The emergence of Agent-First Software Design
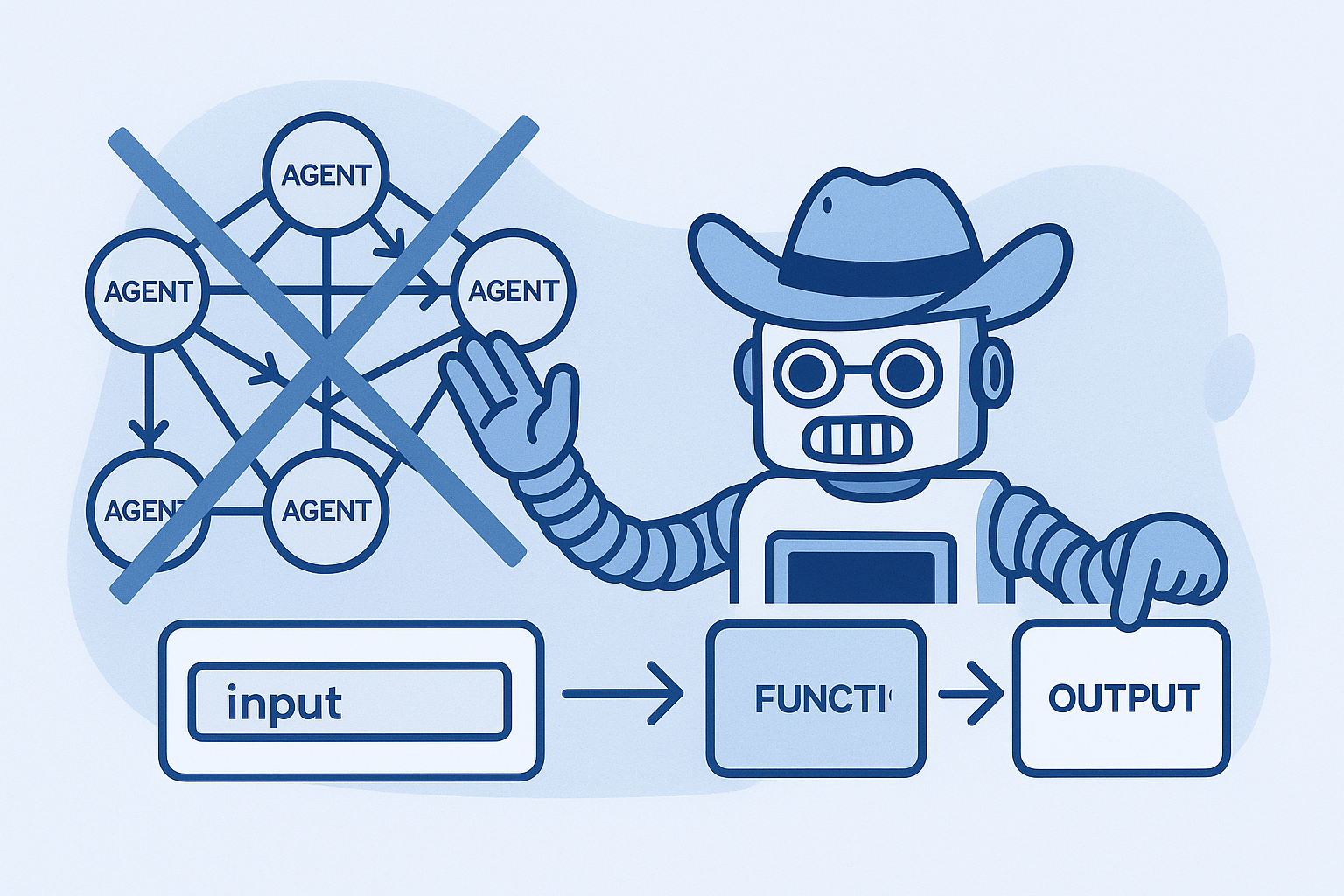
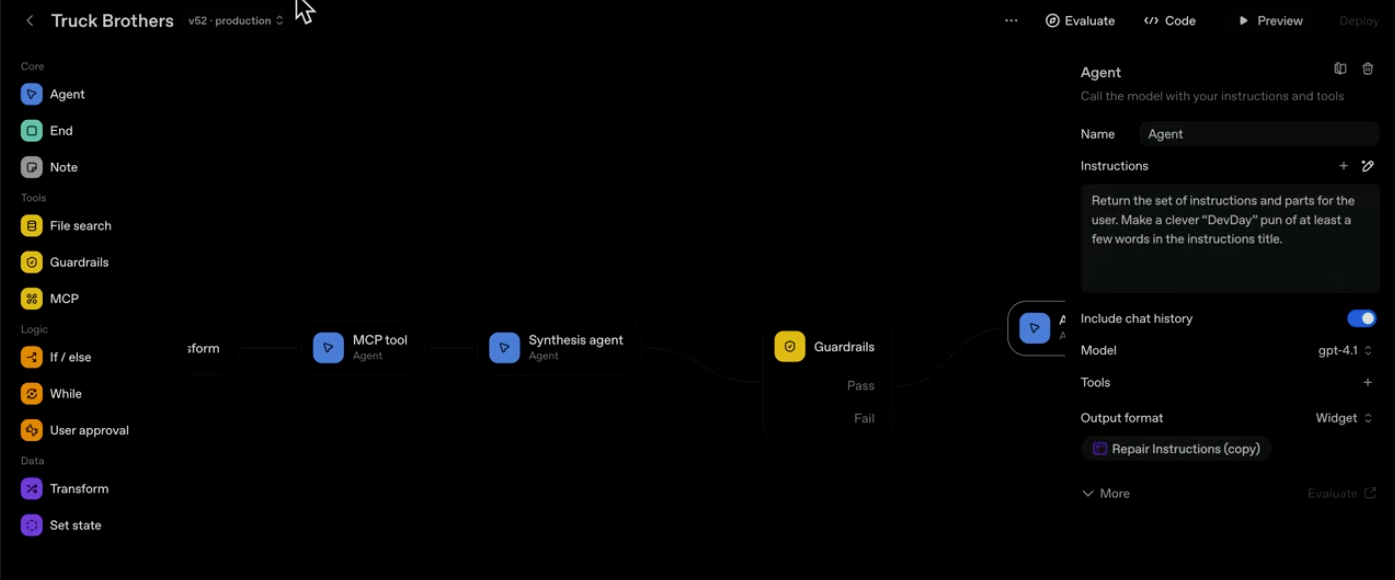
There's a shift happening in how we build software. For decades, programming meant writing explicit if/else decision trees. Parse this response. Handle this edge case. Chain these steps together. But a new paradigm is emerging where the job of the software engineer isn't to write