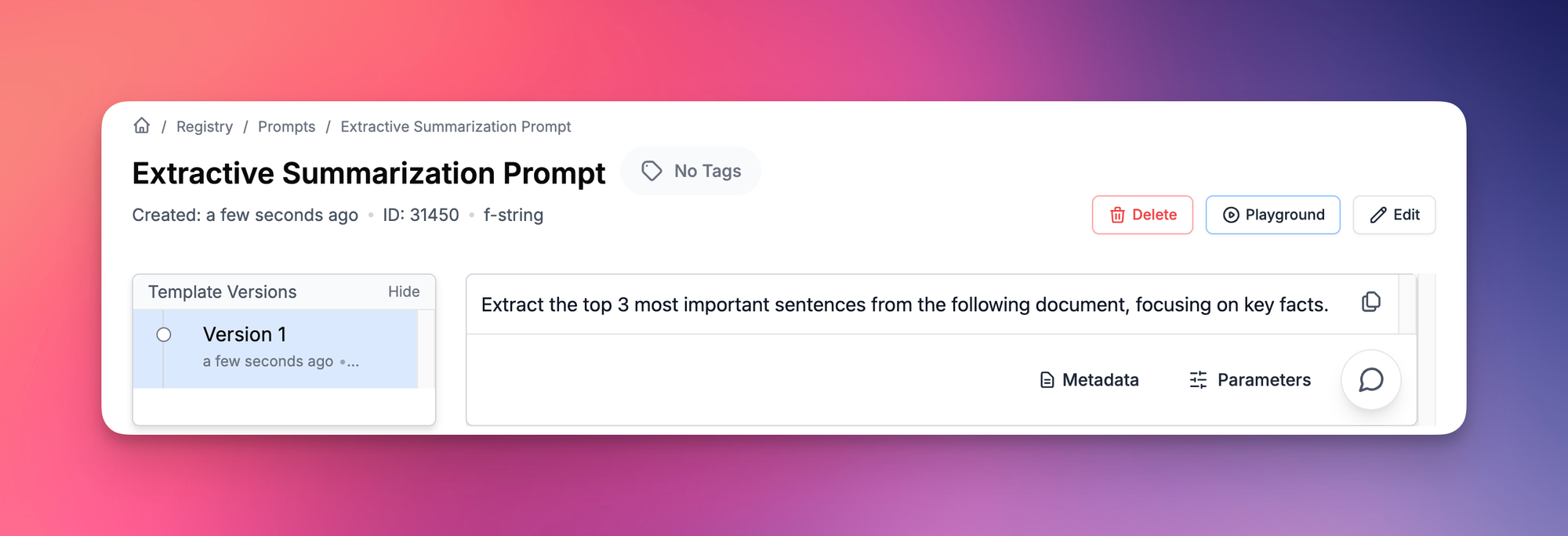
Extractive summarization selects sentences directly from the source text. This approach is ideal when you want to maintain the original wording, ensure factual accuracy, or need a quick, unaltered extraction of key points. It works best for legal documents, news articles, or reports where preserving the exact phrasing is important.
- Pros: Preserves original context and factual accuracy, less prone to introducing errors.
- Cons: Can be less concise, may result in disjointed summaries.
- Use Cases: News summarization, legal and technical documents, quick factual extractions.
Extractive Summarization Prompt:
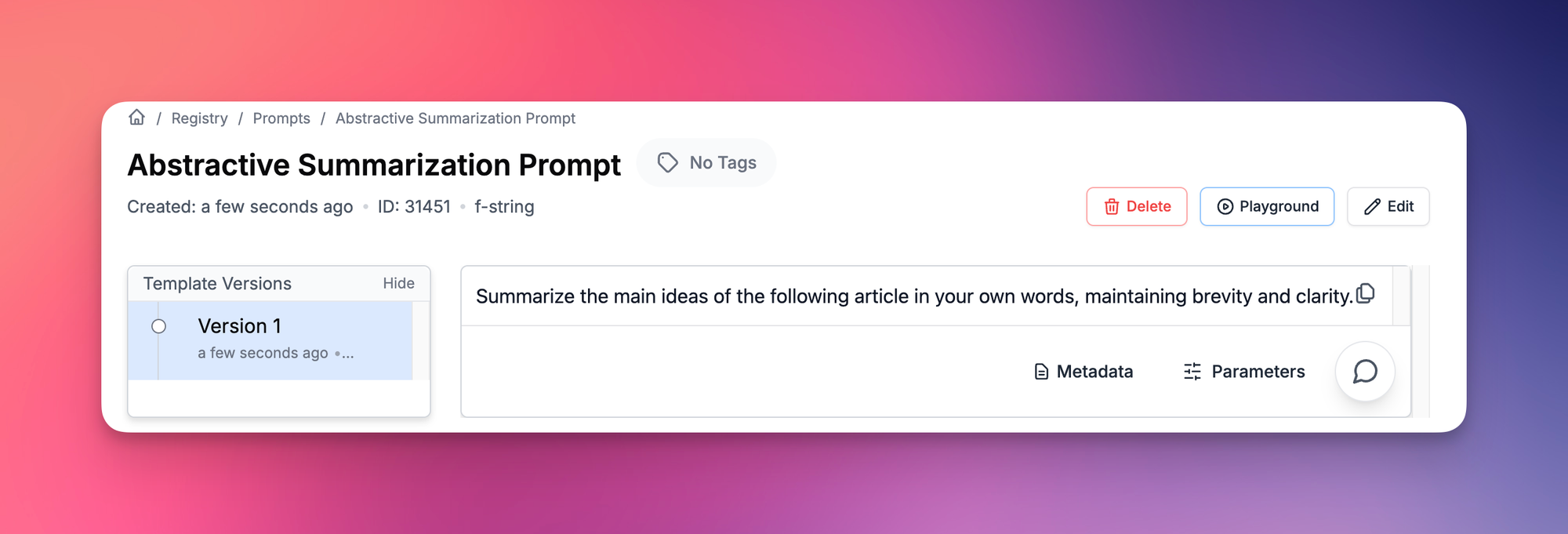
Abstractive summarization rewrites the content, capturing the essence in more creative or concise language. This type of summarization is useful when readability and conciseness are priorities, or when the summary needs to convey the information in a new way. It works well for blogs, opinion pieces, or educational content where tone and brevity enhance the reader's experience.
- Pros: More concise, can improve readability and coherence, allows for flexibility in tone and style.
- Cons: Higher risk of introducing inaccuracies, requires more time and resources.
- Use Cases: Summarising bigger chunks of text to extract meaningful excerpts where you don't necessarily require a word for word match.
Abstractive Summarization Prompt:
You can further refine abstractive summaries by specifying the desired style, tone, verbosity, and key aspects of how you want the agent to approach the content, ensuring the output is tailored to your specific requirements.
2. Handling Large Documents: Chunking and Accumulative Summarization
When dealing with large documents, directly inputting the entire text may exceed token limits or lead to less coherent summaries. To address this, we can break the document into manageable chunks, summarize each chunk, and then combine these summaries into a cohesive overall summary.
Approaches to Chunking the Data
There are multiple ways to chunk the data, each with its own advantages depending on the nature of the content and the desired outcome. Common methods include:
- Sentence-Based Chunking: Splitting the document by sentences, as demonstrated in this guide.
- Paragraph-Based Chunking: Breaking the document into paragraphs to maintain more context in each chunk.
- Fixed Token Limit: Creating chunks based on a fixed number of tokens, which ensures that each chunk fits comfortably within the model's token limit.
- Thematic Chunking: Dividing the document by topic or theme to group related information together.
For simplicity's sake, we move forward with a simpler sentence-based chunking approach as shown below.
Chunking the Document
import openai
openai.api_key = 'YOUR_API_KEY'
def chunk_text(text, max_tokens=500):
sentences = text.split('. ')
chunks = []
current_chunk = ""
for sentence in sentences:
if len(current_chunk) + len(sentence) <= max_tokens:
current_chunk += sentence + '. '
else:
chunks.append(current_chunk)
current_chunk = sentence + '. '
if current_chunk:
chunks.append(current_chunk)
return chunks
# Replace 'document_text' with your actual document text
document_text = "Your large document text goes here."
chunks = chunk_text(document_text)Summarizing Each Chunk
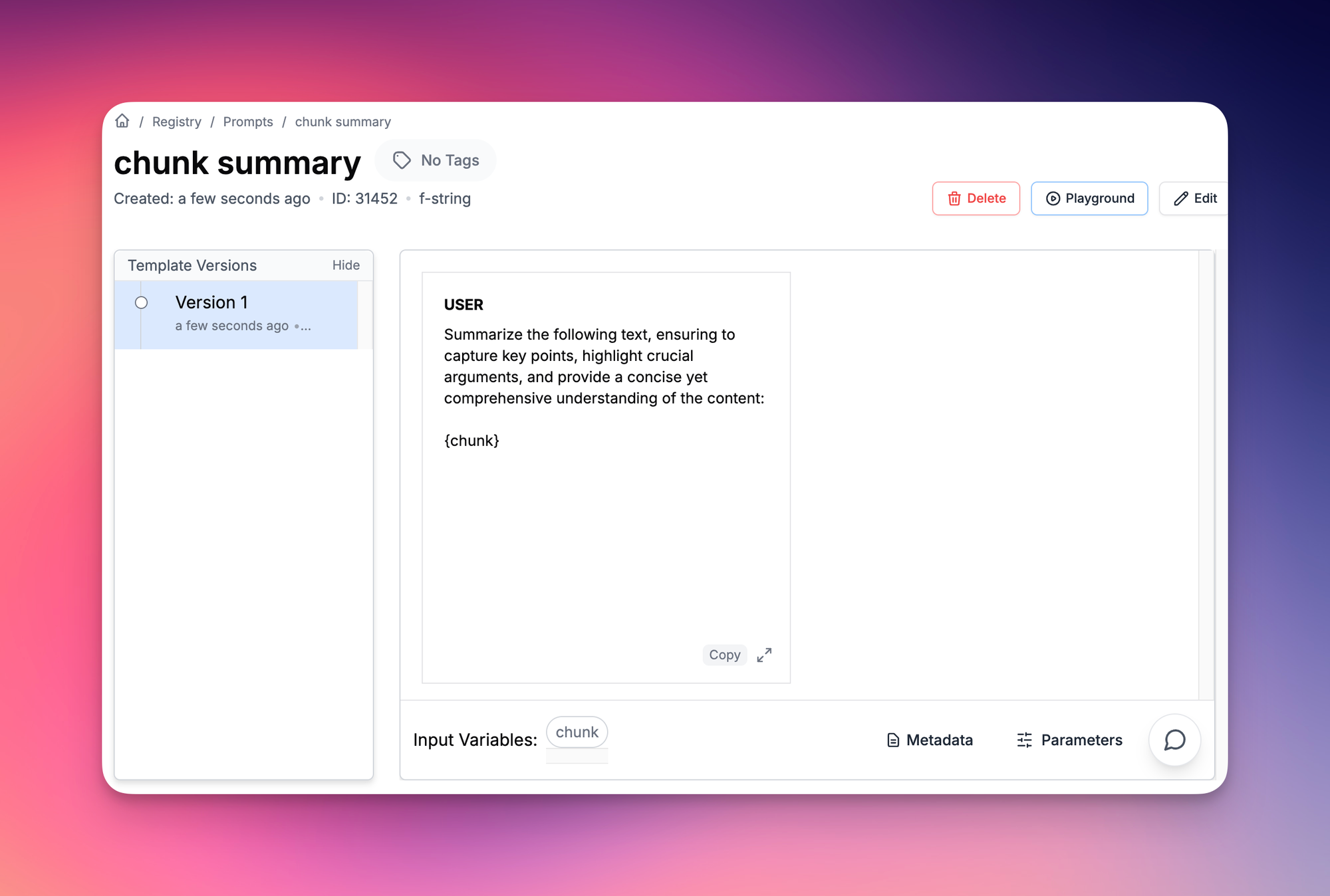
chunk_summaries = []
for i, chunk in enumerate(chunks):
response = pl_client.run(
"chunk summary",
input_variables = {"chunk":chunk}
)["raw_response"]
summary = response['choices'][0]['message']['content']
chunk_summaries.append(summary)Combining Chunk Summaries
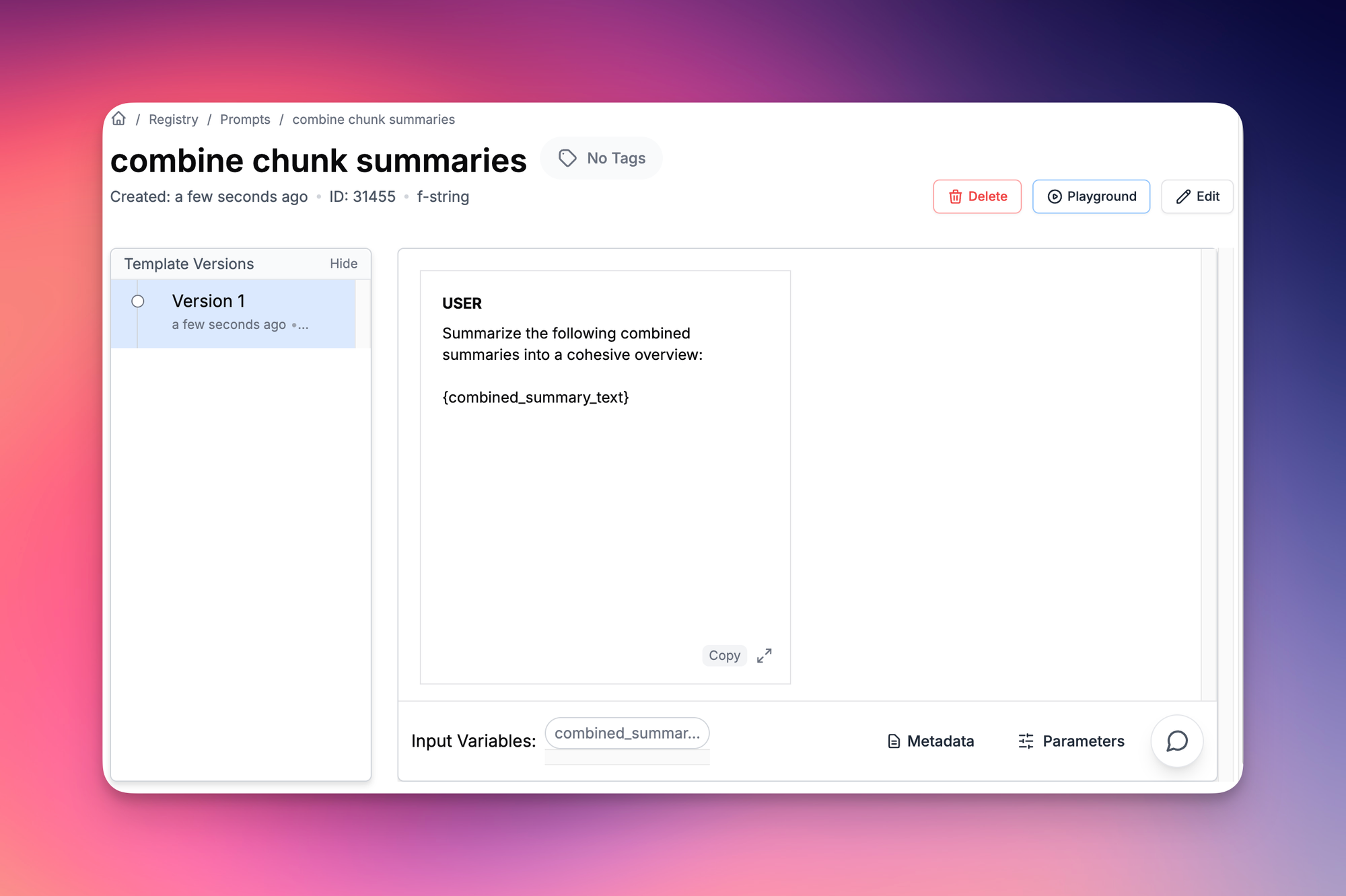
combined_summary_text = ' '.join(chunk_summaries)
final_response = pl_client.run(
"combine chunk summaries",
input_variables = {
"combined_summary_text":combined_summary_text"
)["raw_response"]
final_summary = final_response['choices'][0]['message']['content']
print("Final Summary:\n", final_summary)By using this approach, you can effectively handle large documents without losing important information. This method is similar to techniques used by libraries like LangChain, which manage long texts by breaking them into chunks and processing them sequentially.
3. Iterative Summarization: Improving Quality Through Multi-Turn Prompts
Iterative summarization refines the output over several rounds, leading to a more accurate or nuanced summary. This technique complements chunking by allowing refinement at each stage.
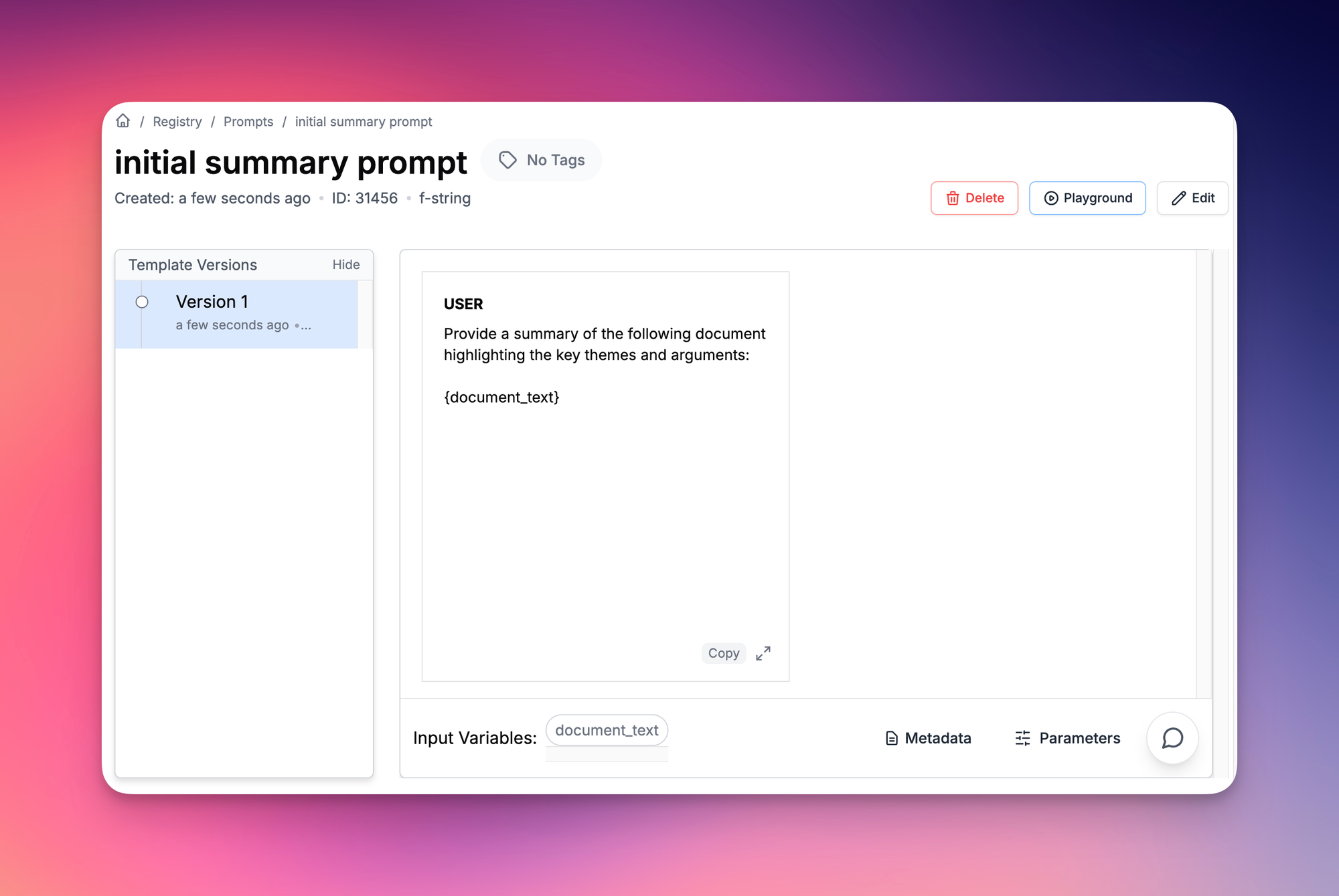
- Initial Summary Prompt: "Provide a summary of the following document highlighting the key themes and arguments."
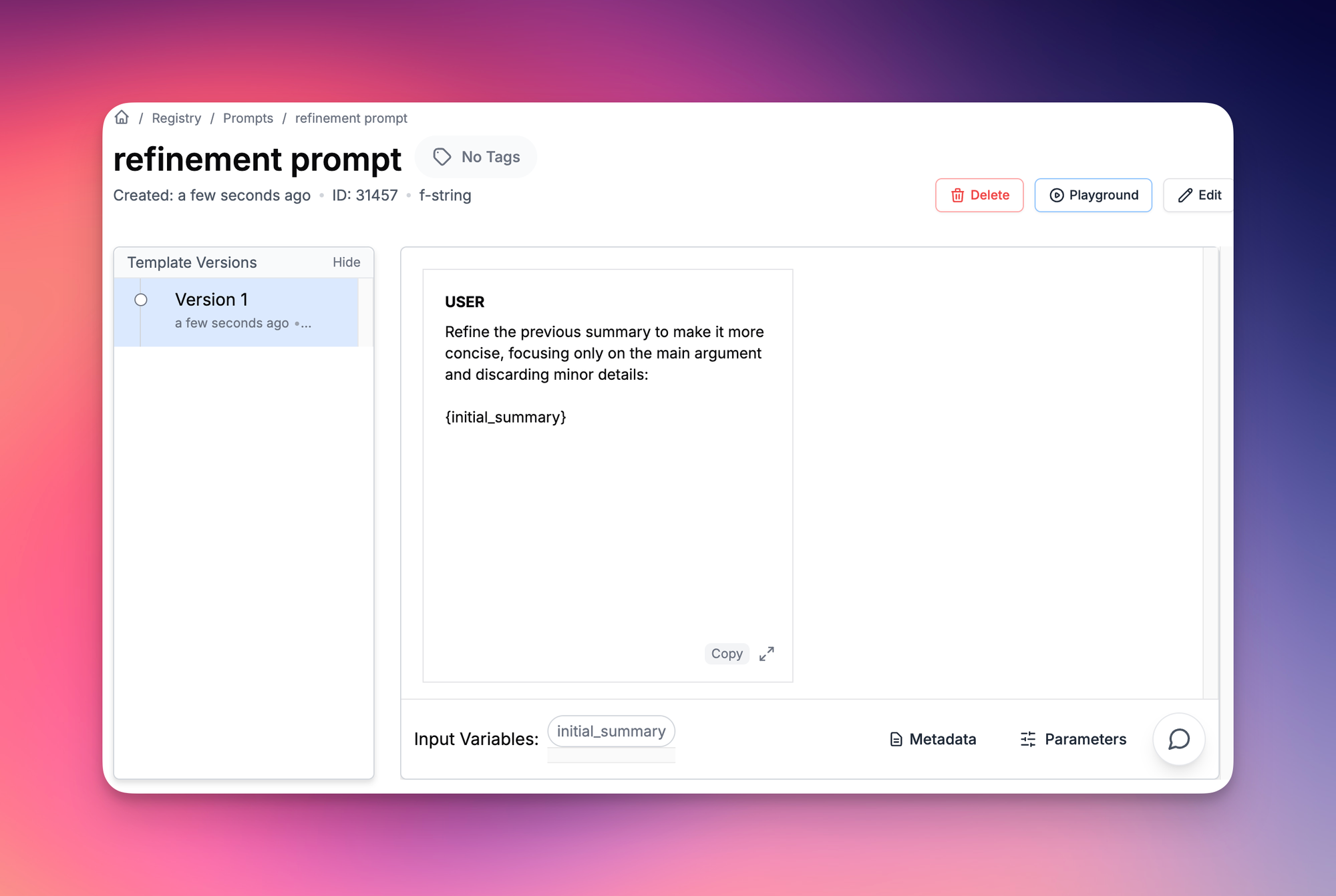
- Refinement Prompt: "Refine the previous summary to make it more concise, focusing only on the main argument and discarding minor details."
Example Implementation Using Python
# Initial summarization
response = pl_client.run(
"initial summary prompt",
input_variables = {"document_text":document_text}
)["raw_response"]
initial_summary = response['choices'][0]['message']['content']
# Refinement
refinement_response = pl_client.run(
"refinement prompt",
input_variables = {"initial_summary":intial_summary}
)["raw_response"]
refined_summary = refinement_response['choices'][0]['message']['content']
print("Refined Summary:\n", refined_summary)This iterative process can be repeated as needed to achieve the desired level of conciseness and clarity.
4. The Role of Prompts in Domain-Specific Summarization and Fine-Tuning
Incorporate the unique language and context of a particular field to maintain technical rigor. Fine-tuning the model on domain-specific data can significantly enhance performance.
- Example Domain-Specific Summarization Prompt: "Summarize the key findings from this medical research paper, maintaining relevant terminology and focusing on implications for clinical practice."
Fine-Tuning for Domain Expertise Fine-tuning involves training the language model on specialized datasets to improve its understanding of domain-specific terminology and concepts.
Steps for Fine-Tuning:
- Collect Domain-Specific Data: Gather a dataset of texts from your target domain.
- Prepare the Dataset: Format the data appropriately, ensuring it maintains the context and structure needed for effective fine-tuning.
- Train and Optimize: Use the dataset to fine-tune the model, focusing on the specific needs of your domain for enhanced performance.
An agent with domain knowledge is better able to reflect on the data, providing more accurate, relevant, and contextually appropriate insights.
Conclusion
Building a powerful summarizing agent requires more than simply using a language model out of the box. Through advanced prompt engineering, you can create summarization agents capable of handling a wide variety of complex scenarios—from balancing factual and analytical summaries to handling large documents through chunking and accumulative summarization, multi-document analysis and domain-specific content with fine-tuning.
Whether you're developing summarization tools for chatbots, enhancing user productivity, or generating real-time insights, understanding and leveraging these advanced techniques is essential for maximizing the capabilities of language models. With careful prompt design and potential fine-tuning, you can push the boundaries of what summarization agents can do, making them indispensable tools in a content-heavy world.


