Production Traffic Is the Key to Prompt Engineering

Let's be honest—you can tinker with prompts in a sandbox all day, but prompt quality plateaus quickly when you're working in isolation. The uncomfortable truth is that only real users surface the edge cases that actually matter. And here's the kicker: the LLM landscape evolves weekly. New model versions drop, agent patterns shift, function-calling behaviors change. Those offline tests you ran last month? They're already aging.
This post gives you a concrete playbook to ship, measure, and harden prompts in production. Real user traffic isn't just helpful for prompt engineering—it's the only way to do it right.
Production Data: Your Only Reliable Feedback Loop
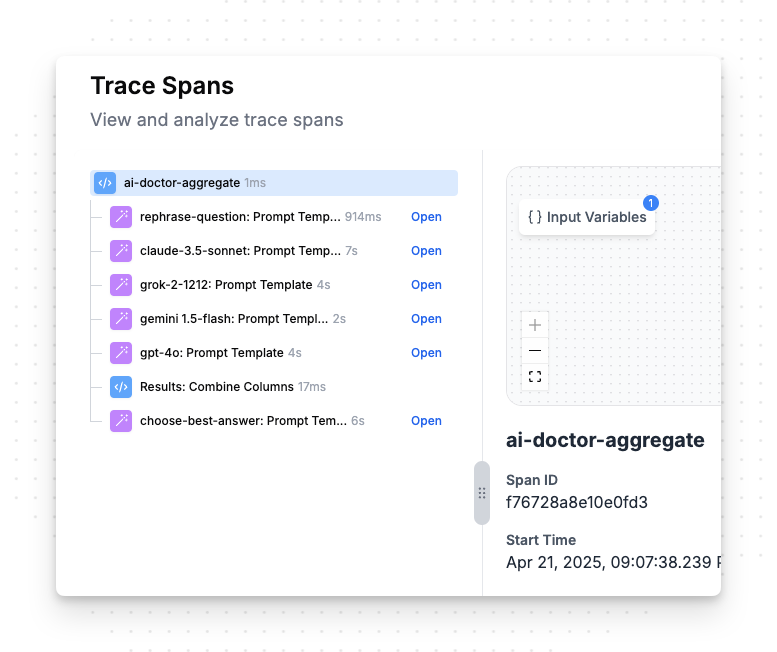
Prompt Like a Black Box—Just Tinker
Here's what I've learned: it doesn't pay to strategize too much about how you write prompts. The best way to prompt engineer is to treat it like a black box. Update one thing, see how it works. Try something else, see how it works. Just guess and check.
Why? Because LLM architectures are complex and getting more complex by the day. You've got dozens of models to choose from, and soon you'll be building agents and multi-prompt chains that make it exponentially harder to isolate variables. Trying to reason through all these interactions is a fool's errand.
What matters is simple: do your inputs match the outputs you want? That's it. That's also why the best prompt engineers are often non-technical. Success isn't about elegant prompt wording—it's about tight input-output alignment.
But here's the thing—to do this effectively, you need a good sample distribution to test on. You need real-world inputs. Sure, you could brainstorm five or ten test cases, but if you could run them on the past 10,000 user inputs? That's a whole different game. That gives you coverage, covers more bases, and lets you realistically see what's going to happen.
Production Traffic Beats Dev Traffic Every Time
Those 10,000 live queries I mentioned? They'll reveal edge cases that your 10 carefully curated test examples will never catch. Real users don't write queries the way you think they do. They use different language, different tone, different structure. They ask things you'd never imagine.
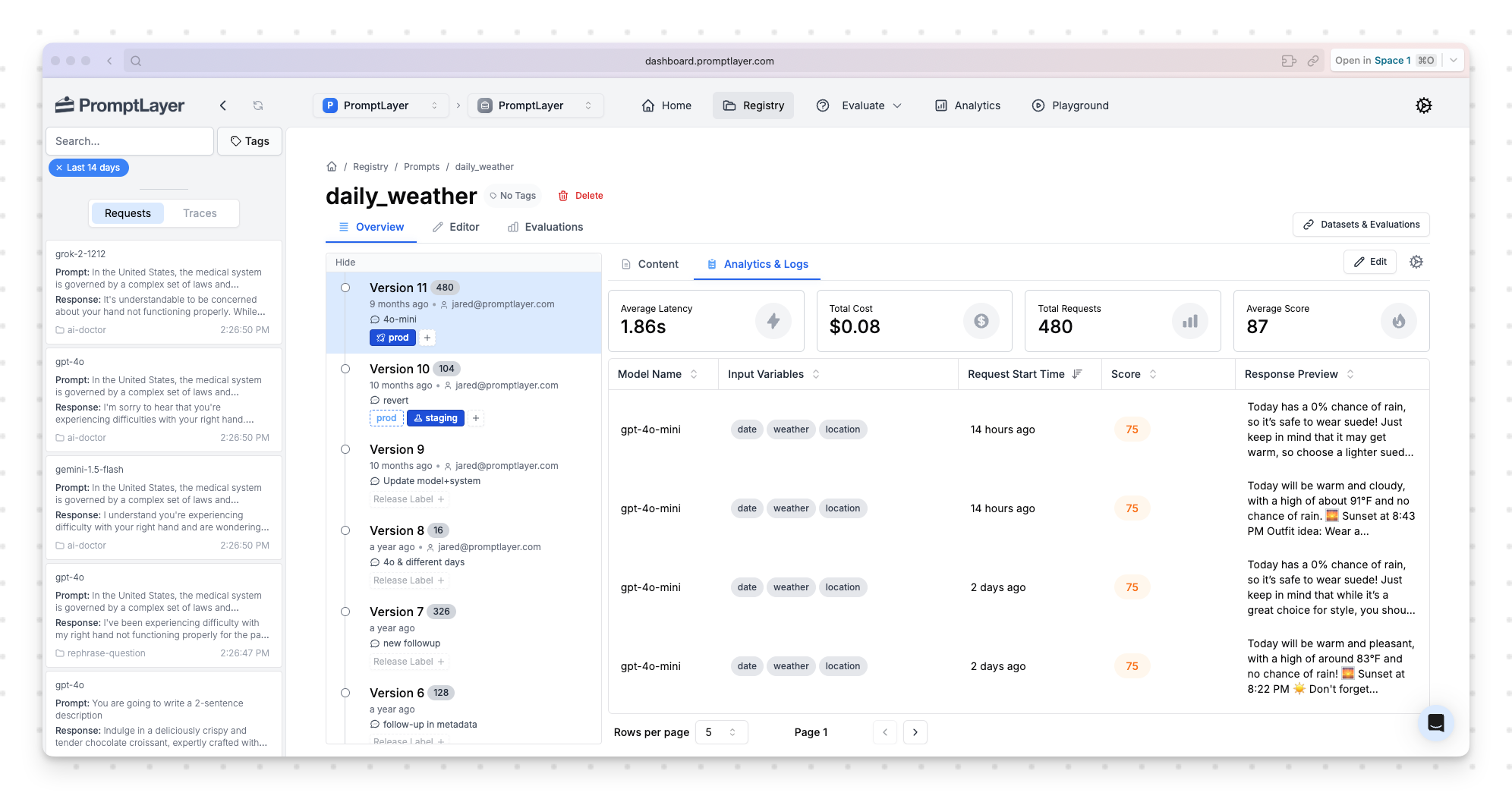
This isn't just about coverage—it's about speed. Production traffic helps you detect alignment gaps and regressions faster than any dev environment ever could. You're not guessing what users might do; you're seeing what they actually do.
Hidden Risks That Surface Only in Production
Let me break down two types of risks that will mess with your prompts if you're not watching.
Drift Is Real—Both Model and User Drift
Model drift is what happens when providers update their models. Many models—especially from OpenAI and Anthropic—offer "latest" versions instead of frozen versions. A frozen model is locked at a certain date and guaranteed not to change. The "latest" version? That's the latest and greatest, which means it could change any day.
If you've been keeping up, you've seen the controversies—like gpt-4o becoming "nicer" to users, or other quality degradations over time. Sometimes model providers optimize for one thing at the expense of another. Maybe they want to reduce hallucinations, but that comes at the cost of function quality. These changes happen silently, and if you're not monitoring production, you won't know until users complain.
User drift is equally sneaky. Say you release your app and it goes viral in a new country. If it's a grocery app, maybe this new country shops for different groceries and asks different types of questions. Your prompts aren't prepared for that.
The beauty of LLMs is that your generic prompts can handle infinite inputs. But the hard part about LLMs is that your generic prompts must handle infinite inputs.
These two types of drift make it critical to measure production data continuously. You need online evals, tests on production data, and live measurement of your prompt outputs. Development environments will never provide full coverage, and even if something works perfectly the first week, it might break two months later when the model updates or your user base shifts.
Environment Parity: The Devil's in the Details
Here's something that trips up teams constantly: your dev and production environments need to be identical.
There are so many intricacies in how a prompt gets compiled—whether you're using Jinja2 templates, structured outputs, function calling, or agents running in parallel or sequentially. Every detail matters. With LLMs, one small word can change the entire output. One misplaced variable, one different parameter, one version mismatch—any of these can torpedo your results.
You need to version and snapshot every prompt-related artifact. Your staging environment needs perfect fidelity to production. This isn't optional; it's table stakes for reliable prompt engineering.
Safeguards for Shipping with Confidence
Monitoring Traffic and A/B Testing
There's one ground truth and only one ground truth: are users getting good outputs from the LLM? Everything else is proxy metrics.
A/B testing is your best tool here. When you're plugged into a prompt management platform like PromptLayer, you can pull down different prompt versions at runtime, segment by users, and measure what actually works. This isn't about guessing—it's about letting your users tell you which prompts deliver value. Learn more.
Live monitoring and online evals measure quality where it counts: in user-facing responses. You can segment traffic, route variants automatically, and track win rates. When metrics dip, you get alerts. When something breaks, you roll back instantly.
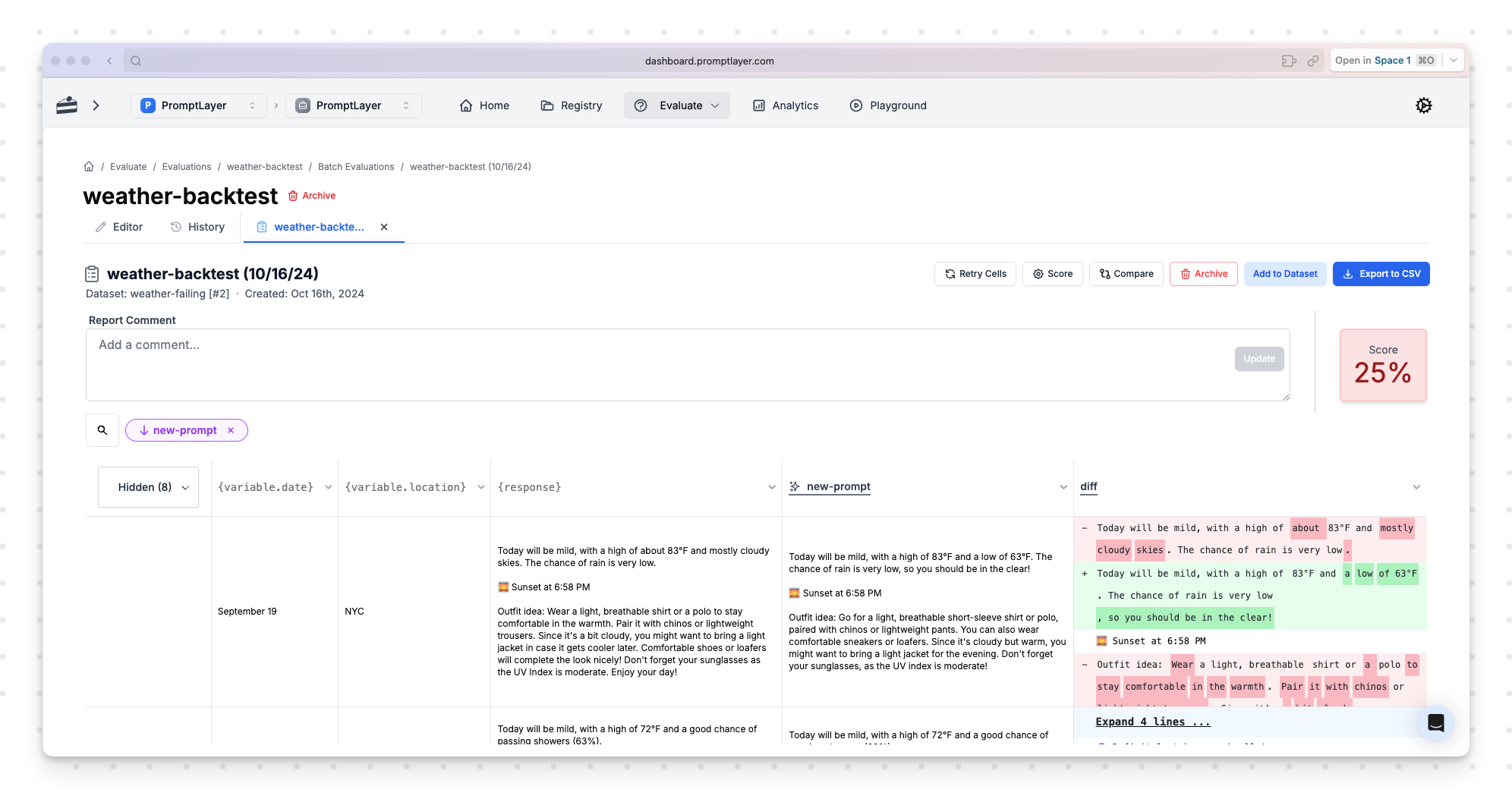
Regression Testing and Backtesting on Real Logs
Building regression sets from real data is crucial. Say you want to catch cases where the model responds in the wrong language—maybe it follows the user's language when it should always respond in English. To build these hard evals, you need access to production data.
Without this capability, you're flying blind. You need to capture past failures and lock them into automated tests. Run nightly or CI backtests across thousands of real interactions. Block any deployment that reintroduces known issues. This is how you build reliability into your LLM applications.
Conclusion: Prototype Offline, Validate Relentlessly Online
You can use tools like PromptLayer, other prompt workbenches, or OpenAI's Playground to get a rough estimate of how good your prompt is. There, you can iterate with five, ten, even a hundred examples. That's fine for getting started.
But when you want to build a reliable application that works for millions of users? You have to test on thousands or tens of thousands of real-life examples. You never really know what users will input.
The bottom line: use your sandbox for ideation, but production is where you find truth. A production-first approach hardens your prompts against drift and edge cases that you'll never anticipate sitting at your desk. Prompt management platforms streamline this whole process—monitoring, A/B testing, regression suites—for teams that actually care about reliability.
Production traffic isn't just important for prompt engineering. It's the only way to do it right.
Ready to test your prompts against production data?
PromptLayer is an end-to-end prompt engineering workbench for versioning, logging, and evals. Engineers and subject-matter-experts team up on the platform to build and scale production ready AI agents.
Made in NYC 🗽 Sign up for free at www.promptlayer.com 🍰


