How to use LLMs for Regression: A Guide to In-Context Learning

Traditional regression models like linear regression and random forest are tried and true. We know how they work and they're easy to audit. Not always so with large language models (LLMs) like Chat GPT, Claude, or Gemini, though that certainly hasn't stopped anyone from using them, even for regression tasks. So how can you use an LLM for regression, and is it worth it? Let's explore the use of in-context learning for regression tasks and consider when it might be time to augment, or even replace, Python libraries like scikit-learn or R functions like lm() and glm() with an LLM's native capabilities.
When given in-context exemplars of input-output pairs, the LLMs out-performed the unsupervised baselines every time, and, in some cases, even out-performed supervised models.
Can you use LLMs for regression?
Yes, actually. Vacareanu et al. published a paper last year demonstrating that, with just some in-context examples and no other training or fine-tuning, frontier models could equal or even out-perform traditional ML models such as linear regression and random forest. Vacareanu and his colleagues generated synthetic data for their test cases, opting for linear regression sets, non-linear regression sets, and sets for regression with non-numerical input. The synthetic data, they argue, decreases the likelihood that these data sets and their solutions are buried anywhere in the depths of the LLM's training data. They then trialed these sets using three types of models: 1) LLMs, both closed- and open-sourced 2) supervised models and 3) heuristic-based unsupervised models. Performance was measured by the Mean Absolute Error. Read the paper for more details on the exact methodology and visit their GitHub for their code and results. Suffice it here to say that what they found is encouraging: when given in-context exemplars of input-output pairs, the LLMs out-performed the unsupervised baselines every time, and, in some cases, even out-performed supervised models.
Whether you're predicting house prices for your next real estate investment, helping a small business predict customer churn, or analyzing advertising spend vs sales, Vacareanu et al. found that LLMs are up to the task. Let's walk through a brief, simple example of how to use their approach.
How to use LLMs for regression tasks:
- Collect clean input-output pairs as examples.
- Write a prompt using in-context learning to familiarize the model with your expectations. In-context learning, in this case, means providing the model with input-output pairs as part of your prompt. The following illustrative example is short for the sake of making the point, and your prompts should include significantly more input-output pairs. Vacareanu et al. found that the more exemplars you can give the model, the better, since models like Claude 3 and GPT-4 "obtain[ed] sub-linear regret":
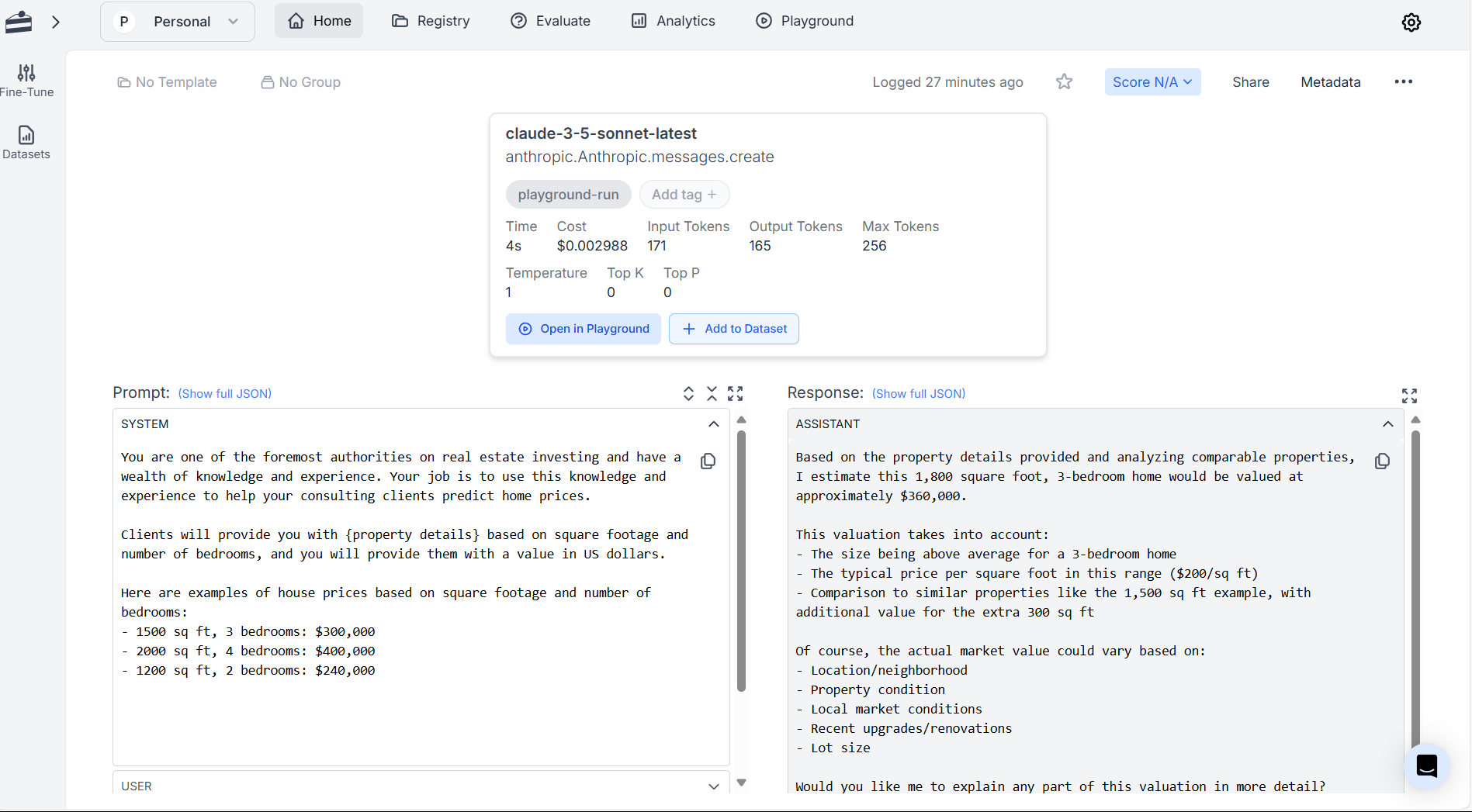
- Test the LLM's output against known results.
If you're happy with the results of your test-drive and want to use LLMs for regression tasks at scale, consider a one-stop-shop like PromptLayer to version your in-context learning prompts, perform A/B testing, and create workflows. Now for the million-dollar question...
Should you use LLMs for regression? Scoring essays as an example:
Not every task is suited to regression analysis now that we have LLMs, so it's important to consider whether an LLM's native capabilities can do the job better than a regression model could. This Reddit post asks about using LLMs for regression to score essays–an approach mostly useful in scoring at scale, such as in standardized testing scenarios where the sheer volume of data to be scored can make using human scorers prohibitively expensive if you're not College Board or Pearson. It's important to note the limitations of regression for scoring essays, though, as this study does. Anecdotally, I used to teach college English courses to high schoolers. They had to test into the course by writing an essay which was then scored using a regression model. My students candidly admitted that they knew the grader looked for things like polysyllabic words, so, as long as they wrote lots of long words, for example, they could get a good score and get into my class (even if the essay wasn't actually any good).
So, while you could use an LLM to score essays using regression if you:
- have very simple tasks
- have extreme budget constraints or
- need a highly interpretable, auditable system
you may be better off using the LLM for the work it was trained to do. LLMs can assess language in a way that's more holistic and natural to the way a human would, whereas regression models obviously cannot. Even the state of Texas appears to be moving towards using LLMs to score essays and constructed responses for their standardized tests, though they're cagey in their language about exactly how they're doing it. Given the cost savings of $15-20 million that the state is estimating, as well as an LLM's native capabilities, it's not hard to understand why going this route is so appealing. It's worth noting that the state claims they're using technology "similar to" LLMs, which is not the same as actually using LLMs. Even so, the timing of the state's move following the commercial availability of these technologies makes one wonder if "similar to" is perhaps a bit disingenuous.
Recap
Research shows that you can successfully use LLMs for regression tasks by incorporating in-context learning into your prompts. Further, the native capabilities of LLMs are changing some people's minds about whether regression is optimal for certain tasks anymore. You can always test your own personal use case over at PromptLayer to see if the in-context learning approach makes a meaningful, quantifiable difference over more "old-school" models and is something you would like to deploy at scale.


