Lawyers in the Loop: How Midpage Uses PromptLayer to Evaluate and Fine-Tune Legal AI Models
For two years, Midpage has used PromptLayer to transform how they build legal AI, putting lawyers next to engineers to own prompt quality. Their approach has scaled from manual tracking in Notion to automated evaluation pipelines that catch regressions before they reach users.
- 80 production prompts across 10 AI features
- 1,000+ iterations logged and tracked
- 5-15 hours/week of lawyer iteration time vs. <2 hours/week engineering oversight
- 40 hours/week platform usage by hundreds of litigators
Midpage: Prompt Engineering with Suits
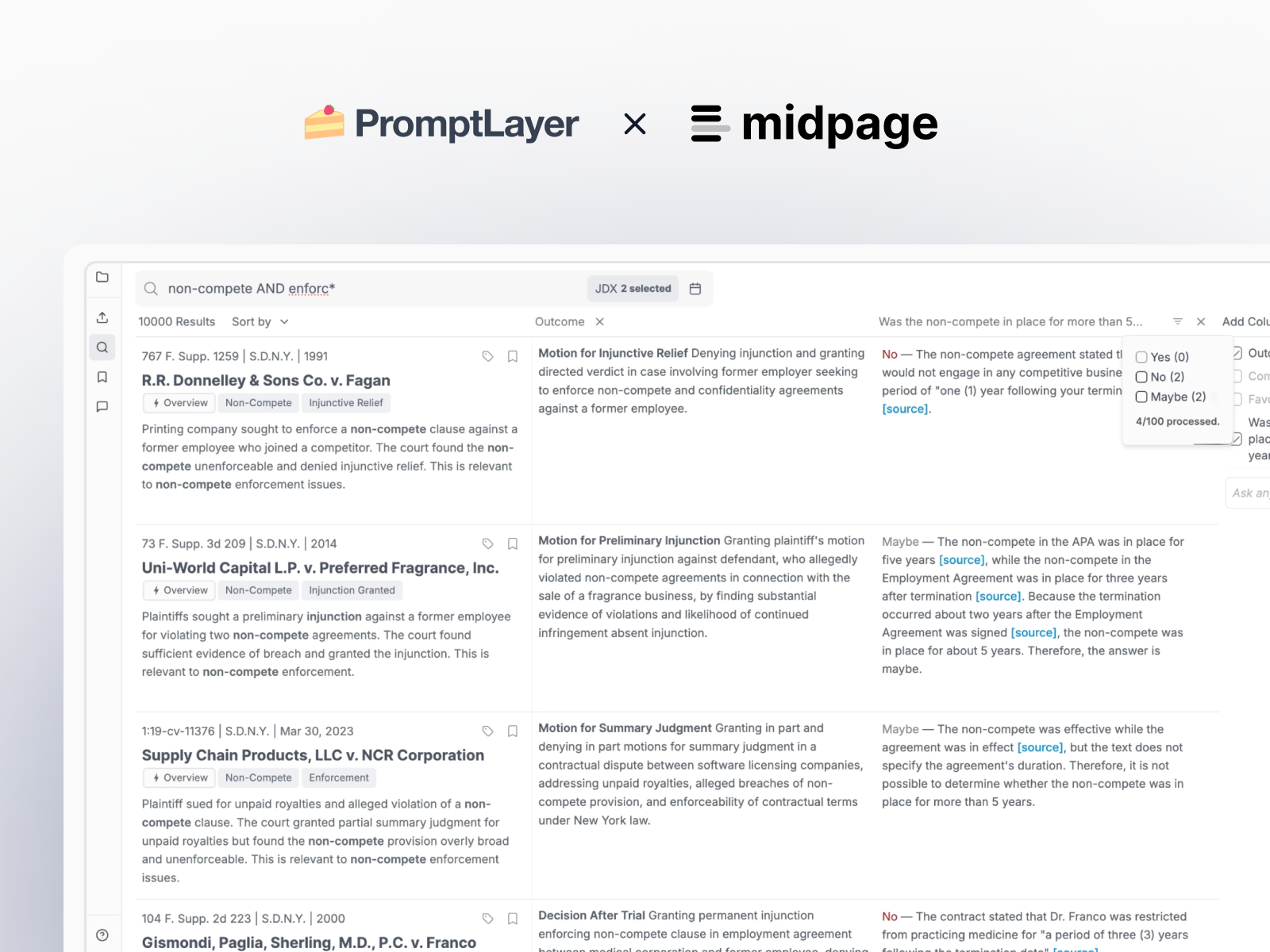
Midpage isn't just another legal chatbot. Their platform feels more like Google Scholar for case law—users can search, open cases, see how cases link to each other, and add annotations. Throughout the product, they've deployed around 10 different AI features in production and 80 prompts, each carefully tuned for its specific use case.
From summarizing search results to classifying cases, each feature demands different trade-offs between latency and accuracy. This complexity led them to use different models for almost every feature. Some tasks require the speed of 4o-mini for real-time responses, while others benefit from the enhanced intelligence of Gemini 2.5 Flash. Making these decisions requires constant experimentation—something that would be impossible without the right tooling.
Before PromptLayer: The Hidden Costs of Traditional Development
Two years ago, Midpage almost built their own prompt management system. The pain was real: engineers were spending hours implementing prompt tweaks instead of building features. There was no systematic way to test prompt changes before pushing to production. Domain experts—the lawyers who understood what made a good legal answer—were blocked by deployment cycles.
"There was just no way our engineers were going to change code every time we needed to try a new prompt," recalls Otto, Midpage's CEO. With a six-person team and ambitious product goals, they needed a better way.
The "Lawyers in the Loop" Workflow
Today, Midpage's workflow looks radically different. James Curbow, a former litigator who serves as head of product, is responsible for every single prompt in their system. The process is elegantly simple: engineers set up tracking with a prompt name once, then hand over control to James.
The handoff protocol is clear. Engineers wire up the prompt name and ensure tracking is configured. From there, James takes over—drafting prompts, creating datasets, running evaluations, and promoting changes to production. All without touching a single line of code.
“Our former litigator-turned-PM is responsible for every single prompt, and he never touches the codebase.”
- Otto von Zastrow (CEO of Midpage)
PromptLayer's prompt registry eliminated the deploy-for-every-prompt-change problem that was killing their velocity. With prompts separated from code, non-technical team members can safely edit and iterate while versions are automatically tracked. Domain experts now spend 5-15 hours per week on prompt engineering while engineers dedicate less than 2 hours weekly to oversight.
The Evaluation Pipeline: From ChatGPT to Production
Midpage's evaluation process showcases the power of putting domain experts in charge. The workflow begins with James brainstorming edge cases based on real legal research scenarios. He drafts prompts, logs them in PromptLayer, annotates results, and can promote winning versions to production with a single click.
“We use PromptLayer to track how each feature is doing—accuracy, regressions, everything.”
- Otto van Zastrow
For evaluation construction, lawyers compile edge-case questions that test the limits of their AI features. They use ChatGPT to normalize these questions to JSON format, then upload them to PromptLayer's evaluation system. The team employs an LLM-as-judge pattern: production models produce answers while GPT-4o grades the results, providing instant precision and recall metrics through PromptLayer's dashboard.
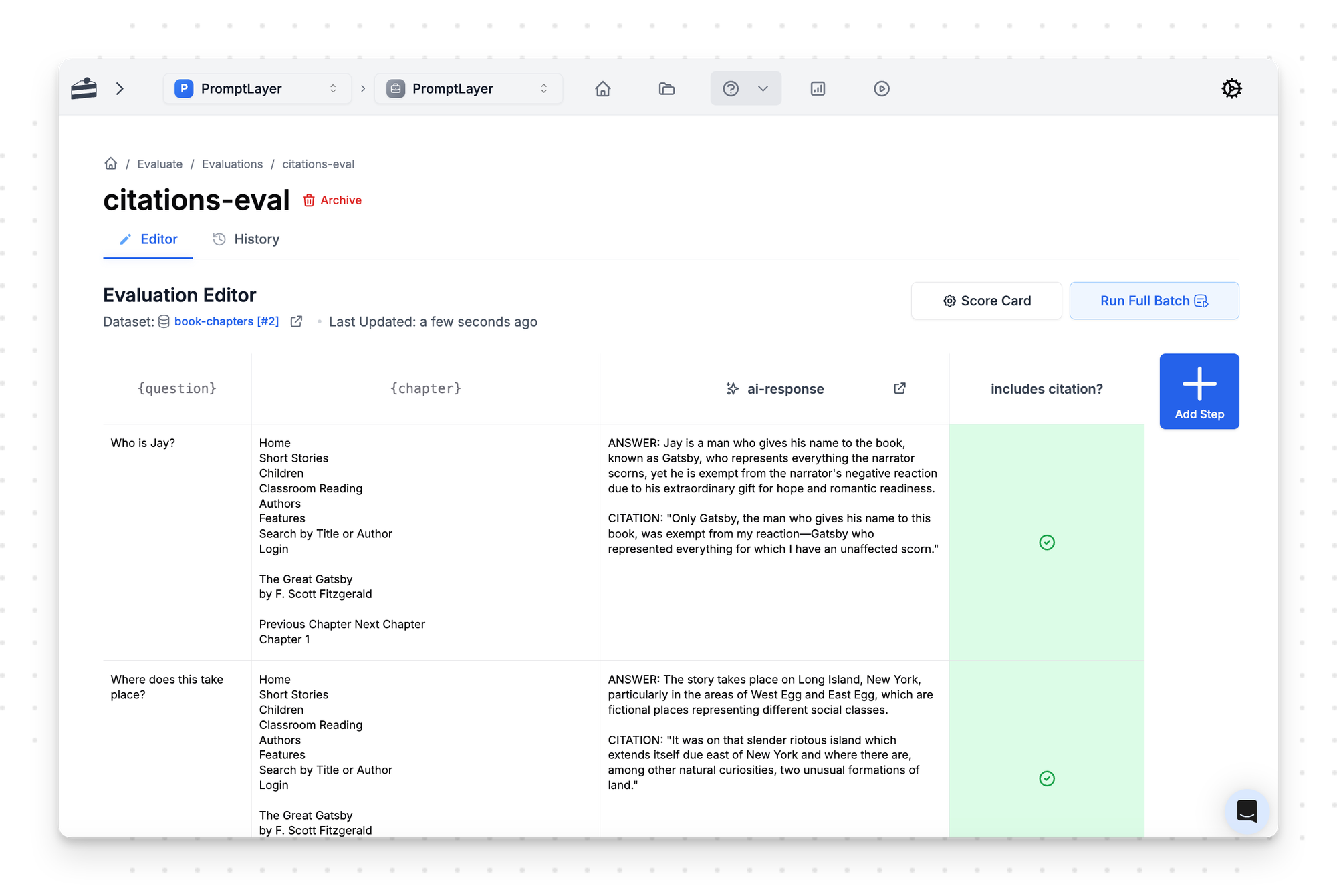
Perhaps most importantly, they've implemented regression gates that act as guardrails. These fail-fast runs execute on each prompt or model change, with diff views highlighting score deltas before deployment. Bad releases are blocked automatically, and the team reviews changes in stand-up meetings.
Fine-Tuning at Scale: When Prompts Aren't Enough
Midpage developed a clear intuition for fine-tuning candidates: when you have two pages of instructions with 50 edge cases, that's too complex for any base model.
Their search result explanation feature exemplified this challenge. Users needed to understand why each result matched their query, with relevant quotes highlighted. The team tested fine-tuning both 4o-mini and Gemini 2.5 Flash, weighing speed against intelligence.
Fine-tunes rely solely on synthetic text, not user data. Still, with just 50-100 training examples, they saw major improvements. Through PromptLayer's evaluation system, they rapidly iterated—the largest feature went through 10 iterations over three weeks, handling everything from output format changes to dataset improvements.
What Almost Was: Building vs. Buying
"We would have had to build it all ourselves," Otto reflects. The foundation model providers' tools weren't sufficient—they needed the full suite of capabilities that PromptLayer provides. Version management, evaluation pipelines, multi-model support, and collaborative workflows all needed to work together seamlessly.
There is a hidden complexity in building production AI features. It's not just about prompt management—it's about creating a system where domain experts can own quality while engineers focus on infrastructure.
Key Takeaways for Legal AI Teams
The Midpage story offers clear lessons for teams building AI products where domain expertise matters:
Empower domain experts with no-code tooling. Your best prompt engineers might not write code. Give them the tools to iterate independently while reserving engineering time for infrastructure challenges.
Treat prompts like code. Version control, testing, and rollback capabilities are just as important for prompts as they are for your application code.
Start evaluation early. Don't wait until you have problems. Build evaluation into your workflow from day one, especially for features where accuracy is critical.
For Midpage, PromptLayer transformed prompt engineering from a bottleneck into a competitive advantage. By putting lawyers in the loop and giving them the tools to own quality, they've built a legal AI platform that litigators trust.
PromptLayer is an end-to-end prompt engineering workbench for versioning, logging, and evals. Engineers and subject-matter-experts team up on the platform to build and scale production ready AI agents.
Made in NYC 🗽 Sign up for free at www.promptlayer.com 🍰


