An analysis of OpenAI models: o1 vs GPT-4o

It’s been two weeks since OpenAI announced a new pair of flagship models: OpenAI o1 and o1 mini. These models build on the foundation laid by their GPT-4o predecessors.
The o1 and o1-mini models mark a significant advance in complex reasoning and problem-solving. They are designed to tackle some of the most challenging tasks across various fields.
In a comparison on the International Mathematics Olympiad (IMO) qualifying exam, GPT-4o managed to solve only 13% of the problems correctly, while the o1 model achieved an 83% success rate.
Let's dig into what these models are and an analysis of OpenAI o1 vs GPT-4o, as well as their counterparts OpenAI o1 mini vs GPT-4o mini.
o1 vs all LLMs
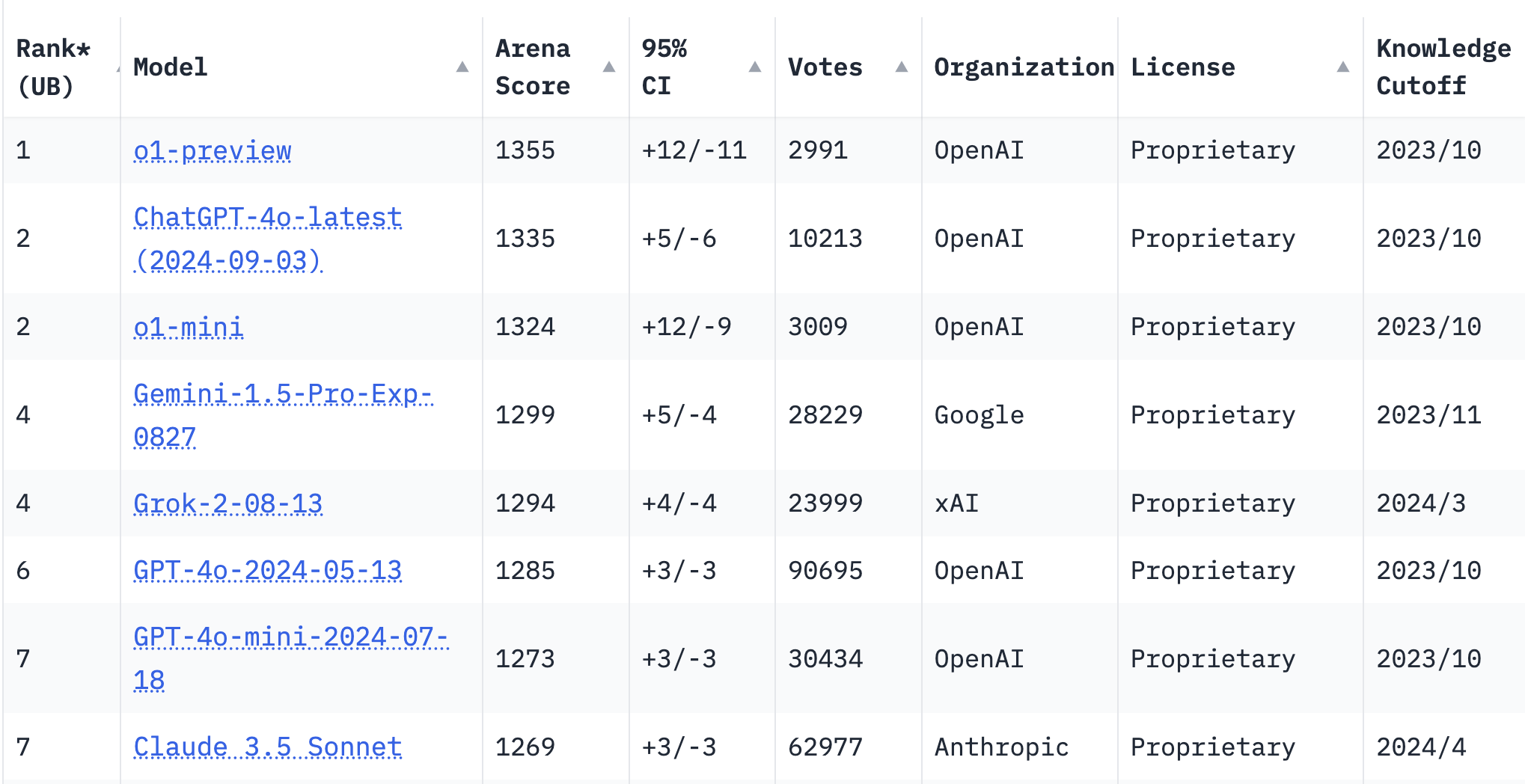
The LLM Arena leaderboard is the first place we look when a new model is released.
Its leaderboard showcases the performance rankings of different language models. They compare how a model scores across different benchmarks and tasks and give scores on how models perform. This can show you how a model stacks up against other models, in terms of capabilities and accuracy.
The o1-preview and o1-mini models rank first and third, respectively, on the leaderboard as of today.
How OpenAI o1 and o1 mini work
These models are trained to spend time thinking through problems before generating a response. This trained thought process is meant to mimic the ways humans solve problems. Specifically designed for complex reasoning tasks, OpenAI believes these models enable new capabilities not accessible by previous models.
The o1 models are not intended to be used for everyday tasks. OpenAI has specified they excel in the fields of science, coding, math, and the like.
How to access OpenAI o1 and o1 mini models
These models are currently labeled as an “early preview.” ChatGPT plus users and developers and access the models directly in ChatGPT or for their own products via the API. They currently lack access to web browsing, file and image uploading, and other available functions to models such as GPT-4o.
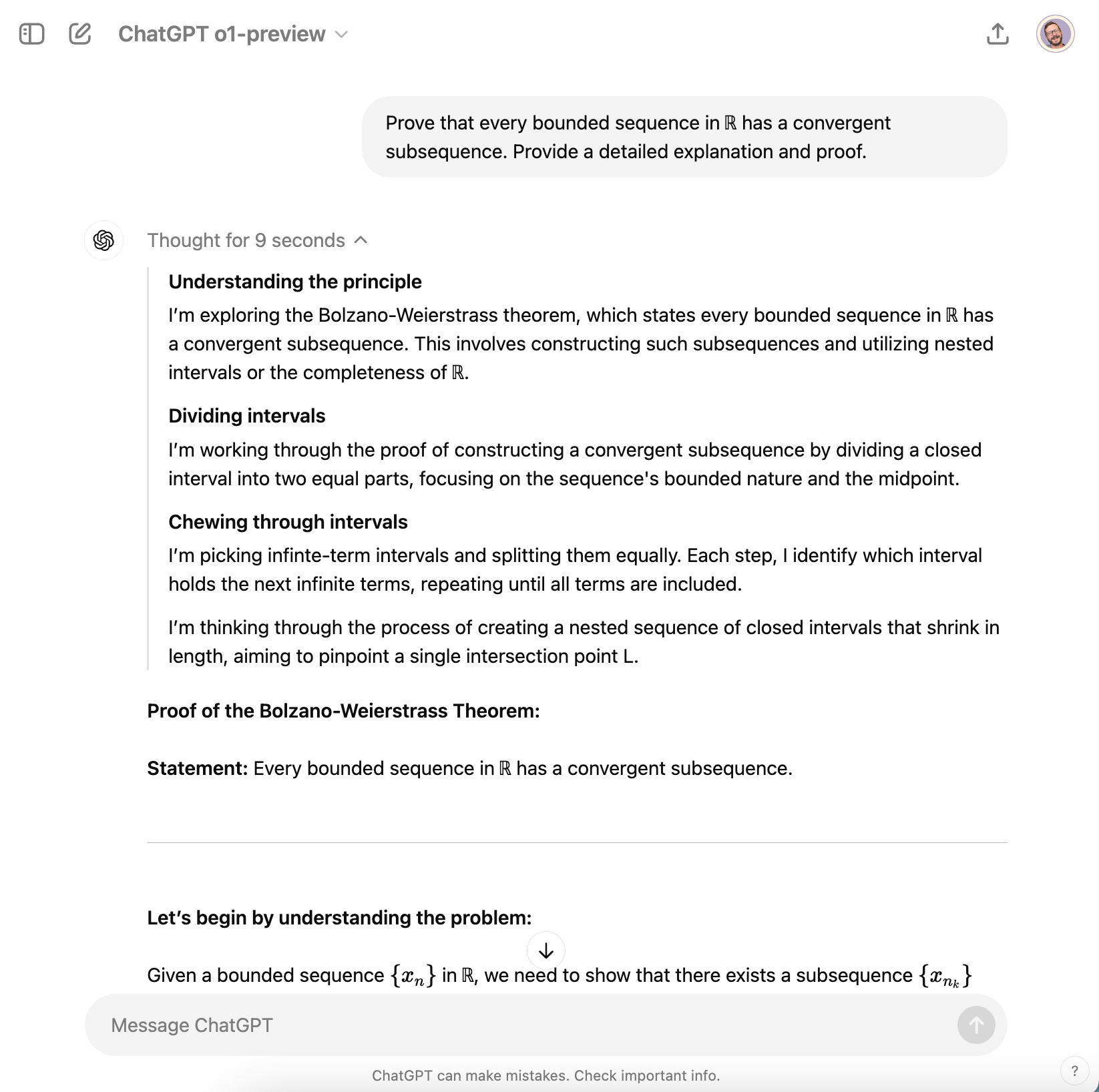
Access o1 and o1 mini in ChatGPT
To use these models in ChatGPT, first make sure you are a paid subscriber of ChatGPT Plus or ChatGPT for Teams.
- Step 1: Head to ChatGPT
- Step 2: Choose o1-preview or o1-mini from the dropdown menu
- Step 3: Submit a prompt that requires complex reasoning or thinking
Access o1 and o1 mini through the API
To use these models through the api, you must first have a developer account with Tier 4 access (at this time).
- Step 1: Visit platform.openai.com
- Step 2: Generate an API key with proper permissions
- Step 3: Make a call through the chat completions endpoint to either o1-preview or o1-mini
Current o1 and o1 mini limitations
There are beta limitations to using these models both in ChatGPT and the API.
- They are text input only
- User and assistant messages are supported. System messages are not yet supported.
- Streaming tokens are not supported.
- The Assistants API and Batch API are not supported.
- Tools, function calling, and response format parameters are not supported.
- Logprobs are not supported.
- Temperature, top_p and n are fixed at 1 and presence_penalty and frequency_penalty are fixed at 0.
OpenAI has indicated that support for some of these parameters may be added in the coming weeks as these models transition out of beta.
Comparing OpenAI o1 vs GPT-4o
To understand the differences in these models, let’s look at 4o’s costs, capabilities, specifications, and specializations for each model side-by-side with its o1 counterpart:
Cost comparisons: o1 vs GPT-4o and o1-mini vs GPT-4o-mini
| Model | Input Tokens Cost | Output Tokens Cost |
|---|---|---|
| o1 | $15 / 1M input tokens | $60 / 1M output tokens |
| o1 mini | $3 / 1M input tokens | $12 / 1M output tokens |
| gpt-4o | $5 / 1M input tokens | $15 / 1M output tokens |
| gpt-4o-mini | $0.15 / 1M input tokens | $0.6 / 1M output tokens |
*Please note that when using these models directly in ChatGPT, you are not charged per token. The cost analysis presented here pertains solely to API usage.
- Let's compare the increases in input and output tokens:
| Transition | Input Tokens Cost Increase | Output Tokens Cost Increase |
|---|---|---|
| GPT-4o to o1 | 200% increase (3× higher) | 300% increase (4× higher) |
| GPT-4o-mini to o1-mini | 1,900% increase (20× higher) | 1,900% increase (20× higher) |
- Now let's do an overall comparison of o1-preview and GPT-4o:
GPT-4o vs o1-preview: Overall comparison
| Model | GPT-4o | o1-preview |
|---|---|---|
| Model Description |
|
|
| Intelligence & Reasoning |
|
|
| Internal Reasoning Process |
|
|
| Speed |
|
|
| Cost |
|
|
| Multimodality |
|
|
| Specializations |
|
|
| Context Window |
|
|
| Max Output Tokens |
|
|
| Training Data |
|
|
| Ideal Use Cases |
|
|
- Now, an overall comparison of the smaller o1-mini and GPT-4o-mini:
GPT-4o-mini and o1-mini: Overall comparison
| Model | GPT-4o-mini | o1-mini |
|---|---|---|
| Model Description |
|
|
| Intelligence & Reasoning |
|
|
| Internal Reasoning Process |
|
|
| Speed |
|
|
| Cost |
|
|
| Multimodality |
|
|
| Specializations |
|
|
| Context Window |
|
|
| Max Output Tokens |
|
|
| Training Data |
|
|
| Ideal Use Cases |
|
|
- Here is a breakdown of differences between to two pairs of models:
OpenAI o1 vs GPT 4o: Key Differences
| Model | GPT-4o Series | o1 Series |
|---|---|---|
| Primary Focus |
|
|
| Multimodal Support |
|
|
| Speed and Cost |
|
|
| Ideal For |
|
|
| Max Output Tokens |
|
|
When to use GPT-4o and OpenAI o1
While GPT-4o is optimized for general applications with rapid response times and multimodal support, the o1 series is optimized for tasks demanding intensive cognitive processing and extensive output capacities.
The GPT-4o series is designed for high efficiency and multimodal capabilities, including text and image inputs, making it ideal for applications that require speed, cost-effectiveness, and diverse functionalities.
The o1 series, in contrast, is focused on complex reasoning and problem-solving with specialized internal thought processes. It supports higher token limits specifically suited for deep reasoning tasks like coding, mathematics, and scientific research.
OpenAI's o1 and o1-mini models excel in complex reasoning tasks but come at a higher cost than the more efficient and cost-effective GPT-4o series. Take into account the capabilities and cost trade-offs to decide which model to use based on your needs.
Example prompts analyzing performance of OpenAI o1 vs GPT-4o
Let's look over some example prompts that highlight the complex reasoning abilities of o1-preview.
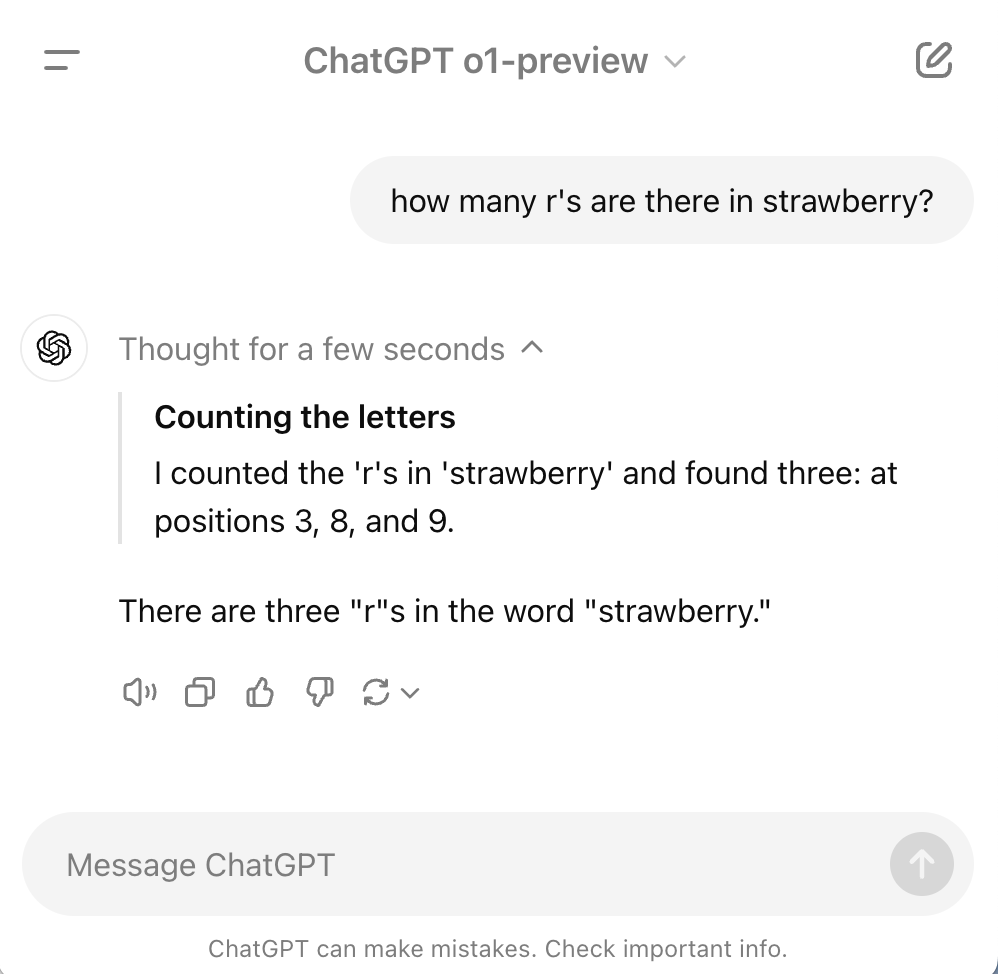
1. The 'Strawberry' test
Prompt:
How many r's are there in strawberry?
Explanation:
This is a simple evaluation used to assess the ability of LLMs to perform basic character-level task. While language models excel at generating text based on patterns they've learned, they can struggle with precise, low-level operations like counting individual letters.
How o1 responds:
How GPT-4o responds:
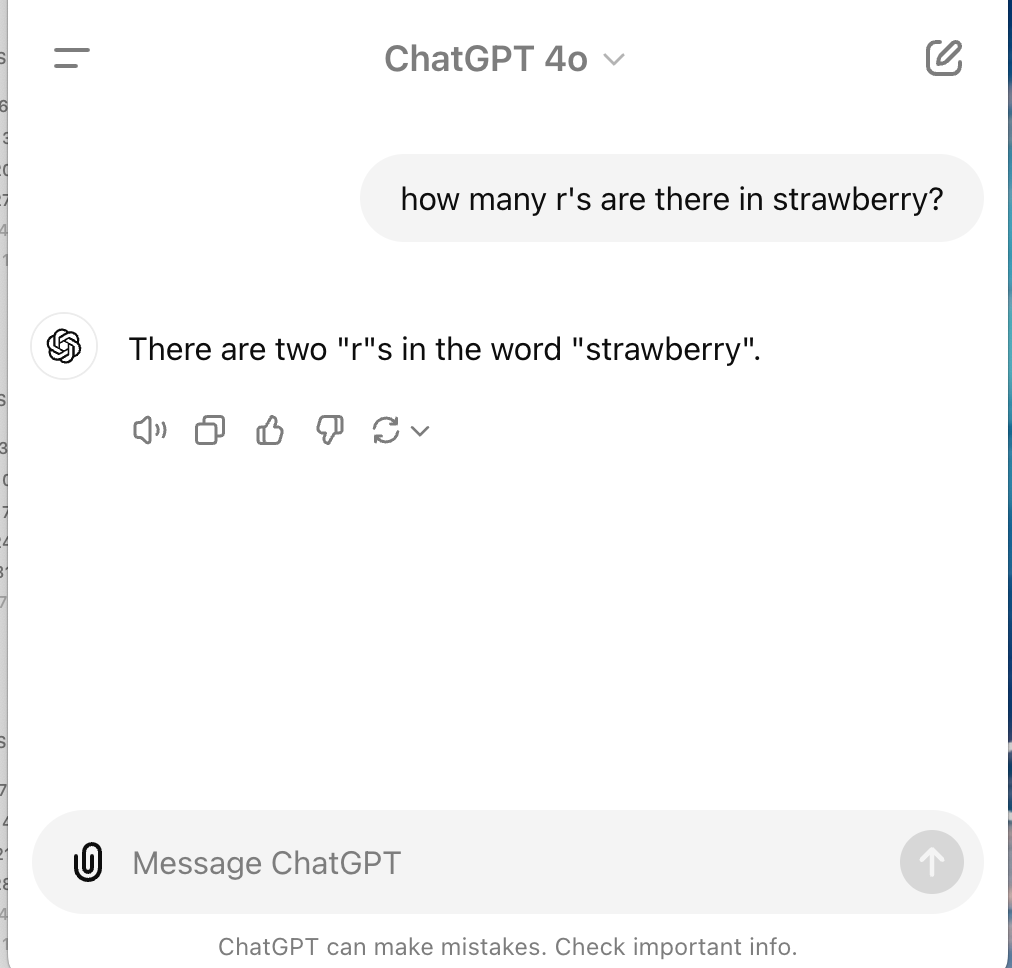
The o1 model systematically examines each character, ensuring precise results. In contrast, GPT-4o, optimized for efficiency and speed, provides a quick but less accurate answer by not fully engaging in the processing needed for exact counting of the letters.
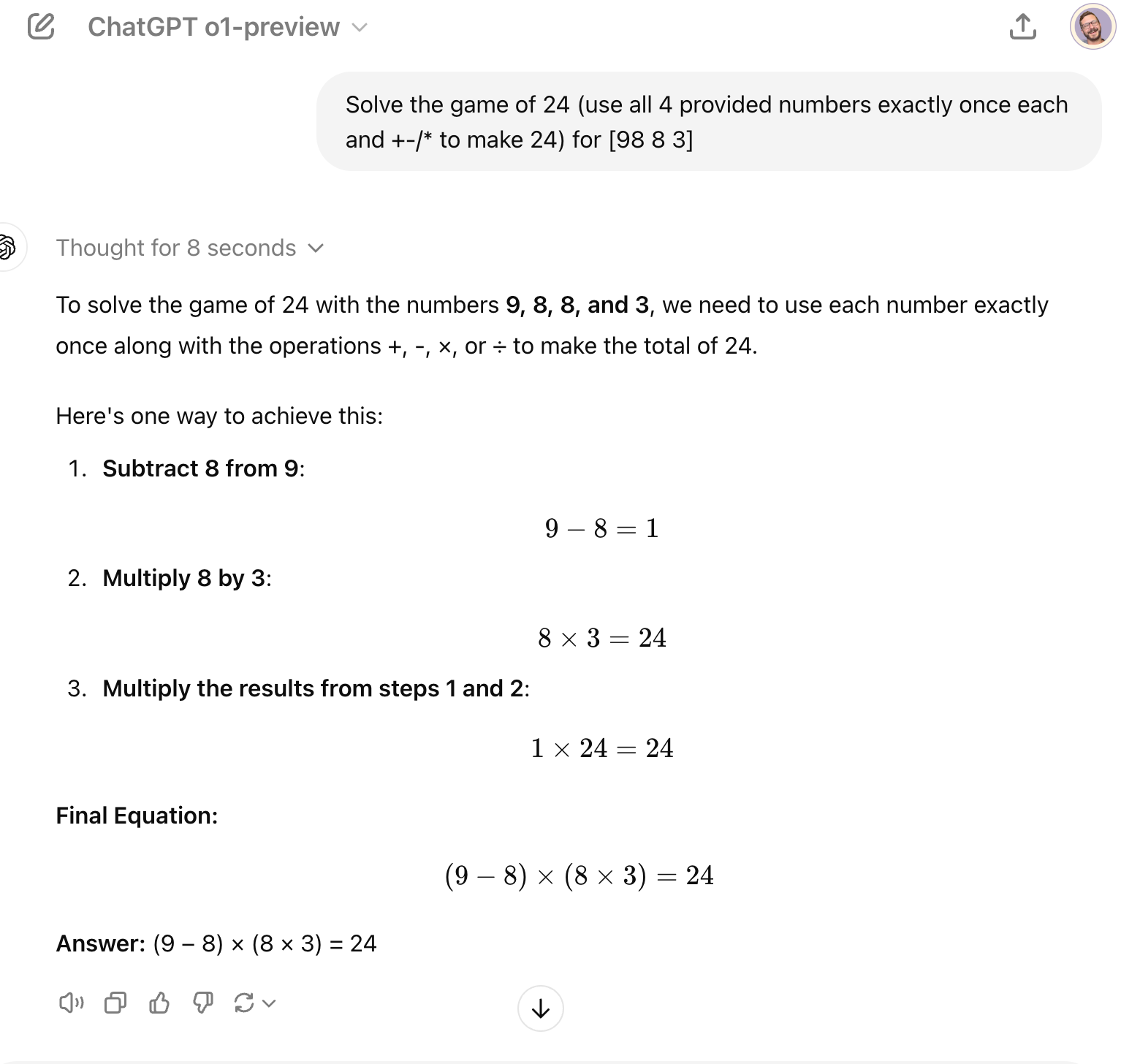
3. Math puzzles
Prompt:
Solve the game of 24 (use all 4 provided numbers exactly once each and +-/* to make 24) for [9 8 8 3]
Explanation:
This a mathematical puzzle that challenges the models to use all four numbers exactly once, combining them with basic arithmetic operations (addition, subtraction, multiplication, division) to reach the total of 24.
It serves as an example to illustrate the difference in how these models handle complex reasoning and problem-solving tasks.
How o1 responds:
How GPT-4o responds:

The o1 model outperforms GPT-4o in this mathematical puzzle by breaking down the process and thinking for 8 seconds before responding. It systematically explores possible solutions then provides a step-by-step solution that can be easily followed and verified.
GPT-4o lacks the reasoning process and cognitive capability needed for such puzzles and prioritizes a faster response, but not accurate, response.
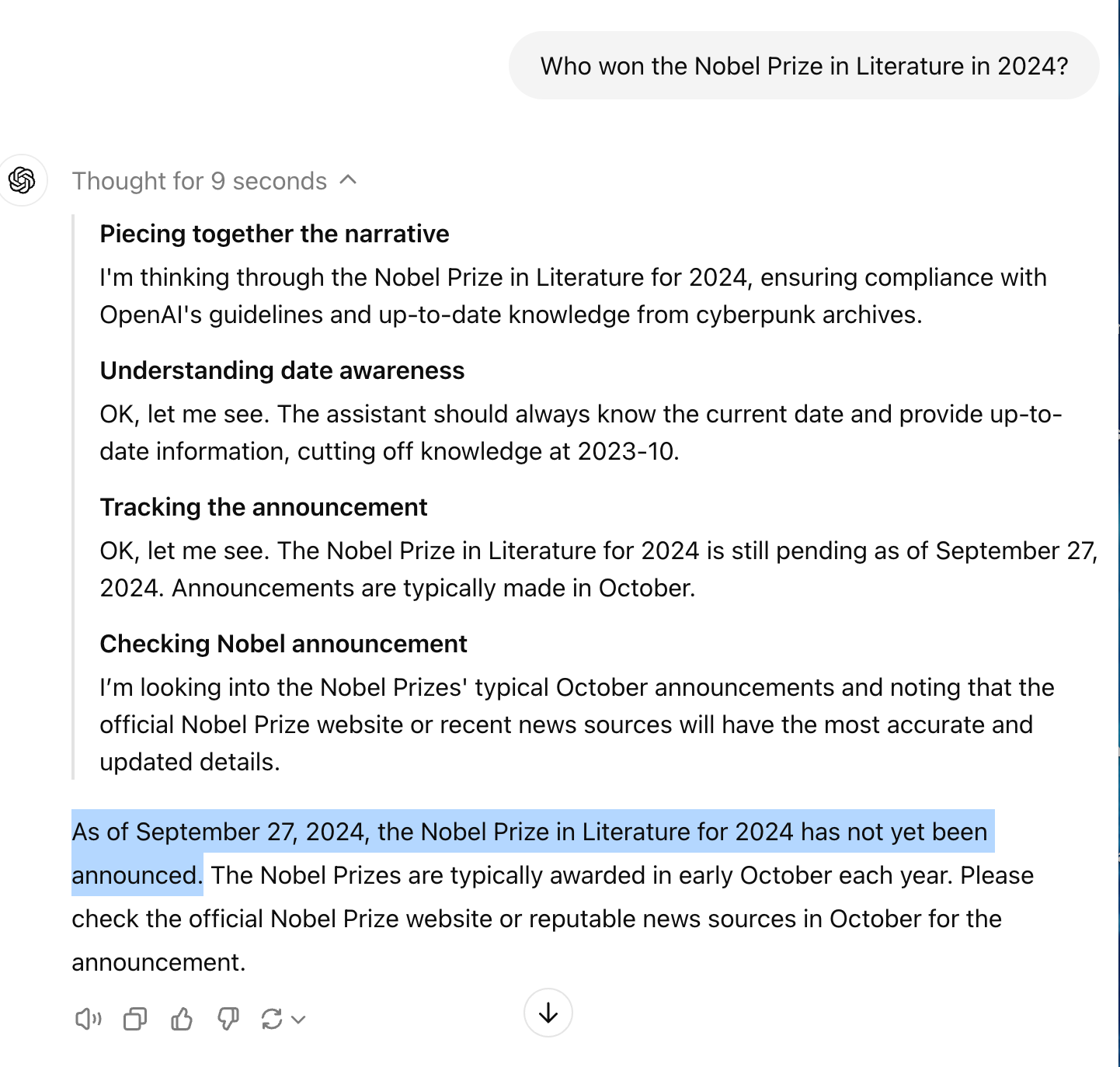
3. Up-to-date Information
Prompt:
Who won the Nobel Prize in Literature in 2024?
Explanation:
OpenAI o1 has access to information up to today's current date and GPT-4o isn't aware of events after it's last update. It does have access to browsing, but may be speculative and make wrong assumptions.
As of today, September 27, 2024, the Nobel Prize in Literature for 2024 has not yet been announced and will be in early October.
How o1 responds:
How GPT-4o responds:
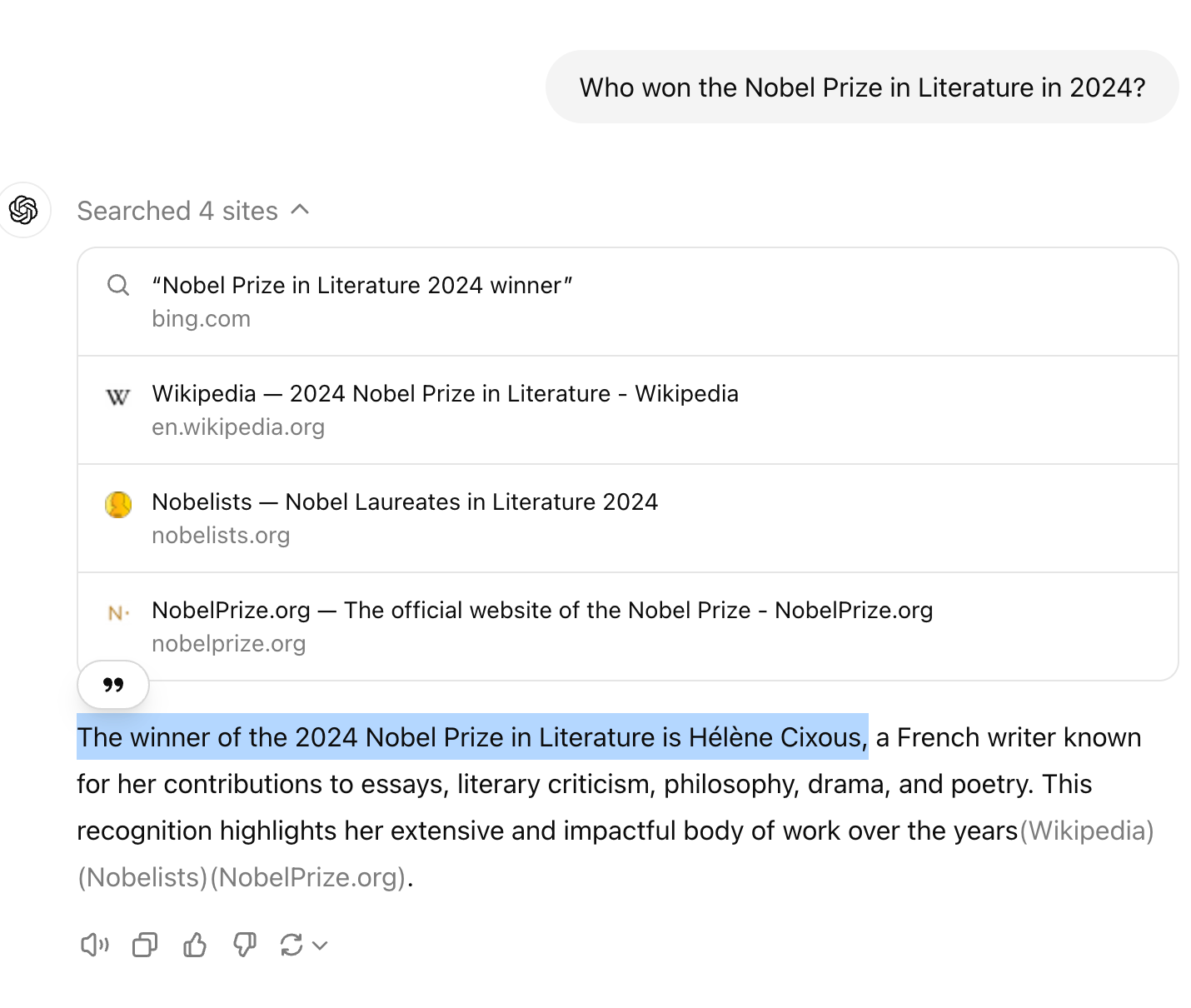
The knowledge cutoff for GPT-4o is September 2021. When asked about future events or information it doesn't possess, GPT-4o can attempt to generate a plausible answer based on patterns and probabilities learned during training.
O1 can access information up to today's date. This means it will think through and the scenario and know that the Nobel Prize in Literature for 2024 has not yet been announced.
In short, GPT-4o may speculate on current and future events where o1 can access current information and think through what that means for the future rather than speculating based on it's training.
4. Complex Mathematical Problem Solving
Prompt:
Prove that every bounded sequence in ℝ has a convergent subsequence. Provide a detailed explanation and proof.
Explanation:
This prompt requires the model to recall and articulate the Bolzano-Weierstrass Theorem, involving advanced mathematical reasoning and the construction of a formal proof. The o1 model, optimized for deep reasoning and higher token limits, can provide a comprehensive step-by-step proof, whereas GPT-4o might offer a more concise or less detailed response due to its optimization for efficiency.
How o1 responds:

How GPT-4o responds:

The o1 model is optimized for intensive cognitive processing and has higher token limits. This allows it to deliver detailed, step-by-step proofs and explanations required for advanced mathematical concepts.
In contrast, GPT-4o is designed for efficiency and may offer shorter, less detailed answers that might not fully address the complexity of advanced mathematical problems.
5. Advanced Coding Tasks
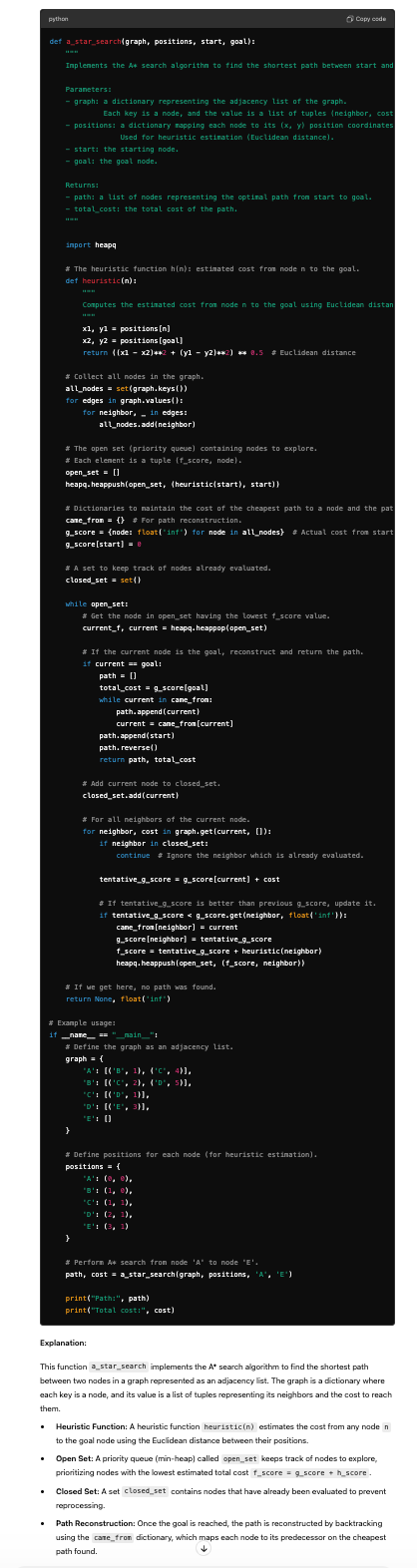
Prompt:
Write a Python function that implements the A (A-star) search algorithm to find the shortest path between two nodes in a graph. The function should handle graphs represented as adjacency lists, include an appropriate heuristic for estimating distances, and return both the optimal path and its total cost. Provide explanations and comments within your code.*
Explanation:
This task requires the implementation of the A* search algorithm, which combines features of Dijkstra's algorithm and heuristic-guided search. It involves complex data structures like priority queues, understanding of graph theory, and the application of heuristics to guide the search efficiently. The o1 model, optimized for intensive cognitive processing and extensive outputs, can generate accurate and well-documented code that correctly implements the algorithm. It can also provide detailed explanations of how the heuristic influences the search process and ensures optimality.
How o1 responds:

How GPT-4o responds:
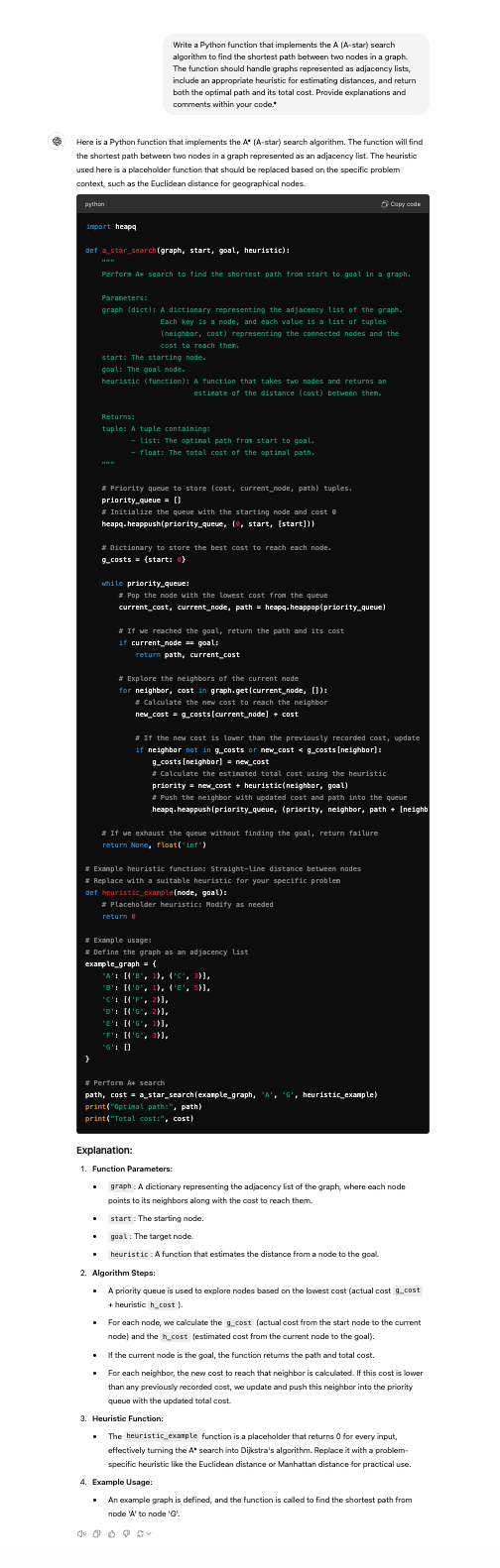
For advanced coding tasks, the o1 model excels due to its capacity for deep reasoning and extensive output capabilities.
It can generate accurate, well-structured code for complex algorithms, include detailed comments, and explain the logic and time complexity behind the solution. This makes it highly suitable for sophisticated programming challenges.
GPT-4o, being optimized for general applications and efficiency, may not provide code that is as detailed or accurate, and might lack thorough explanations, making it less effective.
About PromptLayer
PromptLayer is a prompt management system that helps you iterate on prompts faster — further speeding up the development cycle! Use their prompt CMS to update a prompt, run evaluations, and deploy it to production in minutes. Check them out here. 🍰


