How to Evaluate LLM Prompts Beyond Simple Use Cases

A common question we get is: "How can I evaluate my LLM application?" Teams often push off this question because there is not a clear answer or tool for them to use to address this challenge.
If you're doing classification or something that is programmatic like SQL queries, it's easy enough – you can compare against a ground truth. We call this Deterministic Evaluation. This is where your LLM output has a clear correct answer that can be objectively verified – like a SQL query that either returns the right data or doesn't. It's simple because you can automate testing and achieve near-perfect accuracy metrics.
But what about those messier, more realistic scenarios? How do you evaluate a customer support chatbot's empathy? Or measure if an LLM properly summarized a complex transcript? This Qualitative Evaluation challenge is what I'm going to share some thoughts about today.
Breaking Down the Problem
The first question we always ask customers is: can you break up the complex task into multiple subtasks that are easier to test? The decomposition transforms an unwieldy evaluation problem into manageable chunks.
For example, with a customer support chatbot, you might separate:
- Intent classification (what is the customer asking for?)
- Information retrieval (finding relevant product details)
- Response generation (crafting helpful, empathetic answers)
By decomposing the problem, you can apply more rigorous evaluation methods to each component. For a deeper dive into this approach, check out this blog post on prompt routers and modular prompt architecture by my co-founder Jared.
Two Key Evaluation Methods
Once you've broken down the problem as much as possible, you have two primary options:
1. Negative Examples
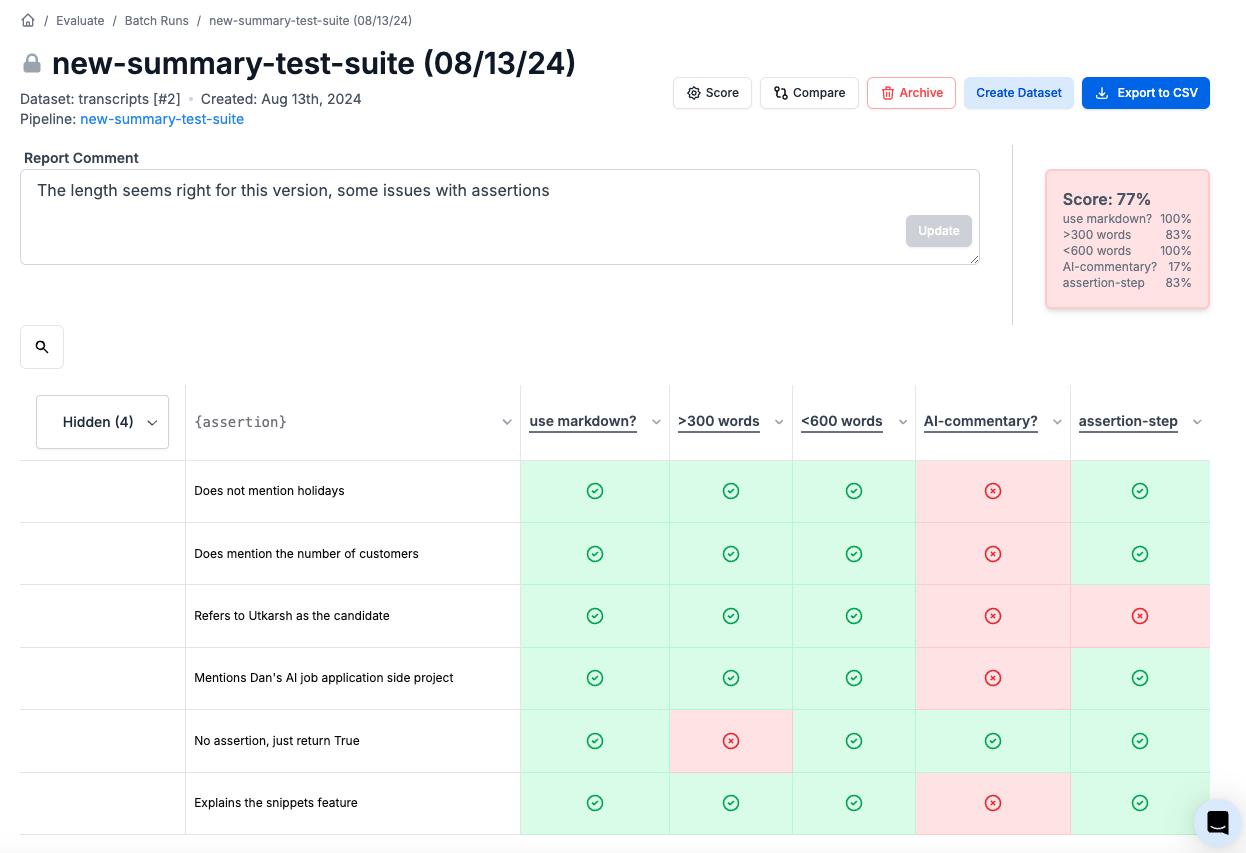
This approach is powerful but requires some investment. It involves cataloging failure modes where your model hallucinates or responds incorrectly, then creating assertions to test against these scenarios. At PromptLayer, we have an easy LLM assertion column type in our evaluations that lets you write assertions directly into a dataset.
For example, if your model sometimes forgets to mention key information like "Tim" from a call transcript, you might write an assertion: "Make sure Tim is mentioned in this response." Over time, you'll build hundreds of these assertions across dozens of inputs, creating a robust evaluation framework.
The beauty of negative examples is they ensure you don't regress – each new version of your system must pass previous failure cases. This creates a continuously improving system that learns from real production data.
2. LLM as a Judge Rubric
This approach requires you to be prescriptive. Your team must document all requirements for good responses, then create prompts or code blocks that test each requirement dimension.
This method can be challenging to align with business requirements. Without sufficient examples in your evaluation prompts, scores can fluctuate wildly and not reflect actual performance. Despite being commonly recommended, this approach often proves least useful unless meticulously constructed.
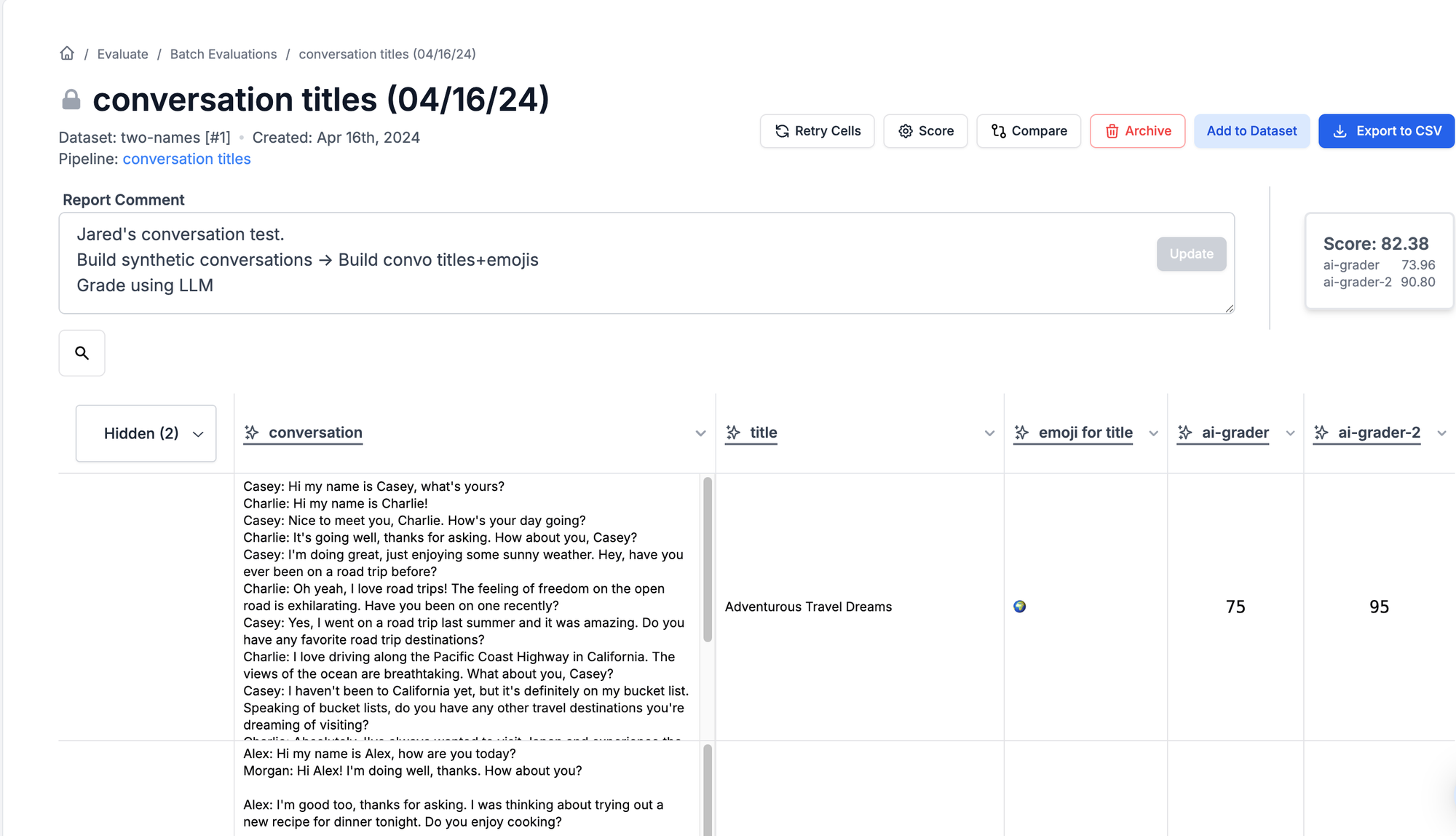
Bonus: Dialogue-based Evaluation
A common question we hear is about creating systems where AI evaluates itself through conversation. While this has its place, we recommend freezing conversations at specific points (using our placeholder feature for example) and evaluating those discrete steps, applying the methods above.
What This All Comes Down To
If you've read my Prompt Engineering Triangle article, you know that evaluation is a core component of building effective LLM applications. Product owners must clearly articulate expectations and requirements. With a clean, focused dataset and well-defined evaluation criteria, you'll create LLM applications that consistently deliver value.
Remember: all effective evaluation methods require investment. The more time you spend defining what "good" looks like, the better your LLM application will perform in the real world.
About PromptLayer
PromptLayer is a prompt management system that helps you iterate on prompts faster — further speeding up the development cycle! Use their prompt CMS to update a prompt, run evaluations, and deploy it to production in minutes. Check them out here. 🍰


