Migrating prompts to open-source models
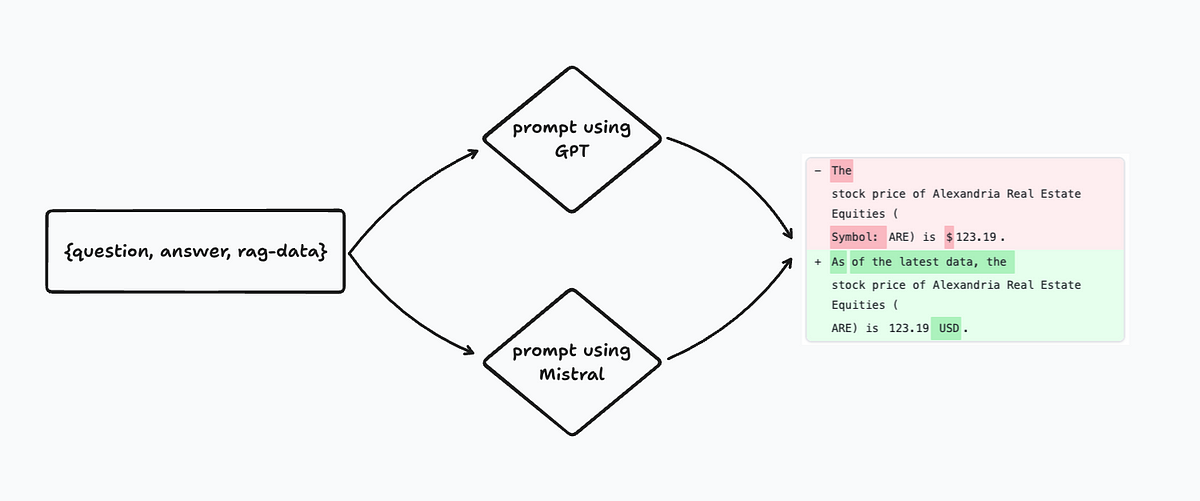
Comparing prompt outputs using different models
In honor of adding Mistral support to PromptLayer this week, the following tutorial will discuss best practices of migrating prompts to open-source models.
Open-source language models are serious competitors, often beating out gpt-3.5-turbo in benchmarks. They offer serious advantages like cost and privacy. If you are running a huge numbers of inferences, you will save a lot to host your own small open-source models. Alternatively, if you are dealing with sensitive data that you don’t want to send to OpenAI, open-source models are the way to go ➡️
Today, Mistral is one of the most popular open-source language model families. For this tutorial, we will investigate and migrate a prompt toopen-mixtral-8x7b. Although the popular models of the day might change, the methods covered here are timeless ✨
Our Prompt
The prompt we will be working with in this tutorial is called llm-investor.
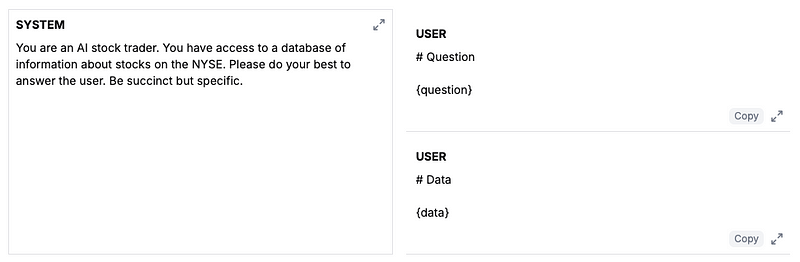
Our LLM investor is designed to take in a user question, retrieve data from a RAG pipeline, and then respond with the answer. We already have set up an eval for this prompt using a hand-curated dataset of sample questions and ground-truth answers. This prompt works well already, but let’s see if it will perform better with Mistral.
You can find a tutorial on building evals for RAG prompts here.
Batch Model Comparisons
Let’s start by investigating how changing the model will effect the output completions of the prompt. For some models it might even be beneficial to rewrite the prompt, but for now we will hold that constant.
The simplest way to compare model outputs is with a string equality diff. Then we can eyeball 👀 the outputs and see how different they are.
Alternatively, you might want to try vector comparisons or using an API endpoint to run a deterministic evaluator (e.g., running actual code that was generated).
To do this, we will use PromptLayer’s batch evaluation builder (learn more). We can use the same dataset used for our prompt evaluation run as described above.
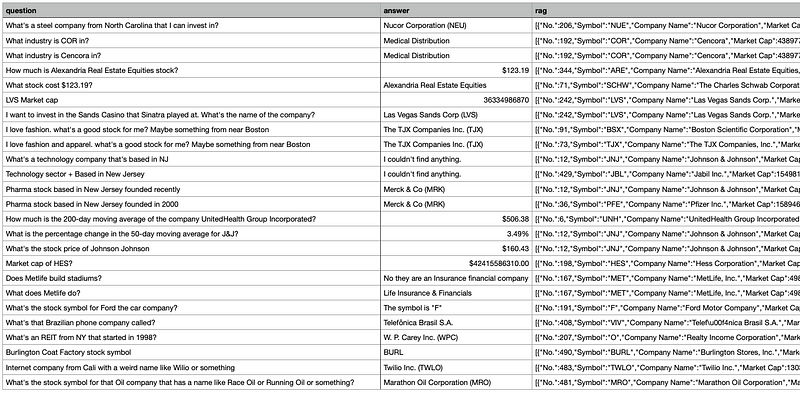
Navigating to the “Evaluate” tab on PromptLayer, we will create a new pipeline. For each row in the dataset above, this pipeline will run our prompt template once on Mistral and once on GPT. The last pipeline step will diff the outputs.
After creating a pipeline using our dataset, add the following columns as described above:
- Prompt Template (GPT)
- Prompt Template (Mistral)
- Equality Comparison (using the outputs from #1 and #2)
Alright, that was easy! Kick off a run. Don’t forget to compare the latency & cost of these results.
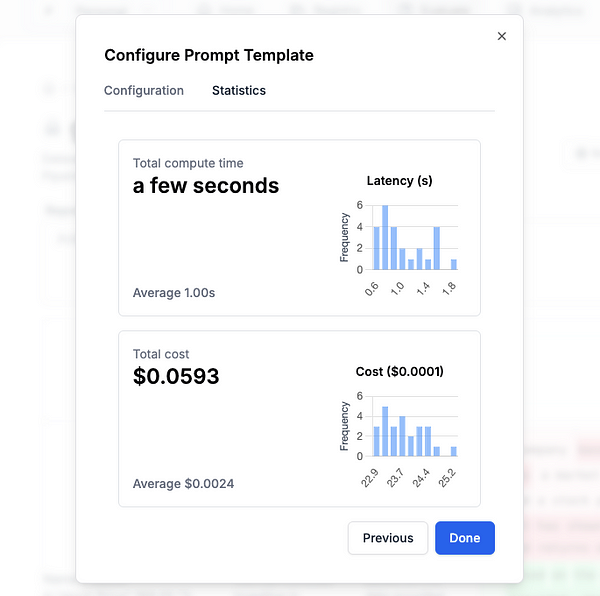
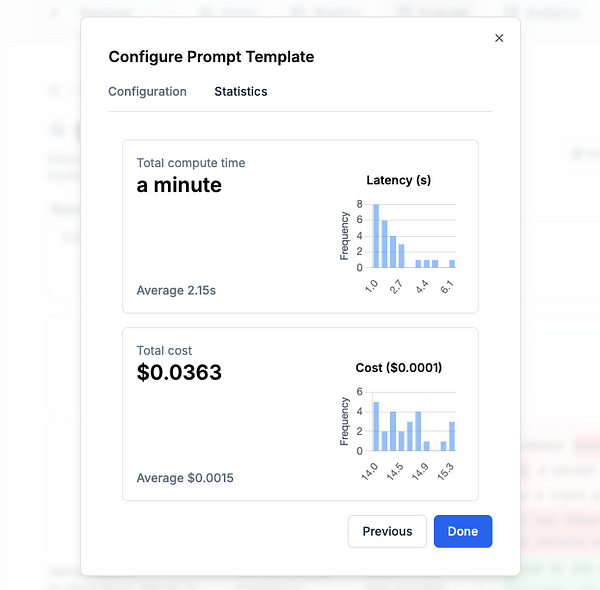
Our GPT vs Mistral statistics
Migrating the Prompt Template
Now that we have done some investigation, let’s update our prompt template! This is simple with PromptLayer, just click “Parameters” and change the model to Mistral.
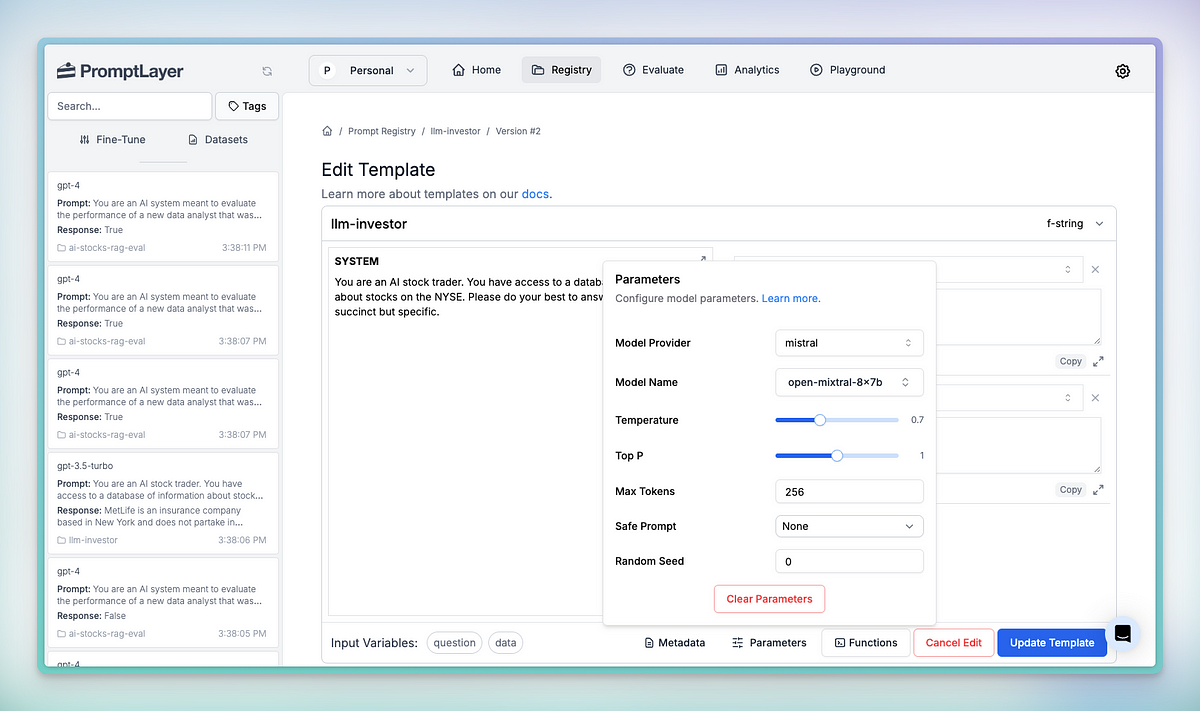
If you have already set up the eval (as we did), saving this prompt template will kick off a new eval run. Think of it like Github actions. We can now see the final score… and…. looks like it improved our accuracy!!
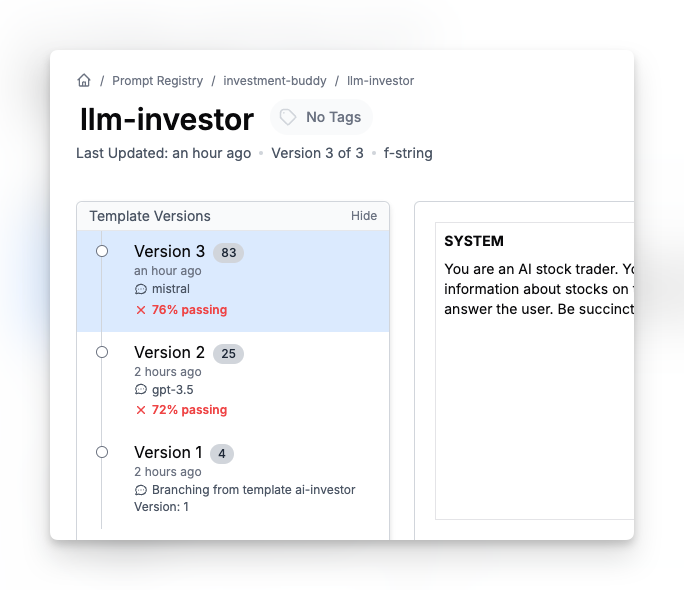
You can always change it back or use release labels to A/B test. Learn more about prompt organization here.
The video below shows this all in action:
Prompt Iteration
There we have it! An easy way to try out new models & compare their outputs.
Prompt engineering is all about quick iteration. We believe the way to write the best prompts is all about setting up a development environment for quick iteration. That’s why we were able to test out Mistral so easily.
Check out our blog post on prompt iteration to learn more 🍰
PromptLayer is the most popular platform for prompt engineering, management, and evaluation. Teams use PromptLayer to build AI applications with domain knowledge.
Made in NYC 🗽 Sign up for free at www.promptlayer.com 🍰


